It’s convenient to name drop different types of cyber attacks at a party. I often struggle to name more than a few. I will try to maintain a running list of them.
But I find you cannot speak about cybersecurity unless you also have a basic understanding of information technology so I am including some of those terms as well.
As I write this I am painfully aware that you could simply ask ChatGPT to generate a list of all relevant terms in cybersecurity along with their definitions – at least I think you could – and come up with a much better and more complete list. But I refuse to go that route. These are terms I have personally come across so they have special significance for me personally. In other words, this list has been organically grown. For instance I plowed through a report by a major vendor specializing in reviewing other vendor’s offerings and it’s just incredible just how dense with jargon and acronyms each paragragh is: a motherlode of state-of-the-art tech jargon.
Baitortion
I guess an attack which has a bait such as a plum job offer combined with some kind of extortion? The usage was not 100% clear.
Clickfix infection chain
Upon visiting compromised websites, victims are redirected to domains hosting fake popup windows that instruct them to paste a script into a PowerShell terminal to fix an issue.
Collision attack
I.e., against the MD5 hash algorithm as done in the Blast RADIUS exploit.
Credential Stuffing Attack
I.e., password re-use. Takes advantage of users re-using passwords for different applications. Nearly three of four consumers re-use password this way. Source: F5. Date: 3/2024
Password spraying
A type of attack in which the threat actor tries the same password with multiple accounts, until one combination works.
Supply Chain attack
Social Engineering
Hacking
Hacktivist
I suppose that would be an activitst who uses hacking to further their agenda.
Living off the land
Data Breach
Keylogger
Darknet
Captcha
Click farms
Jackpotting
This is one of my favorite terms. Imagine crooks implanted malware into an ATM and were able to convince it to dispense all its available cash to them on the spot! something like this actually happened. Scary.
Overlay Attack
Example: When you open a banking app on your phone, malware loads an HTML phishing page that’s designed to look just like that particular app and the malware’s page is overlaid on top.
Skimmer
bot
Anti-bot, bot defense
Spoofing
Mitigation
SOC
Selenium (Se) or headless browser
WAF
Obfuscation
PII, Personally Identifiable Information
api service
Reverse proxy
Inline
endpoint, e.g., login, checkout
scraping
Layer 7
DDOS
Carpet bombing DDOS attack
Many sources hitting many targets within the same subnet. See:
(Voice Phishing) A form of cyber-attack where scammers use phone calls to trick individuals into revealing sensitive information or performing certain actions.
Business email compromise (BEC)
Deepfakes
Threat Intelligence
Social engineering
Cybercriminal
SIM box
Command and control (C2)
Typo squatting
Voice squatting
A technique similar to typo squatting, where Alexa and Google Home devices can be tricked into opening attacker-owned apps instead of legitimate ones.
North-South
East-West
Exfiltrate
Malware
Infostealer
Obfuscation
Antivirus
Payload
Sandbox
Control flow obfuscation
Indicators of Compromise
AMSI (Windows Antimalware Scan Interface)
Polymorphic behavior
WebDAV
Protocol handler
Firewall
Security Service Edge (SSE)
Secure Access Service Edge (SASE)
Zero Trust
Zero Trust is a security model that assumes that all users, devices, and applications are inherently untrustworthy and must be verified before being granted access to any resources or data.
Zero Trust Network Access (ZTNA)
Zero Trust Edge (ZTE)
Secure Web Gateway (SWG)
Cloud Access Security Broker (CASB)
Remote Browser Isolation (RBI)
Content Disarm and Reconstruction (CDR)
Firewall as a service
Egress address
Data residency
Data Loss Prevention (DLP)
Magic Quadrant
Managed Service Provider (MSP)
0-day or Zero day
User Experience (UX)
Watermark
DevOps
Multitenant
MSSP
Remote Access Trojan (RAT)
SOGU
2024. A remote access trojan.
IoC (Indicators of Compromise)
Object Linking and Embedding
(Powershell) dropper
Backdoor
TTP (Tactics, Techniques and Procedures)
Infostealer
Shoulder surfing
Ransomware
Pig butchering
This is particularly disturbing to me because there is a human element, a foreign component, crypto currency, probably a type of slave trade, etc. See the Bloomberg Businessweek story about this.
Forensic analysis
Attack vector
Attack surface
Economic espionage
Gap analysis
AAL (Authentication Assurance Level)
IAL (Identity Assurance Level)
CSPM (Cloud Security Posture Management)
Trust level
Remediation
Network perimeter
DMZ (Demilitarized zone)
Defense in depth
Lateral movement
Access policy
Micro segmentation
Least privilege
Elevated privileges
Breach
Intrusion
Insider threat
Cache poisoning
I know it as DNS cache poisoning. If an attacker manages to fill the DNS resolver’s cache with records that have been altered or “poisoned.”
A text-based interfaces that allow for remote server control.
Crypto Miner
A RCE (Remote Code Execution)
Threat Actor
APT (Advanced Persistent Threat)
Compromise
Vulnerability
Bug
Worm
Remote Access VPN (RAVPN)
XDR (Extended Detection and Response)
SIEM (Security Information and Event Management)
User Entity Behavior Analytics (UEBA)
Path traversal vulnerability
An attacker can leverage path traversal sequences like “../” within a request to a vulnerable endpoint which ultimately allows access to sensitive files like /etc/shadow.
Tombstoning
Post-exploit persistence technique
MFA bomb
Bombard a user with notifications until they finally accept one.
Use-after-free (UAF)
A use-after-freevulnerability occurs when programmers do not manage dynamic memory allocation and deallocation properly in their programs.
Cold boot attack
A cold boot attack focuses on RAM and the fact that it is readable for a short while after a power cycle.
One of those dreadully overused terms borrowed from the military that mostly only marketing people like to throw around. It means what you think it might mean.
Boot start
A flag for a driver in Windows that tells it to always start on boot.
Browser
CHAP
CISA (Cybersecurity and Infrastructure Security Agency)
CVE
CVEs, or Common Vulnerabilities and Exposures, are a maintained list of vulnerabilities and exploits in computer systems. These exploits can affect anything, from phones to PCs to servers or software. Once a vulnerability is made public, it’s given a name in the format CVE–. There are also scoring systems for CVEs, like the CVSS (Common Vulnerability Scoring System), which assigns a score based on a series of categories, such as how easy the vulnerability is to exploit, whether any prior access or authentication is required, as well as the impact the exploit could have.
Data at rest
Data in motion
Data Remanence
The residual representation of data that remains even after attempting to erase or initialize RAM.
DDI (DNS, DHCP and IP address management)
DHCP
DLL
DLP (Data Loss Prevention)
DoH (DNS over HTTPS)
Domain
EAP
Eduroam
Enhanced Factory Reset (EFR)
Exact Data Matching (EDM)
GSLB (global Server Load Balancing)
ICS
IPSEC
Link
Mandiant
Modbus protocol
MS-CHAPv2
Named pipes
I read it’s a Windows thing. huh. Hardly. It’s been on unix systems long before it was a twinkle in the eye of Bill gates. It acts like a pipe (|) except you give it a name in the filesystem and so it is a special file type. It’s used for inter-process communication.
.NET
NSA (National Security Agency)
OCR (Optical Character Recognition)
OpenRoaming
OT (Operational Technology)
PAP
Patch
PaaS (Platform as a Service)
PLC (programmable logic controller)
Portable Executable (PE)
Private Cloud
Proof of Concept (POC)
RADIUS
Ray
An open-source unified compute framework used by the likes of OpenAI, Uber, and Amazon which simplifies the scaling of AI and Python workloads, including everything from reinforcement learning and deep learning to tuning and model serving.
