Intro
I was building some infrastucture around automated speedtest.net tests using speedtest-cli. I noticed the assigned servers keep changing, some servers are categorized as malicious sources, some time out if tested on the hour and half-hour, and results are inconsistent depending on which server you get.
So, I saw that the speedtest-cli (linux command-line python script) has a switch for a “mini” server. When I investigated that seemed the answer to the problem – you can set up your own mini server and use that for yuor tests. I.e., control both ends of the test. great.
The speedtest.net mini server was discontinued in 2017! There’s some commercial replacement. So I thought. Forget that. I was disillusioned and then happened upon a breath of fresh air – an open source alternative to speedtest.net. Enter, librespeed.
Some details
librespeed has a command-line program whih is an obvious rip-off of speedtest-cli. In fact it is called librespeed-cli and has many similar switches.
There is also a server setup. Really, just a few files you can put on any apache + php web server. There is a web GUI as well, but in fact I am not even that interested in that. And you don’t need to set it up at all.
What I like is that with the appropriate switches supplied to librespeed-cli, I can have it run against my own librespeed server. In some testing configurations I was getting 500 Mbps downloads. Under less favorable circumstances, much less.
Testing, testing, testing
I tested between Europe and the US. I tested through a proxy. I tested from the Azure cloud to an Amazon AWS server. I tested with a single cpu linux server (good old drjohnstechtakl.com) either as server, or as the client. This was all possible because I had full control over both ends.
Some tips
- Play with the speedtest-cli switches. See what works for you. librespeed-cli -h will shows you all the options.
- Increasing the stream count can compensate for slower PING times (assuming both ends have a fast connection)
- It does support proxy, but
- Downloads don’t really work through proxy if the server is only running http
- Counterintuitively, the cpu burden is on the client, not the server! My servers didn’t show the slightest bit of resource usage.
- Corollary to 5. My 4-cpu client to 1-cpu server test was much faster than the other way around where server and client roles were reversed.
- Most things aren’t sensitive to upload speeds anyway so seriously consider suppressing that test with the appropriate switch. Your tests will also run a lot faster (18 seconds versus 40 seconds).
- Worried about consuming too much bandwidth and transferring too much data? I also developed a solution for that (will be my next blog post)
- So I am running a librespeed server on my little VM on Amazon AWS but I can’t make it public for fear of getting overrun.
- ISPs that have excellent interconnects such as the various cloud providers are probably going to give the best results
- It is not true your web server needs write access to its directory in my experience. As long as you don’t care about sharing telemetry data and all that.
- To emphasize, they supply the speedtest-cli binary, pre-built, for a whole slew of OSes. You do not and should not compile it yourself. For a standard linux VM you will want the binary called librespeed-cli_1.0.9_linux_386.tar.gz
Example files
The point of these files is to test librespeed-cli, from the directory where you copied it to, against your own librespeed server.
json-ns6
[{
"name":"ns6, Germany (active-servers)",
"server":"https://ns6.drjohnstechtalk.com/",
"id":864,
"dlURL":"backend/garbage.php",
"ulURL":"backend/empty.php",
"pingURL":"backend/empty.php",
"getIpURL":"backend/getIP.php",
"sponsorName":"/dev/null/v",
"sponsorURL":"https://dev.nul.lv/"
}]
wrapper.sh
#!/bin/sh
# see ./librespeed-cli -help for all the options
./librespeed-cli --local-json json-ns6 --server 864 --simple --no-upload --no-icmp --ipv4 --concurrent 4 --skip-cert-verify
Purpose: are we getting good speeds?
My purpose in what I am constructing is to verify we are getting good download speeds. I am not trying to hit it out of the park. That consumes (read, wastes) a lot of resources. I am targeting to prove we can achieve about 150 Mbps downloads. I don’t know anyone who can point to 150 Mbps and honestly say that’s insufficient for them. For some setups that may take four simultaneous streams, for others six. But it is definitely achievable. By not going crazy we are saving a lot of data transfers. AWS charges me for my network usage. So a six stream download test at 150 Mbps (Megabits per second) consumes about 325 MBytes download data. If you’re not being careful with your switches, you can easily nudge that up to 1 GB downloads for a single test.
My librespeed client to server tests ran overnight alongside my old approach using speedtest. The speedtest results are all over the place, with a bunch of zeroes for whatever reason, as is typical, while librespeed – and mind you this is from a client in the US, going through a proxy, to a server in Europe – produced much more consistent results. In one case where the normal value was 130 mbps, it dipped down to 110 mbps.
