Intro
I’ve been reliable running ISC’s BIND server for eons. Recently I had a problem getting my slave servers updated after a change to the primary master. What was going on there?
The details
This was truly a team effort. I saw that the zone file had differing serial numbers on the master versus the slave servers. My attempts to update via an rndc refresh zone was having no effect.
So I tried a zone transfer by hand: dig axfr drjohnstechtalk.com @50.17.188.196
That timed out!
Yet, regular dns qeuries went through fine: dig ns drjohnstechtakl.com @50.17.188.196
I thought about it and remembered zone transfers use TCP whereas standard queries use UDP. So I tried a TCP-based simple query: dig +tcp ns drjohnstechtalk.com @50.17.188.196. It timed out!
So of course one suspects the firewall, which is reasonable enough. And when I looked at the firewal I found some funny drops, though i cuoldn’t line them up exactly with my failed tests. But I’m not a firewall expert; I just muddle through.
The next day someone from the DNS group asked how local queries behaved? Hmm. never tried that. So I tried it: dig +tcp ns drjohnstechtalk.com @localhost. That timed out as well! That was a brilliant suggestion as we now could eliminate the firewall and all that complexity from the equation. Because I had tried to do packet traces on two different machines at the same time and line up the results. It wasn’t easy.
The whole issue was very concerning to us because we feared our secondaries would be unable to pudate their slave zones and ultimately time them out. The result would be devastating.
We have support, fortunately. A company that hearkens frmo the good old days, with real subject matter experts. But they’re extremely busy. We did not get a suggestion for a couple weeks. But eventually we did. They had seen this once before.
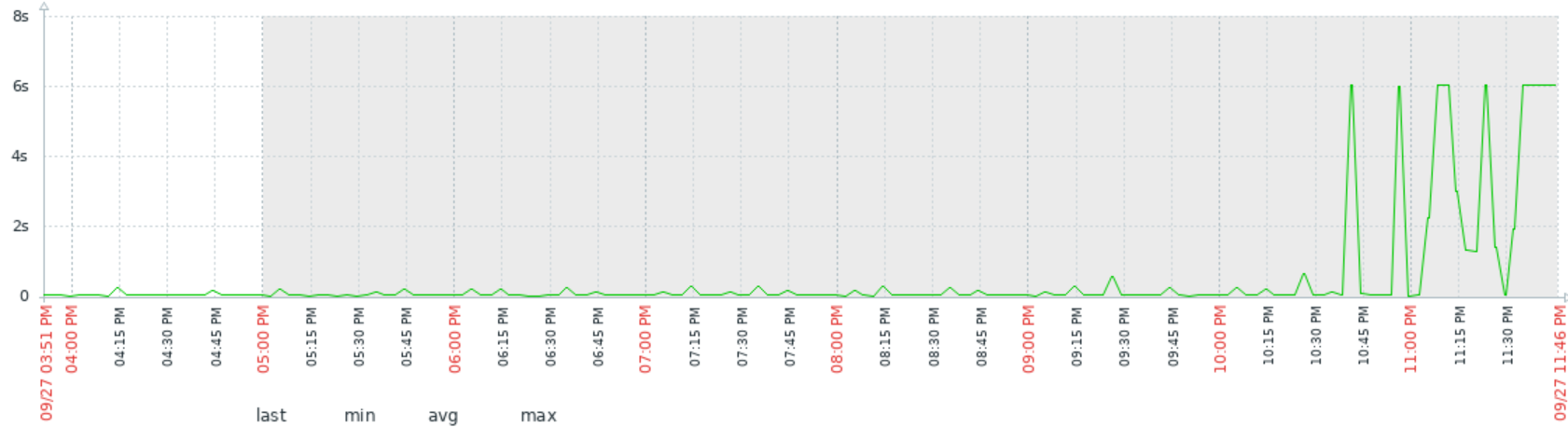
The above graph is from a Zabbix monitor showing how long it takes that dns server to respond to that simple query. 6 s is a time-out. I actually set dig to timeout at 2 s, but in wall-clock time it actually takes 6 s.
The fix
We removed this line from the options block of named.conf:
keep-response-order {any; };
The info fmo the experts is that most likely that was configured as a workaround to CVE-2019-6477 but that issue was fixed since 9.15.6.
Conclusion
We encountered the named daemon in a situation where it was unable to respond to TCP-based DNS queries and hence unable to do zone transfers. So although most queries use UDP, this was a serious issue for us and prevented zones from being updated on all authoritative nameservers.
As is the case with so many modern IT problems, the effect was not black or white. Failures were intermittent, and then permanent. A restart fixed ths issue (forgot to mention so far!). But we involved an expert to find the root cause and it was the presence of a single configuration line in our named.conf. After removing that all was good.