I’m imagining a scenario where yuo are in a world where a private pki reigns. In that case you want to just make sure lftp knows where to find the private root CA and possibly the intermediate CA.
This headline was inspired by years of listening to our managed service providers: overpromise and underdeliver! Who’s hacking my web site? I have no idea. But what I can deliver is a list of badly behaved IP addresses over the last 24 hours.
Let’s do it
So, here is a dynamically-compiled list of offenders who have “hacked” my web site over the last 24 hours. They are IP addresses caught trying to fetch non-existent web pages (such as the default login page) or post unauthorized content to the site such as spammy comments.
Without further ado, here are the latest IPs which include up-to-the-minute entries.
What are they?
I don’t think it’s anything glamorous like an actual black hat scheming to crack through my site’s defenses, which would probably fall pretty quickly! It looks like a lot of the same type of probes coming from different IPs. So I suspect the work of a botnet that crawls through promising-sounding WordPress sites, looking for weak ones. Probably thousands of bots – things like compromised security cameras and poorly configured routers (IoT) orchestrated by a Command and Control station under the control of a small group of bad actors.
And there is probably a bit of access from “security researchers” (ethical hackers) who look for weaknesses that they can responsibly disclose. I’m imagining this scenario: a security researcher discovers a 0-day WordPress vulnerability and wants to make a blanket statement to the effect: 30% of all WordPress sites are vulnerable to this 0-day exploit. So they have to test it. Well, I don’t want to be anyone’s statistic. So no thank you.
But I don’t have time to deal with any of that. It’s one strike and you’re out at my site: I block every single one of these IPs doing these things, even based on a single offense.
Note the access at the end to /blog//wp-login.php, a link which does not exist on my site! I imagine the user agent is spoofed. Fate: never again to access my site.
I caught it due to the presence of index.php – another string which does not have a legit reason to appear in my access log, AFAIK.
Then there’s the bot trying to pull a non-existent .env (which, if it existed, might have contained environment variables which might have provided hints about the inner workings of the site):
By looking for specific strings I realize I am implementing a very poor man’s version of a Web Application Firewall. Commercial WAFs are amazing to me – I know because i work with them. They have thousands of signatures, positive and negative matches, stuff you’d never even dream about. I can’t afford one for my self-hosted and self-funded site.
A word about command injection
If you look at the top 10 web site exploits, command injection is #1. A bunch of security vendors got together to help web site operators understand the most common threats by cataloging and explaining them in easy-to-understand terms. It’s pretty interesting. https://owasp.org/www-project-top-ten/
Conclusion
Sadly, the most common visitor to me web site are bots up to no good. I have documented whose hitting me up in real time, in case this proves to be of interest to the security community. Actual offending lines from my access file have been provided to make everything more concrete.
I have offered a very brief security discussion.
I don’t know who’s hacking me, or what’s hacking me, but I have shared a lot of information not commonly shared.
References and related
A great commercial web application firewall (WAF) is offered by F5.
Intro
Scripts are normally not worth sharing because they are so easy to construct. This one illustrates several different concepts so may be of interest to someone else besides myself:
packet trace utility in Checkpoint firewall Gaia
send Ctrl-C interrupt to a process which has been run in the background
giving unqieu filenames for each cut
general approach to tacklnig the challenge of breaking a potentially large output into manageable chunks
The script
I wanted to learn about unexpected VPN client disconnects that a user, Sandy, was experiencing. Her external IP is 99.221.205.103.
while /bin/true; do
# date +%H%M inserts the current Hour (HH) and minute (MM).
file=/tmp/sandy`date +%H%M`.cap
# fw monitor is better than tcpdump because it looks at all interfaces
fw monitor -o $file -l 60 -e "accept src=99.221.205.103 or dst=99.221.205.103;" &
# $! picks up the process number of the command we backgrounded just above
pid=$!
sleep 600
#sleep 90
kill $pid
sleep 3
gzip $file
done
while /bin/true; do
# date +%H%M inserts the current Hour (HH) and minute (MM).
file=/tmp/sandy`date +%H%M`.cap
# fw monitor is better than tcpdump because it looks at all interfaces
fw monitor -o $file -l 60 -e "accept src=99.221.205.103 or dst=99.221.205.103;" &
# $! picks up the process number of the command we backgrounded just above
pid=$!
sleep 600
#sleep 90
kill $pid
sleep 3
gzip $file
done
This type of tracing of this VPN session produces about 20 MB of data every 10 minutes. I want to be able to easily share the trace file afterwards in an email. And smaller files will be faster when analyzed in Wireshark.
The script itself I run in the background:
# ./sandy.sh &
And to make sure I don’t get logged out, I just run a slow PING afterwards:
# ping ‐i45 1.1.1.1
Alternate approaches
In retrospect I could have simply used the -ci argument and had the process terminate itself after a certain number of packets were recorded, and saved myself the effort of killing that process. But oh well, it is what it is.
Small tip to see all packets
Turn acceleration off:
fwaccel stat
fwaccel off
fwaccel on (when you’re done).
Conclusion
I share a script I wrote today that is simple, but illustrates several useful concepts.
Intro
Wordpress tells me to upgrade to version 5.4. But when I try it says nope, your version of php is too old. Now admittedly, I’m running on an ancient CentOS server, now at version 6.10, which I set up back in 2012 I believe.
I’m pretty comfortable with CentOS so I wanted to continue with it, but just on a newer version at Amazon. I don’t like being taken advantage of, so I also wanted to avoid those outfits which charge by the hour for providing CentOS, which should really be free. Those costs can really add up.
Lots of travails setting up my AWS image, and then…
I managed to find a CentOS amongst the community images. I chose centos-8-minimal-install-201909262151 (ami-01b3337aae1959300).
OK. Brand new CentOS 8 image, 8.1.1911 after patching it, which will be supported for 10 years. Surely it has the latest and greatest??
But I didn’t see it until after I had done all the work below the hard way. Oh well.
When I install php I get version 7.2.11. WordPress is telling me I need a minimum of php version 7.3. If i download the latest php, it tells me to download the latest apache. So I do. Version 2.4.43. I also install gcc, anticipating some compiling in my future…
But apache won’t even configure:
httpd-2.4.43]$ ./configure --enable-so
checking for chosen layout... Apache
checking for working mkdir -p... yes
checking for grep that handles long lines and -e... /usr/bin/grep
checking for egrep... /usr/bin/grep -E
checking build system type... x86_64-pc-linux-gnu
checking host system type... x86_64-pc-linux-gnu
checking target system type... x86_64-pc-linux-gnu
configure:
configure: Configuring Apache Portable Runtime library...
configure:
checking for APR... no
configure: error: APR not found. Please read the documentation.
httpd-2.4.43]$ ./configure --enable-so
checking for chosen layout... Apache
checking for working mkdir -p... yes
checking for grep that handles long lines and -e... /usr/bin/grep
checking for egrep... /usr/bin/grep -E
checking build system type... x86_64-pc-linux-gnu
checking host system type... x86_64-pc-linux-gnu
checking target system type... x86_64-pc-linux-gnu
configure:
configure: Configuring Apache Portable Runtime library...
configure:
checking for APR... no
configure: error: APR not found. Please read the documentation.
