Skip to the content
Search
Dr John's Tech Talk
Technical Discussion of Internet Infrastructure
Menu
Home
Blog
Python network diagram generator
Blur images with Python
Everything I need to know about Influxdb, Grafana and Flux
Raspberry Pi photo frame using the pictures on your Google Drive II
My favorite Python tips
The IT Detective Agency: This site can’t be reached
Starlink Internet service: a first look: UPDATED
Securing a sensitive variable in Azure DevOps
Azure DevOps: use the api to copy logs to linux
Interpreting speech with a Raspberry Pi
Checkpoint Gaia admin tips
Install WSL2 for Windows 10 Home Edition: not as easy as they say, but not impossible either, and definitely worth it, plus tips for Windows 11
ADO: Check pipeline runs
Consumer Tech: Warning: Windows 11 wipes out Mediatek Wireless driver
Consumer Tech: How I fixed my Samsung Galaxy A51 Black Screen of Death
Cloudflare DNS: using the python api
Cloudflare: an added layer of protection for your personal web site
The IT Detective Agency: the case of the mysterious ICMP host administratively prohibited packets
Trying to improve my home WiFi with a range extender
Consumer tech: fixing my Acurite electronic rain rauge
Ping sweep for network security engineers
Consumer Tech: how to unfreeze a frozen iPhone screen
Multiple Raspberry Pi photo frames
My favorite bash scripting tips
Your AWS Instance was scheduled for retirement? don’t panic
Raspberry Pi light sensor project
How an ADO pipeline can modify its own repo
drjohnstechtalk now runs on a modern OS
What happened to insert mode on the latest version of vi?
Azure DevOps: how to run python in a virtual environment
Types of Cyberattacks and other terms from the world of cyber security
Consumer Tech: Setting up an Echo Dot while staying at a hotel
Search
Home
Pergola endplate design
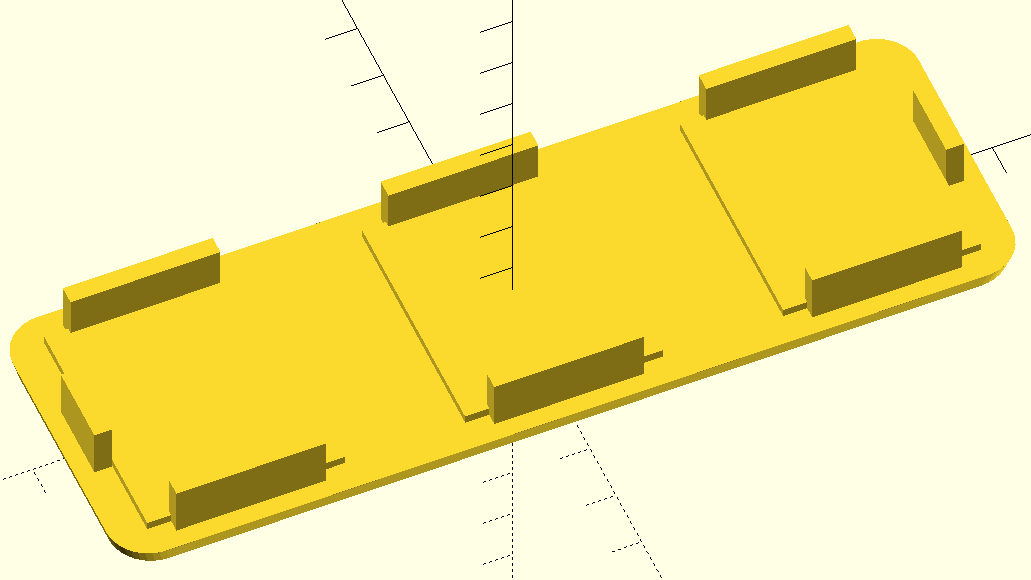 Pergola endplate design
Pergola endplate design