Testing it out at home
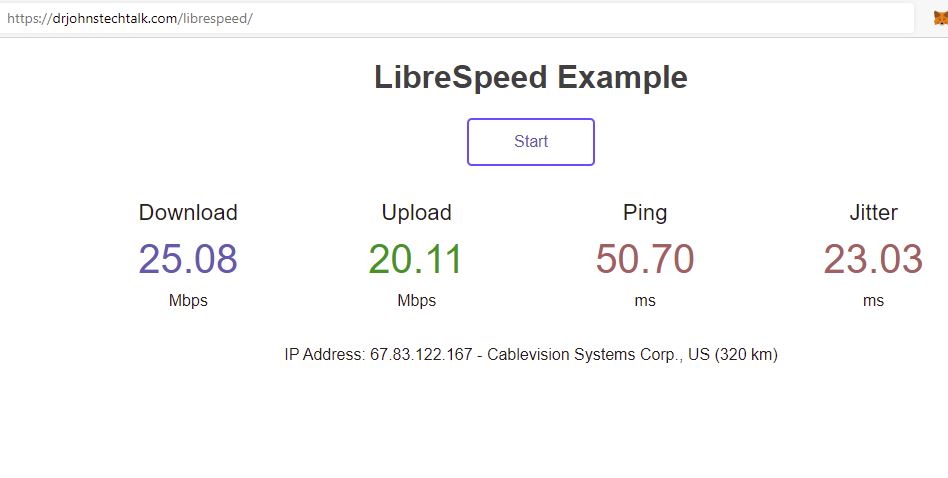
I made my test URL on my AWS server private, but a public one is available at https://librespeed.de/
At home of course I want to test with a Raspberry Pi since I work with them so much. There is indeed a pre-built binary for Raspberry Pi. It is https://github.com/librespeed/speedtest-cli/releases/download/v1.0.9/librespeed-cli_1.0.9_linux_armv7.tar.gz
The problem with speedtest in more detail
There were two final issues with speedtest that were the straws that broke the camel’s back, and they are closely related.
When you resolve www.speedtest.net it hits a Content Distribution Network (CDN), and the returned results vary. For instance right now we get:
;; QUESTION SECTION: ;www.speedtest.net. IN A ;; ANSWER SECTION: www.speedtest.net. 4301 IN CNAME zd.map.fastly.net. zd.map.fastly.net. 9 IN A 151.101.66.219 zd.map.fastly.net. 9 IN A 151.101.194.219 zd.map.fastly.net. 9 IN A 151.101.2.219 zd.map.fastly.net. 9 IN A 151.101.130.219
Note that you can also run speedtest-cli with the –list switch to get a list of speedtest servers. So in my case I found some servers which procuced good results. There was one where I even know the guy who runs the ISP and know he does an excellent job. His speedtest server is 15 miles away. But, in its infinite wisdom, speedtest sometimes thinks my server is in Lousiana, and other times thinks it’s in New Jersey! So the returned server list is completely different for the two cases. And, even though each server gets assigned a unique number, and you can specify that number with the –server switch, it won’t run the test if that particular server wasn’t proposed to you in its initial listing. (It always makes a server listing call whether you specified –list or not, for its own purposes as to which servers to use.)
I tried to use some of tricks to override this behaviour, but short of re-writing the whole thing, it was not going to work. I imagined I could force speedtest-cli to always use a particular IP address, overwriting the return from the fastly results, but getting that to work through proxy was not feasible. On the other hand if you suck it up and accept their randomly assigned server, you have to put up with a lot of garbage results.
So set up your own server, right? The –mini switch seems built to accommodate that. But the mini server was discontinued in 2017. The commercial replacement seemed to have some limits. So it’s dead end upon dead end with speedtest.net.
Conclusion
An open source alternative to speedtest.net’s speedtest-cli has been identified and tested, both server and client. It is librespeed. It gives you a lot more control than speedtest, if that is your thing and you know a smidgeon of linux.
References and related
(2024 update) Cloudflare has a really nice speed test without all the bloat: https://speed.cloudflare.com/
Just to do your own test with your browser the way you do with speedtest.net: https://librespeed.de/
librespeed-cli: https://github.com/librespeed/speedtest-cli
librespeed-cli binaries download page: https://github.com/librespeed/speedtest-cli/releases
RPi version of librespeed-cli: https://github.com/librespeed/speedtest-cli/releases/download/v1.0.9/librespeed-cli_1.0.9_linux_armv7.tar.gz
The RPi I use for automatically power cycling my cable modem is hard-wired to my router and makes for an excellent platform from which to conduct these speedtests.
librespeed server: https://github.com/librespeed/speedtest . You basically can git clone it (just a bunch of js and php files) from: https://github.com/librespeed/speedtest.git
If, in spite of every positive thing I’ve had to say about librespeed, you still want to try the more commercial speedtest-cli, here is that link: https://www.speedtest.net/apps/cli
In this context a lot of people feel iperf is also worth exploring. I think it is a built-in linux command.
To kick it up a notch for professional-class bandwidth and availability measurements, ThousandEyes is the way to go. This discussion is very enlightening: https://www.thousandeyes.com/blog/caveats-of-traditional-network-tools-iperf