--with-apr=PATH prefix for installed APR or the full path to
apr-config
--with-apr-util=PATH prefix for installed APU or the full path to
apu-config
(apr-util configure)
checking for APR... no
configure: error: APR could not be located. Please use the --with-apr option.
try:
./configure --with-apr=/usr/local/apr
but
-D_GNU_SOURCE -I/usr/local/src/apr-util-1.6.1/include -I/usr/local/src/apr-util-1.6.1/include/private -I/usr/local/apr/include/apr-1 -o xml/apr_xml.lo -c xml/apr_xml.c && touch xml/apr_xml.lo
xml/apr_xml.c:35:10: fatal error: expat.h: No such file or directory
#include
^~~~~~~~~
compilation terminated.
make[1]: *** [/usr/local/src/apr-util-1.6.1/build/rules.mk:206: xml/apr_xml.lo] Error 1
--with-apr=PATH prefix for installed APR or the full path to
apr-config
--with-apr-util=PATH prefix for installed APU or the full path to
apu-config
(apr-util configure)
checking for APR... no
configure: error: APR could not be located. Please use the --with-apr option.
try:
./configure --with-apr=/usr/local/apr
but
-D_GNU_SOURCE -I/usr/local/src/apr-util-1.6.1/include -I/usr/local/src/apr-util-1.6.1/include/private -I/usr/local/apr/include/apr-1 -o xml/apr_xml.lo -c xml/apr_xml.c && touch xml/apr_xml.lo
xml/apr_xml.c:35:10: fatal error: expat.h: No such file or directory
#include
^~~~~~~~~
compilation terminated.
make[1]: *** [/usr/local/src/apr-util-1.6.1/build/rules.mk:206: xml/apr_xml.lo] Error 1
So I install expat header files:
$ yum install expat-devel
And then the make of apr-util goes through. Not sure this is the right approach or not yet, however.
So following php’s advice, I have:
$ ./configure –enable-so
checking for chosen layout... Apache
...
checking for pcre-config... false
configure: error: pcre-config for libpcre not found. PCRE is required and available from http://pcre.org/
checking for chosen layout... Apache
...
checking for pcre-config... false
configure: error: pcre-config for libpcre not found. PCRE is required and available from http://pcre.org/
So I install pcre-devel:
$ yum install pcre-devel
Now the apache configure goes through, but the make does not work:
/usr/local/apr/build-1/libtool --silent --mode=link gcc -g -O2 -pthread -o htpasswd htpasswd.lo passwd_common.lo /usr/local/apr/lib/libaprutil-1.la /usr/local/apr/lib/libapr-1.la -lrt -lcrypt -lpthread -ldl -lcrypt
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_GetErrorCode'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetEntityDeclHandler'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ParserCreate'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetCharacterDataHandler'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ParserFree'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetUserData'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_StopParser'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_Parse'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ErrorString'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetElementHandler'
collect2: error: ld returned 1 exit status
make[2]: *** [Makefile:48: htpasswd] Error 1
/usr/local/apr/build-1/libtool --silent --mode=link gcc -g -O2 -pthread -o htpasswd htpasswd.lo passwd_common.lo /usr/local/apr/lib/libaprutil-1.la /usr/local/apr/lib/libapr-1.la -lrt -lcrypt -lpthread -ldl -lcrypt
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_GetErrorCode'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetEntityDeclHandler'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ParserCreate'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetCharacterDataHandler'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ParserFree'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetUserData'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_StopParser'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_Parse'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ErrorString'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetElementHandler'
collect2: error: ld returned 1 exit status
make[2]: *** [Makefile:48: htpasswd] Error 1
So I try configure or apr-util with expat built-in.
But when I do the make of apr-util I now get this error:
/usr/local/apr/build-1/libtool: line 7475: cd: builtin/lib: No such file or directory
libtool: error: cannot determine absolute directory name of 'builtin/lib'
make[1]: *** [Makefile:93: libaprutil-1.la] Error 1
make[1]: Leaving directory '/usr/local/src/apr-util-1.6.1'
make: *** [/usr/local/src/apr-util-1.6.1/build/rules.mk:118: all-recursive] Error 1
From what I read this new error occurs due to having –expat-built-in! So now what? So I get rid of that in my configure statement for apr-util. For some reason, apr-util goes through and compiles. And so I try this for compiling apache24:
$ ./configure –enable-so –with-apr=/usr/local/apr
And then I make it. And for some reason, now it goes through. I doubt it will work, however… it kind of does work.
It threw the files into /usr/local/apache2, where there is a bin directory containing apachectl. I can launch apachectl start, and then access a default page on port 80. Not bad so far…
Hey, maybe for once their instructions will work. Nope.
configure: error: Package requirements (libxml-2.0 >= 2.7.6) were not met:
Package 'libxml-2.0', required by 'virtual:world', not found
Consider adjusting the PKG_CONFIG_PATH environment variable if you
installed software in a non-standard prefix.
So I guess I need to install libxml2-devel:
$ yum install libxm2-devel
Looks like I get past that error. Now it’s on to this one:
configure: error: Package requirements (sqlite3 > 3.7.4) were not met:
So I install sqlite-devel:
$ yum install sqlite-devel
Now my configure almost goes through, except, as I suspected, that was a nonsense argument:
It’s not there when you look for it! Why the heck did they – php.net – give an example with exactly that?? Annoying. So I leave it out. It goes through. Run make. It takes a long time to compile php! And this server is pretty fast. It’s slower than apache or anything else I’ve compiled.
But eventually the compile finished. It added a LoadModule statement to the apache httpd.conf file. And, after I associated files with php extension to the php handler, a test file seemed to work. So php is beginning to work. Not at all sure about the mysql tie-in, however. In fact see further down below where I confirm my fears that there is no MySQL support when PHP is compiled this way.
Is running SSL asking too much?
Apparently, yes. I don’t think my apache24 has SSL support built-in:
Invalid command 'SSLCipherSuite', perhaps misspelled or defined by a module not included in the server configuration
Invalid command 'SSLCipherSuite', perhaps misspelled or defined by a module not included in the server configuration
So I try
$ ./configure –enable-so –with-apr=/usr/local/apr –enable-ssl
Not good…
checking for OpenSSL... checking for user-provided OpenSSL base directory... none
checking for OpenSSL version >= 0.9.8a... FAILED
configure: WARNING: OpenSSL version is too old
no
checking whether to enable mod_ssl... configure: error: mod_ssl has been requested but can not be built due to prerequisite failures
checking for OpenSSL... checking for user-provided OpenSSL base directory... none
checking for OpenSSL version >= 0.9.8a... FAILED
configure: WARNING: OpenSSL version is too old
no
checking whether to enable mod_ssl... configure: error: mod_ssl has been requested but can not be built due to prerequisite failures
Where is it pulling that old version of openssl? Cause when I do this:
$ openssl version
OpenSSL 1.1.1c FIPS 28 May 2019
OpenSSL 1.1.1c FIPS 28 May 2019
That’s not that old…
I also noticed this error:
configure: WARNING: Your APR does not include SSL/EVP support. To enable it: configure --with-crypto
So maybe I will re-compile APR with that argument.
Nope. APR doesn’t even have that argument. But apr-uil does. I’ll try that.
Not so good:
configure: error: Crypto was requested but no crypto library could be enabled; specify the location of a crypto library using --with-openssl, --with-nss, and/or --with-commoncrypto.
I give up. maybe it was a false alarm. I’ll try to ignore it.
This time at least the configure goes through – no ssl-related errors.
I needed to add the Loadmodule statement by hand to httpd.conf since that file was already there from my previous build and so did not get that statement after my re-build with ssl support:
LoadModule ssl_module modules/mod_ssl.so
LoadModule ssl_module modules/mod_ssl.so
Next error please
Now I have this error:
AH00526: Syntax error on line 92 of /usr/local/apache2/conf/extra/drjohns.conf:
SSLSessionCache: 'shmcb' session cache not supported (known names: ). Maybe you need to load the appropriate socache module (mod_socache_shmcb?).
