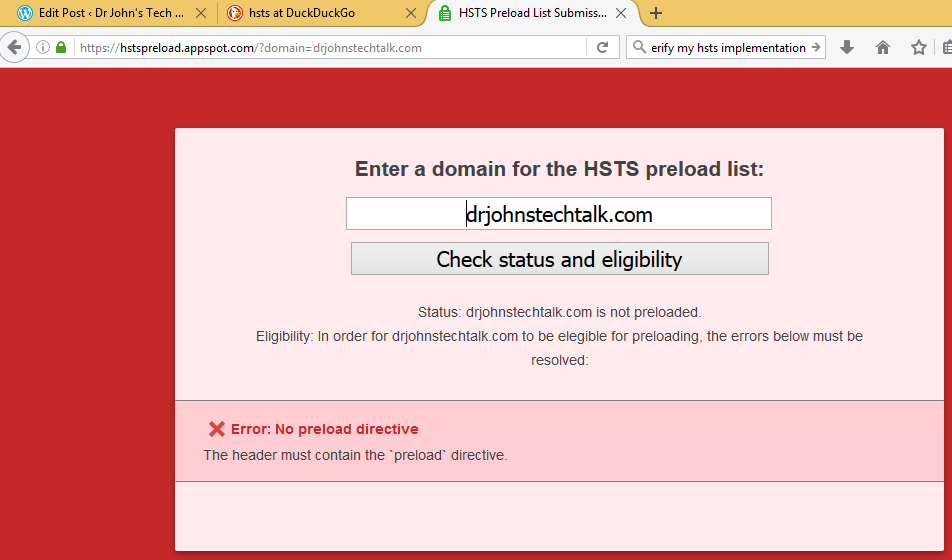
Intro
I am treating my blog as a public service, so I thought it would be appropriate to have a Donation link even though I have not incorporated as a 501c3 non-profit. Is it even possible? Can I keep my anonymity? These were concerns I raised in my head and ones for which there is no good guidance. Short answer: Yes and Yes.
The details
The link to PayPal’s Donate button creation page is pretty well documented. That’s here. Needless to say, you need a PayPal account first!
The PayPal site walks you through a few options. Since Donate is so often associated with not-for-profits I wanted a different word on the button, like Contribute. But customizing the wording was not one of their offered options.
And this is important: you don’t seem to be able to get out of revealing your PayPal email address. It will appear on your Donation page. So what to do?
Well your PayPal account can have up to eight email addresses associated with it. So in my case where the DNS for drjohnstechtalk.com is hosted by GoDaddy (not the web site, mind you, just the DNS), I simply need to set up an arbitrary address like drjohn At drjohnstechtalk DOT com and have it forward to my personal Gmail account. That’s simple enough with GoDaddy’s service, and they don’t even charge extra! Then back to PayPal where you add that address to your account, receive a confirmatory email that they generate, and confirm using their emailed link.
That’s about it. Now you can go back to the button creation page, call it a Donate button, put in your anonymous email address, and let it generate the HTML code. The HTML code is pretty simple and it can be pasted right into a WordPress page if you use or switch to HTML editing.
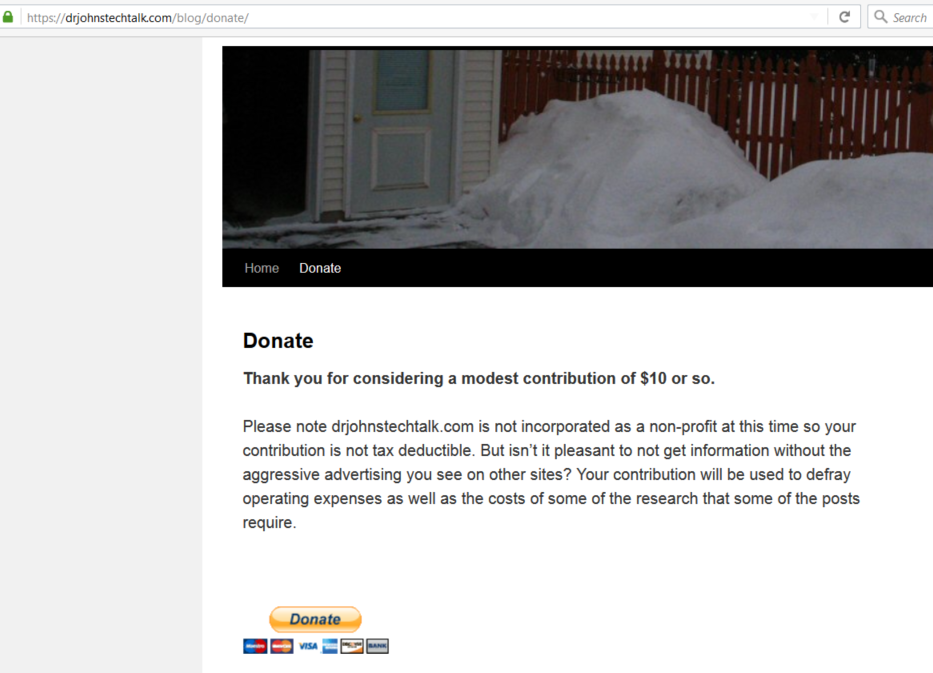
Here’s a screen shot of my donate page with its PayPal donate button.
OK, I lied. You probably also want a Thank you page in case someone actually does contribute! So build a Thank you page on your blog and record the URL. In WordPress I see you can create this as a hidden page – not appearing in any menu yet still using your theme. Here is my hidden thank you page as an example. Now you really have everything you need to build your Paypal button – one of the requested fields is the URL for your thank you page which we now have.
But is it appropriate?
Well, if like me you only expect the occasional, rare contribution, it’s probably akin to finding yourself in public short of money and asking for a few bucks to take the subway, or whatever… If you’re expecting to get thousands a year you’d better incorporate as a 501c3! As a courtesy I remind people that their contribution is not tax deductible. I guess for low volume stuff it can be treated the way gifts are treated for tax purposes.
Conclusion
drjohnstechtalk.com I hope serves as an example of “paying it forward.” I have benefitted from some good advice on the Internet (and suffered from some terrible advice as well), so I hope to benefit others by providing some clear guidance on topics where I can contribute. But I don’t see that as a barrier to asking for a modest contribution to help defray operational and research costs. In this post I show how I did it. It turns out to be simple, but not well documented on balance.
References and related
PayPal’s Donate Button creation web page with step-by-step instructions.
Care to donate to drjohnstechtalk.com? Here’s my donate page.
My thank you page.