AH00526: Syntax error on line 92 of /usr/local/apache2/conf/extra/drjohns.conf:
SSLSessionCache: 'shmcb' session cache not supported (known names: ). Maybe you need to load the appropriate socache module (mod_socache_shmcb?).
I want results. So I just comment out the lines that talk about SSL Cache and anything to do with SSL cache.
And…it starts…and…it is listening on both ports 80 and 443 and…it is running SSL. So I think i cracked the SSL issue.
Switch focus to Mysql
I didn’t bother to find mysql. I believe people now use mariadb. So I installed the system one with a yum install mariadb. I became root and learned the version with a select version();
+-----------------+
| version() |
+-----------------+
| 10.3.17-MariaDB |
+-----------------+
1 row in set (0.000 sec)
+-----------------+
| version() |
+-----------------+
| 10.3.17-MariaDB |
+-----------------+
1 row in set (0.000 sec)
Is that recent enough? Yes! For once we skate by comfortably. The WordPress instructions say:
MySQL 5.6 or MariaDB 10.1 or greater
I setup apache. I try to access wordpress setup but instead get this message:
Forbidden
You don't have permission to access this resource.
Forbidden
You don't have permission to access this resource.
every page I try gives this error.
The apache error log says:
client denied by server configuration: /usr/local/apache2/htdocs/
client denied by server configuration: /usr/local/apache2/htdocs/
Not sure where that’s coming from. I thought I supplied my own documentroot statements, etc.
I threw in a Require all granted within the Directory statement and that seemed to help.
PHP/MySQL communication issue surfaces
Next problem is that PHP wasn’t compiled correctly it seems:
Your PHP installation appears to be missing the MySQL extension which is required by WordPress.
Your PHP installation appears to be missing the MySQL extension which is required by WordPress.
So I’ll try to re-do it. This time I am trying these arguments to configure:
$ ./configure ‐‐with-apxs2=/usr/local/apache2/bin/apxs ‐‐with-mysqli
Well, I’m not so sure this worked. Trying to setup WordPress, I access wp-config.php and only get:
Error establishing a database connection
Error establishing a database connection
This is roll up your sleeves time. It’s clear we are getting no breaks. I looked into installing PhpMyAdmin, but then I would neeed composer, which may depend on other things, so I lost interest in that rabbit hole. So I decide to simplify the problem. The suggested test is to write a php program like this, which I do, calling it tst2.php:
PHP Warning: mysqli_connect(): (HY000/2002): No such file or directory in /web/drjohns/blog/tst2.php on line 7
Warning: mysqli_connect(): (HY000/2002): No such file or directory in /web/drjohns/blog/tst2.php on line 7
PHP Warning: mysqli_connect(): (HY000/2002): No such file or directory in /web/drjohns/blog/tst2.php on line 7
Warning: mysqli_connect(): (HY000/2002): No such file or directory in /web/drjohns/blog/tst2.php on line 7
Some quick research tells me that php does not know where the file mysql.sock is to be found. I search for it:
$ sudo find / ‐name mysql.sock
and it comes back as
/var/lib/mysql/mysql.sock
/var/lib/mysql/mysql.sock
So…the prescription is to update a couple things in pph.ini, which has been put into /usr/local/lib in my case because I compiled php with mostly default values. I add the locatipon of the mysql.sock file in two places for good measure:
Install WordPress
I begin to install WordPress, creating an initial user and so on. When I go back in I get a directory listing in place of the index.php. So I call index.php by hand and get a worisome error:
Fatal error: Uncaught Error: Call to undefined function gzinflate() in /web/drjohns/blog/wp-includes/class-requests.php:947 Stack trace: #0 /web/drjohns/blog/wp-includes/class-requests.php(886): Requests::compatible_gzinflate('\xA5\x92\xCDn\x830\f\x80\xDF\xC5g\x08\xD5\xD6\xEE...'
Fatal error: Uncaught Error: Call to undefined function gzinflate() in /web/drjohns/blog/wp-includes/class-requests.php:947 Stack trace: #0 /web/drjohns/blog/wp-includes/class-requests.php(886): Requests::compatible_gzinflate('\xA5\x92\xCDn\x830\f\x80\xDF\xC5g\x08\xD5\xD6\xEE...'
I should have compiled php with zlib is what I determine it means… zlib and zlib-devel packages are on my system so this should be straightforward.
More arguments for php compiling
OK. Let’s be sensible and try to reproduce what I had done in 2017 to compile php instead of finding an resolving mistakes one at a time.
Package 'libcurl', required by 'virtual:world', not found
I will install libcurl-devel in hopes of making this one go away.
Past that error, and onto this one:
configure: error: DBA: Could not find necessary header file(s).
I’m trying to drop the –with-gdbm and skip that whole DBA thing since the database connection seemed to be working without it. Now I see an openssl problem:
make: *** No rule to make target '/tmp/php-7.4.4/ext/openssl/openssl.c', needed by 'ext/openssl/openssl.lo'. Stop.
make: *** No rule to make target '/tmp/php-7.4.4/ext/openssl/openssl.c', needed by 'ext/openssl/openssl.lo'. Stop.
Even if I get rid of openssl I still see a problem when running configure:
gawk: ./build/print_include.awk:1: fatal: cannot open file `ext/zlib/*.h*' for reading (No such file or directory)
gawk: ./build/print_include.awk:1: fatal: cannot open file `ext/zlib/*.h*' for reading (No such file or directory)
Now I can ignore that error because configure exits with 0 status and make, but the make then stops at zlib:
SIGNALS -c /tmp/php-7.4.4/ext/sqlite3/sqlite3.c -o ext/sqlite3/sqlite3.lo
make: *** No rule to make target '/tmp/php-7.4.4/ext/zlib/zlib.c', needed by 'ext/zlib/zlib.lo'. Stop.
SIGNALS -c /tmp/php-7.4.4/ext/sqlite3/sqlite3.c -o ext/sqlite3/sqlite3.lo
make: *** No rule to make target '/tmp/php-7.4.4/ext/zlib/zlib.c', needed by 'ext/zlib/zlib.lo'. Stop.
Reason for above php compilation errors
I figured it out. My bad. I had done a make distclean in addition to a make clean when i was re-starting with a new set of arguments to configure. i saw it somewhere advised on the Internet and didn’t pay much attention, but it seemed like a good idea. But I think what it was doing was wiping out the files in the ext directory, like ext/zlib.
So now I’m starting over, now with php 7.4.5 since they’ve upgraded in the meanwhile! With this configure command line (I figure I probably don’t need gdb):
./configure –with-apxs2=/usr/local/apache2/bin/apxs –with-mysqli –disable-cgi –with-zlib –with-gettext –with-gdbm –with-curl –with-openssl
Well, the php compile went through, however, I can’t seem to access any WordPress pages (all WordPress pages clock). Yet my simplistic database connection test does work. Hmmm. OK. If they come up at all, they come up exceedingly slowly and without correct formatting.
I think I see the reason for that as well. The source of the wp-login.php page (as viewed in a browser window) includes references to former hostnames my server used to have. Of course fetching all those objects times out. And they’re the ones that provide the formatting. At this point I’m not sure where those references came from. Not from the filesystem, so must be in the database as a result of an earlier WordPress install attempt. Amazon keeps changing my IP, you see. I see it is embedded into WordPress. In Settings | general Settings. I’m going to have this problem every time…
What I’m going to do is to create a temporary fictitious name, johnstechtalk, which I will enter in my hosts file on my Windows PC, in Windows\system32\drivers\etc\hosts, and also enter that name in WordPress’s settings. I will update the IP in my hosts file every time it changes while I am playing around. And now there’s even an issue doing this which has always worked so reliably in the past. Well, I found I actually needed to override the IP for drjohnstechtalk.com in my hosts file. But it seems Firefox has moved on to using DNS over https, so it ignores the hosts file now! i think. Edge still uses it however, thankfully.
WordPress
So WordPress is basically functioning. I managed to install a few of my fav plugins: Akismet anti-spam, Limit Login Attempts, WP-PostViews. Some of the plugins are so old they actually require ftp. Who runs ftp these days? That’s been considered insecure for many years. But to accommodate I installed vsftpd on my server and ran it, temporarily.
Then Mcafee on my PC decided that wordpress.org is an unsafe site, thank you very much, without any logs or pop-ups. I couldn’t reach that site until I disabled the Mcafee firewall. Makes it hard to learn how to do the next steps of the upgrade.
More WordPress difficulties
WordPress is never satisfied with whatever version you’ve installed. You take the latest and two weeks later it’s demanding you upgrade already. My first upgrade didn’t go so well. Then I installed vsftpd. The upgrade likes to use your local FTP server – at least in my case. so for ftp server I just put in 127.0.0.1. Kind of weird. Even still I get this error:
Downloading update from https://downloads.wordpress.org/release/wordpress-5.4.2-no-content.zip…
The authenticity of wordpress-5.4.2-no-content.zip could not be verified as no signature was found.
Unpacking the update…
Could not create directory.
Installation Failed
So I decided it was a permissions problem: my apache was running as user daemon (do a ps -ef to see running processes), while my wordpress blog directory was owned by centos. So I now run apache as user:group centos:centos. In case this helps anyone the apache configurtion commands to do this are:
User centos
Group centos
then I go to my blog directory and run something like:
chown -R centos:centos *
Wordpres Block editor non-functional after the upgrade
When I did the SQL import from my old site, I killed the block editor on my new site! This was disconcerting. That little plus sign just would not show up on new pages, no posts, whatever. So I basically killed wordpress 5.4. So I took a step backwards and started v 5.4 with a clean (empty) database like a fresh install to make sure the block editor works then. It did. Whew! Then I did an RTFM and deactivated my plugins on my old WordPress install before doing the mysql backup. I imported that SQL database, with a very minimal set of plugins activated, and, whew, this time I did not blow away the block editor.
CentOS bogs down
I like my snappy new Centos 8 AMI 80% of the time. But that remaining 20% is very annoying. It freezes. Really bad. I ran a top until the problem happened. Here I’ve caught the problem in action:
top - 16:26:11 up 1 day, 21 min, 2 users, load average: 3.96, 2.93, 5.30
Tasks: 95 total, 1 running, 94 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 2.6 sy, 0.0 ni, 0.0 id, 95.8 wa, 0.4 hi, 0.3 si, 0.7 st
MiB Mem : 1827.1 total, 63.4 free, 1709.8 used, 53.9 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 9.1 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
44 root 20 0 0 0 0 S 1.6 0.0 12:47.94 kswapd0
438 root 0 -20 0 0 0 I 0.5 0.0 1:38.84 kworker/0:1H-kblockd
890 mysql 20 0 1301064 92972 0 S 0.4 5.0 1:26.83 mysqld
5282 centos 20 0 1504524 341188 64 S 0.4 18.2 0:06.06 httpd
5344 root 20 0 345936 1008 0 S 0.4 0.1 0:00.09 sudo
560 root 20 0 93504 6436 3340 S 0.2 0.3 0:02.53 systemd-journal
712 polkitd 20 0 1626824 4996 0 S 0.2 0.3 0:00.15 polkitd
817 root 20 0 598816 4424 0 S 0.2 0.2 0:12.62 NetworkManager
821 root 20 0 634088 14772 0 S 0.2 0.8 0:18.67 tuned
1148 root 20 0 216948 7180 3456 S 0.2 0.4 0:16.74 rsyslogd
2346 john 20 0 273640 776 0 R 0.2 0.0 1:20.73 top
1 root 20 0 178656 4300 0 S 0.0 0.2 0:11.34 systemd
So what jumps out at me is the 95.8% wait time – that ain’t good – an that a process which includes the name swap is at the top of ths list, combined with the fact that exactly 0 swap space is allocated. My linux skills may be 15 years out-of-date, but I think I better allocate some swap space (but why does it need it so badly??). On my old system I think I had done it. I’m a little scared to proceed for fear of blowing up my system.
So if you use drjohnstechtalk.com and it freezes, just come back in 10 minutes and it’ll probably be running again – this situation tends to self-correct. No one’s perfect.
Some of the commands are dd to create an empty file, mkswap, swapon and swapon -s to see what it’s doing. And it really, really helped. I think sometimes mariadb needed to swap, and sometimes apache did. My system only has 1.8 GB of memory or so. And the drive is solid state, so it should be kind of fast. Because I used 1.2 GB for swap, I also extended my volume size when I happened upon Amazon’s clear instructions on how you can do that. Who knew? See below for more on that. If I got it right, Amazon also gives you more IO for each GB you add. I’m definitely getting good response after this swap space addition.
An aside about i/o
In the old days I perfected a way to study i/o using the iostat utility. You can get it by installing the sysstat package. A good command to run is iostat -t -c -m -x 5
Examing these three consecutive lines of output from running that command is very instructional:
I tooled around in the admin panel (which previously had brought my server to its knees), and you see the %util shot up to 90%, reads per sec over 2000 , writes per second 1400. So, really demanding. It’s clear my server would die if more than a few people were hitting it hard. And I may need some fine-tuning.
Success!
Given all the above problems, you probably never thought I’d pull this off. I worked in fits and starts – mostly when my significant other was away because this stuff is a time suck. But, believe it or not, I got the new apache/openssl/apr/php/mariadb/wordpress/centos/amazon EC2 VPC/drjohnstechtalk-with-new-2020-theme working to my satisfaction. I have to pat myself on the back for that. So I pulled the plug on the old site, which basically means moving the elastic IP over from old centos 6 site to new centos8 AWS instance. Since my site was so old, I had to first convert the elastic IP from type classic to VPC. It was not too obvious, but I got it eventually.
Damn hackers already at it
Look at the access log of your new apache server running your production WordPress. If you see like I did people already trying to log in (POST accesses for …/wp-login.php), which is really annoying because they’re all hackers, at least install the WPS Hide Login plugin and configure a secret login URL. Don’t use the default login.
Meanwhile I’ve decided to freeze out anyone who triess to access wp-login.php because they can only be up to no good. So I created this script which I call wp-login-freeze.sh:
#!/bin/sh
# freeze hackers who probe for wp-login
# DrJ 6/2020
DIR=/var/log/drjohns
cd $DIR
while /bin/true; do
tail -200 access_log|grep wp-login.php|awk '{print $1}'|sort -u|while read line; do
echo $line
route add -host $line reject
done
sleep 60
done
Works great! Just do a netstat -rn to watch your ever-growing list of systems you’ve frozen out.
But xmlrpc is the worst…
Bots which invoke xmlrpc.php are the worst for little servers like mine. They absolutely bring it to its knees. So I’ve just added something similar to the wp-login freeze above, except it catches xmlrpc bots:
#!/bin/sh
# freeze hackers who are doing God knows what to xmlrpc.php
# DrJ 8/2020
DIR=/var/log/drjohns
cd $DIR
while /bin/true; do
# example offending line:
# 181.214.107.40 - - [21/Aug/2020:08:17:01 -0400] "POST /blog//xmlrpc.php HTTP/1.1" 200 401
tail -100 access_log|grep xmlrpc.php|grep POST|awk '{print $1}'|sort -u|while read line; do
echo $line
route add -host $line reject
done
sleep 30
done
I was still dissatisfied with seeing bots hit me up for 30 seconds or so, so I decided heck with it, I’m going to waste their time first. So I added a few lines to xmlrpc.php (I know you shouldn’t do this, but hackers shouldn’t do what they do either):
// DrJ improvements
if ($_SERVER['REQUEST_METHOD'] === 'POST') {
// just make bot suffer a bit... the freeze out is done by an external script
sleep(25);
//
}
// end DrJ enhancements
This freeze out trick within xmlrpc.php was only going to work if the bots run single-threaded, that is, they run serially, waiting for one request to finish before sending the next. I’ve been running it for a couple days and have enthusiasitically frozen out a few IPs. I can attest that the bots do indeed run single-threaded. So I typically get two entries in my access file to xmlrpc from a given bot, and then the bot is completely frozen out by the loopback route which gets added.
Mid-term issues discovered months later
Well, I never needed to send emails form my server, until I did. And when I did I found I couldn’t. It used to work from my old server… From reading a bit I see WordPress uses PHP’s built-in mail() function, which has its limits. But my server did not have mailx or postfix packages. So I did a
$ yum install postfix mailx
$ systemctl enable postfix
$ systemctl start postfix
That still didn’t magically make WordPress mail work, although at that point I could send mail by hand frmo a spoofed address, which is pretty cool, like:
Well, wouldn’t you know my friend’s WordPress site I was trying to host brought my server to its knees. Again. Seems to be a common theme. I was hoping it was merely hackers who’d discovered his new site and injected it with the xmlrpc DOS because that would have been easy to treat. But no, no xmlrpc issues so far according to the access_log file. He uses more of the popular plugins like Elementor and Ninja Forms. Well, that Ninja Forms Dashboard is a killer. Reliably brings my server to a crawl. I even caught it in action from a running top and saw swap was the leading cpu-consuming process. And my 1.2 GB swap file was nearly full. So I created a second, larger swap file of 2 GB and did a swapon for that. Then I decommissioned my older swap file. Did you know you can do a swapoff? Yup. I could see the old one descreasing in size and the new one building up. And now the new one is larger than the old ever could be – 1.4 GB. Now Ninja forms dashboard can be launched. Performance is once again OK.
So…hosting second WordPress site now resolved.
Updating failed. The response is not a valid JSON response.
So then he got that error after enabling permalinks. The causes for this are pretty well documented. We took the standard advice and disabled all plugins. Wihtout permalinks we were fine. With them JSON error. I put the .htaccess file in place. Still no go. So unlike most advice, in my case, where I run my own web server, I must have goofed up the config and not enabled reading of the .htaccess file. Fortunately I had a working example in the form of my own blog site. I put all those apache commands which normally go into .htaccess into the vhost config file. All good.
Although my site seems to be humming alnog, now I have to find the more obscure errors. WordPress mentioned my site health has problems.
WordPress site health
I think gd is used for graphics. I haven’t seen any negative results from this, yet. I may leave it be for the time being.
Lets Encrypt certificate renewal stops working
This one is at the bottom because it only manifests itself after a couple months – when the web site certificate either expires or is about to expire. Remember, this is a new server. I was lazy, of course, and just brought over the .acme.sh from the old server, hoping for the best. I didn’t notice any errors at first, but I eventually observed that my certificate was not getting renewed either even though it had only a few days of validity left.
To see what’s going on I ran this command by hand:
acme.sh new-authz error: {"type":"urn:acme:error:badNonce","detail":"JWS has no anti-replay nonce","status": 400}
seemed to be the most important error I noticed. The general suggestion for this is an acme.sh –upgrade, which I did run. But the nonce error persisted. It tries 20 times then gives up.
— warning: I know enough to get the job done, but not enough to write the code. Proceed at your own risk —
I read some of my old blogs and played with the command
My Webroot is /web/drjohns by the way. Now at least there was an error I could understand. I saw it trying to access something like http://drjohnstechtalk.com/.well-known/acme-challenge/askdjhaskjh
which produced a 404 Not Found error. Note the http and not https. Well, I hadn’t put much energy into setting up my http server. In fact it even has a different webroot. So what I did was to make a symbolic link
ln -s /web/drjohns/.well-known /web/insecure
I re-ran the acme.sh –issue command and…it worked. Maybe if I had issued a –renew it would not have bothered using the http server at all, but I didn’t see that switch at the time. So in my crontab instead of how you’re supposed to do it, I’m trying it with these two lines:
# Not how you're supposed to do it, but it worked once for me - DrJ 8/16/20
22 2 * * * "/root/.acme.sh"/acme.sh --issue -d drjohnstechtalk.com -w /web/drjohns > /dev/null 2>&1
22 3 16 * * "/root/.acme.sh"/acme.sh --update-account --issue -d drjohnstechtalk.com -w /web/drjohns > /dev/null 2>&1
The update-account is just for good measure so I don’t run into an account expiry problem which I’ve faced in the past. No idea if it’s really needed. Actually my whole approach is a kludge. But it worked. In two months’ time I’ll know if the cron automation also works.
Why kludge it? I could have spent hours and hours trying to get acme.sh to work as it was intended. I suppose with enough persistence I would have found the root problem.
2021 update. In retrospect
In retrospect, I think I’ll try Amazon Linux next time! I had the opportunity to use it for my job and I have to say it was pretty easy to set up a web server which included php and MariaDB. It feels like it’s based on Redhat, which I’m most familiar with. It doesn’t cost extra. It runs on the same small size on AWS. Oh well.
2022 update
I’m really sick of how far behind Redhat is with their provided software. And since they’ve been taken over by IBM, how they’ve killed CentOS is scandalous. So I’m inclined to go to a Debian-based system for my next go-around, which is much more imminent than I ever expected it to be thanks to the discontinuation of support for CentOS. I asked someone who hosts a lot of WP sites and he said he’d use Ubuntu server 22, PHP 8, MariaDB and NGinx. Boy. Guess I’m way behind. He says performance with PHP 8 is much better. I’ve always used apache but I guess I don’t really rely on it for too many fancy features.
Yes, at least if you walk. Not sure about other transportation options. Count on about 13 minutes for the walk.
Not sure why this information is so hard to find… Sometimes you land at one terminal and have to take a puddle jumper to a regional airport out of another and you’d really like to know is 50 minutes or whatever gonna be enough?
This is probably true for most major airports. It seems for instance that at Newark Liberty you can also move between terminals A, B and C without going through security once again. I thought JFK may have been an exception to this rule, but I’m not sure…
Intro
I can not find a link on the Internet for this, yet I think some admins would appreciate a relatively simple test to know is this a web site which requires a client certificate to work? The errors generated in a browser may be very generic in these situations. I see many ways to offer help, from a recipe to a tool to some pointers. I’m not yet sure how I want to proceed!
why would a site require a client CERT? Most likely as a form of client authentication.
Pointers for the DIY crowd Badssl.com plus access to a linux command line – such as using a Raspberry Pi I so often write about – will do it for you guys.
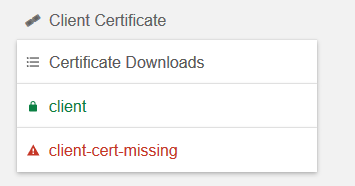
The Client Certificate section of badssl.com has most of what you need. The page is getting big, look for this:
So as a big timesaver badssl.com has created a client certificate for you which you can use to test with. Download it as follows.
Go to your linux prompt and do something like this:
$ wget https://badssl.com/certs/badssl.com‐client.pem
* About to connect() to client.badssl.com port 443 (#0)
* Trying 104.154.89.105... connected
* Connected to client.badssl.com (104.154.89.105) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* warning: ignoring value of ssl.verifyhost
* skipping SSL peer certificate verification
* NSS: client certificate from file
* subject: CN=BadSSL Client Certificate,O=BadSSL,L=San Francisco,ST=California,C=US
* start date: Nov 16 05:36:33 2017 GMT
* expire date: Nov 16 05:36:33 2019 GMT
* common name: BadSSL Client Certificate
* issuer: CN=BadSSL Client Root Certificate Authority,O=BadSSL,L=San Francisco,ST=California,C=US
* SSL connection using TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
* Server certificate:
* subject: CN=*.badssl.com,O=Lucas Garron,L=Walnut Creek,ST=California,C=US
* start date: Mar 18 00:00:00 2017 GMT
* expire date: Mar 25 12:00:00 2020 GMT
* common name: *.badssl.com
* issuer: CN=DigiCert SHA2 Secure Server CA,O=DigiCert Inc,C=US
> GET / HTTP/1.1
> User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2
> Host: client.badssl.com
> Accept: */*
>
< HTTP/1.1 200 OK
HTTP/1.1 200 OK
< Server: nginx/1.10.3 (Ubuntu)
Server: nginx/1.10.3 (Ubuntu)
< Date: Thu, 20 Jun 2019 17:59:08 GMT
Date: Thu, 20 Jun 2019 17:59:08 GMT
< Content-Type: text/html
Content-Type: text/html
< Content-Length: 662
Content-Length: 662
< Last-Modified: Wed, 12 Jun 2019 15:43:39 GMT
Last-Modified: Wed, 12 Jun 2019 15:43:39 GMT
< Connection: keep-alive
Connection: keep-alive
< ETag: "5d011dab-296"
ETag: "5d011dab-296"
< Cache-Control: no-store
Cache-Control: no-store
< Accept-Ranges: bytes
Accept-Ranges: bytes
<
<style>body { background: green; }</style>
* About to connect() to client.badssl.com port 443 (#0)
* Trying 104.154.89.105... connected
* Connected to client.badssl.com (104.154.89.105) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* warning: ignoring value of ssl.verifyhost
* skipping SSL peer certificate verification
* NSS: client certificate from file
* subject: CN=BadSSL Client Certificate,O=BadSSL,L=San Francisco,ST=California,C=US
* start date: Nov 16 05:36:33 2017 GMT
* expire date: Nov 16 05:36:33 2019 GMT
* common name: BadSSL Client Certificate
* issuer: CN=BadSSL Client Root Certificate Authority,O=BadSSL,L=San Francisco,ST=California,C=US
* SSL connection using TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
* Server certificate:
* subject: CN=*.badssl.com,O=Lucas Garron,L=Walnut Creek,ST=California,C=US
* start date: Mar 18 00:00:00 2017 GMT
* expire date: Mar 25 12:00:00 2020 GMT
* common name: *.badssl.com
* issuer: CN=DigiCert SHA2 Secure Server CA,O=DigiCert Inc,C=US
> GET / HTTP/1.1
> User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2
> Host: client.badssl.com
> Accept: */*
>
< HTTP/1.1 200 OK
HTTP/1.1 200 OK
< Server: nginx/1.10.3 (Ubuntu)
Server: nginx/1.10.3 (Ubuntu)
< Date: Thu, 20 Jun 2019 17:59:08 GMT
Date: Thu, 20 Jun 2019 17:59:08 GMT
< Content-Type: text/html
Content-Type: text/html
< Content-Length: 662
Content-Length: 662
< Last-Modified: Wed, 12 Jun 2019 15:43:39 GMT
Last-Modified: Wed, 12 Jun 2019 15:43:39 GMT
< Connection: keep-alive
Connection: keep-alive
< ETag: "5d011dab-296"
ETag: "5d011dab-296"
< Cache-Control: no-store
Cache-Control: no-store
< Accept-Ranges: bytes
Accept-Ranges: bytes
<
<style>body { background: green; }</style>
client.
badssl.com
* Connection #0 to host client.badssl.com left intact
* Closing connection #0
* Connection #0 to host client.badssl.com left intact
* Closing connection #0
No more 400 error status – that looks like success to me. Note that we had to provide the password for our client CERT, which they kindly provided as badssl.com
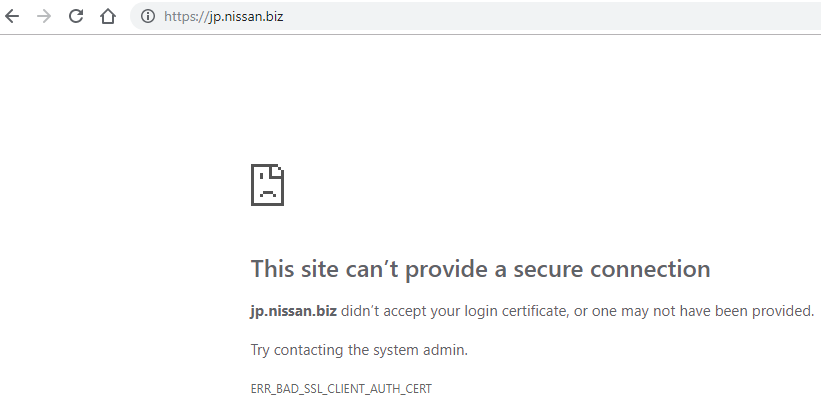
Here’s an example of a real site which requires client CERTs:
* About to connect() to jp.nissan.biz port 443 (#0)
* Trying 150.63.252.1... connected
* Connected to jp.nissan.biz (150.63.252.1) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* warning: ignoring value of ssl.verifyhost
* skipping SSL peer certificate verification
* NSS: client certificate from file
* subject: CN=BadSSL Client Certificate,O=BadSSL,L=San Francisco,ST=California,C=US
* start date: Nov 16 05:36:33 2017 GMT
* expire date: Nov 16 05:36:33 2019 GMT
* common name: BadSSL Client Certificate
* issuer: CN=BadSSL Client Root Certificate Authority,O=BadSSL,L=San Francisco,ST=California,C=US
* NSS error -12227
* Closing connection #0
* SSL connect error
curl: (35) SSL connect error
* About to connect() to jp.nissan.biz port 443 (#0)
* Trying 150.63.252.1... connected
* Connected to jp.nissan.biz (150.63.252.1) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* warning: ignoring value of ssl.verifyhost
* skipping SSL peer certificate verification
* NSS: client certificate from file
* subject: CN=BadSSL Client Certificate,O=BadSSL,L=San Francisco,ST=California,C=US
* start date: Nov 16 05:36:33 2017 GMT
* expire date: Nov 16 05:36:33 2019 GMT
* common name: BadSSL Client Certificate
* issuer: CN=BadSSL Client Root Certificate Authority,O=BadSSL,L=San Francisco,ST=California,C=US
* NSS error -12227
* Closing connection #0
* SSL connect error
curl: (35) SSL connect error
OK, so you get an error, but that’s to be expected because our certificate is not one it will accept.
The point is that if you don’t send it a certificate at all, you get a different error:
$ curl ‐v ‐i ‐k https://jp.nissan.biz/
* About to connect() to client.badssl.com port 443 (#0)
* Trying 104.154.89.105... connected
* Connected to client.badssl.com (104.154.89.105) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* warning: ignoring value of ssl.verifyhost
* Unable to load client key -8025.
* NSS error -8025
* Closing connection #0
curl: (58) Unable to load client key -8025.
Chrome gives a fairly intelligible error
Possibly to be continued…
Conclusion
We have given a recipe for testing form a linux command line if a web site requires a client certificate or not. thus it could be turned into a program
Intro
In my years at cybersecurity I’ve been sufficiently removed from the action that I’ve rarely been involved in an actual case. Until last night. A friend, whom I’ll call Jute, got a formal complaint about one of his hosted Windows servers.
We have detected multiple hacking attempts from your ip address 47.5.105.236 (Hilfer Online) to access our systems.
>
> Log of attempts:
> – Hack attempt failed at 2019-01-17T14:22:41.6539784Z. Attempted user name: Not specified (typical for port scanners or denial of service attacks), system accessed: RDP, ip address accessed: 158.69.241.92
> – Hack attempt failed at 2019-01-17T14:22:26.2213808Z. Attempted user name: Not specified (typical for port scanners or denial of service attacks), system accessed: RDP, ip address accessed: 158.69.241.92
> – Hack attempt failed at 2019-01-17T14:22:10.6304194Z. Attempted user name: Not specified (typical for port scanners or denial of service attacks), system accessed: RDP, ip address accessed: 158.69.241.92
>
>
> Please investigate this problem.
>
> Sent using IP Ban Pro
> http://ipban.com
Hack, cont.
I’ve changed the IPs to protect the guilty! But I’ve conveyed the specificity of the error reporting. Nice and detailed.
Jute has a Windows Server 2012 at that IP. He is not running a web server, so that conveniently and dramatically narrows the hackable footprint of his server. I ran a port scan and found ports 135, 139 and 3389 open. His provider (which is not AWS) offers a simple firewall which I suggested we use to block ports 135 and 139 which are for Microsoft stuff. He was running it as a local sever so I don’t tihnk he needed it.
Bright idea: use good ole netstat
The breakthrough came when I showed him the poor man’s packet trace:
netstat -an
from a CMD prompt. He ran that and I saw not one but two RDP connections. One we easily identified as his, but the other? It was coming form another IP belonging to the same provider! RDP is easily identified by just looking for the port 3389 connections. Clearly we had caught first-hand an unauthorized user.
I suggested a firewall rule to allow only his Verizon range to connect to server on port 3389. But, I am an enterprise guy, used to stateful firewalls. When we set it up we cut off his RDP session to his own server! Why? I quickly concluded this was amateur hour and a primitive, ip-chains-like stateless firewall. So we have to think about rules for each packet, not for each tcp connection.
Once we put in a rule to block access to ports 135 and 139, we also blocked Jute’s own RP session. So the instructions said once you use the firewall, an implicit DENY ALL is added to the bottom of the rules.
So we needed to add a rule like:
SRC: ANY DST: 47.5.105.236 SRC_PORT: ANY DST_PORT: 3389 ACTION: allow
But his server needs to access web sites. That’s a touch difficult with a stateless firewall. You have to enter the “backwards” rule (outbound traffic is not restricted by firewall):
SRC: ANY DST: 47.5.105.236 SRC_PORT: 443 DST_PORT: ANY ACTION: allow
But he also needs to send smtp email, and look up DNS! This is getting messy, but we can do it:
SRC: ANY DST: 47.5.105.236 SRC_PORT: 25 DST_PORT: ANY ACTION: allow
SRC: ANY DST: 47.5.105.236 SRC_PORT: 53 DST_PORT: ANY ACTION: allow
We looked up the users and saw Administrator and another user Update. We did not recognize Update so he deleted it! And changed the password to Administrator.
Finally we decided we had to bump this hacker.
So we made two rules to allow him but deny the zombie computer:
SRC: 158.69.240.92 DST: 47.5.105.236 SRC_PORT: ANY DST_PORT: 3389 ACTION: reject
SRC: ANY DST: 47.5.105.236 SRC_PORT: ANY DST_PORT: 3389 ACTION: allow
Pyrrhic victory
Success. We bumped that user right out while permitting Jute’s access to continue. The bad news? A new interloper replaced it! 95.216.86.217.
OK. So with another rule we can bump that one too.
Yup. Another success. another interloper jumps on in its place. 124.153.74.29. So we bump that one. But I begin to suspect we are bailing the Titanic with a thimble. It’s amazing. Within seconds a blocked IP is being replaced with a new one.
We need a more sweeping restriction. So we reasoned that Jute will RP from his provider where his IP does not really change.
So we replace
SRC: ANY DST: 47.5.105.236 SRC_PORT: ANY DST_PORT: 3389 ACTION: allow
with
SRC: 175.198.0.0/16 DST: 47.5.105.236 SRC_PORT: ANY DST_PORT: 3389 ACTION: allow
and we also delete the specific reject rules.
But now at this point for some reason the implicit DENY ALL rule stops working. From my server I could do an nc -v 47.5.105.236 3389 and see that that port was open, though it should ont have been. So we have to add a cleanup rule at the bottom:
SRC: ANY DST: 47.5.105.236 SRC_PORT: ANY DST_PORT: ANY ACTION: reject
That did the trick. Port no longer opened.
There still appears in netstat -an listing the last interloper, but I think it just hasn’t been timed out yet. netstat -an also clearly shows (to me anyway) what they were doing: scanning large swaths of the Internet for other vulnerable servers! The tables were filled with SYN-SENT to port 3389 of consecutive IPs! Amazing.
So I think Jute’s server was turned into a zombie which was tasked with recruiting new zombies.
We had finally frozen them out.
Later that night
Late that same night he calls me in a panic. He uses a bunch of downstream servers and that wasn’t working! The downstream servers run on a range of ports 14800 – 15200.
Now bear in mind the provider only permits us 10 firewall rules, so it’s getting kind of tight. But we manage to squeeze in another rule:
SRC: ANY DST: 47.5.105.236 SRC_PORT: 14800-15200 DST_PORT: ANY ACTION: allow
He breathes a sigh of relief because this works! But I want him we are opening a slight hole now. Short term there’s nothing we can do. It’s a small exposure: 400 open ports out of 65000 possible. It should hold him for awile with any luck.
He also tried to apply all updates at my suggestion. I’m still not sure what vulnerability was (is) exploited.
Case: tentaively closed
Our first attempt to use the Windows firewall itself was not initially successful. We may return to it.
Conclusion
We catch a zombie computer totally exploiting RDP on a Windows 2012 server. We knocked it off and it was immediately repaced with another zombie doing the same thing. Their task was to find more zombies to join to the botnet. Inbound firewall rules defined on a stateless firewall were identified which stopped this exploitation while permitting desired traffic. Not so easy when you are limited to 10 firewall rules!
This is a case where IPBAN did us a favor. The system worked as it was supposed to. We got the alert, and acted on it immediately.
I’m not 100% sure which RP vulnerability was exploited. It may have been an RCE – remote code execution not even requiring a valid logon.
Intro
Every now and then you find a product that is a leap ahead of where you were. Such is the case for us with regards to our product of choice for serial consoles.
The old
For Bluecoat (Symantec) proxy and AV systems, we had been using an ancient Avocent CPS device. It permitted ssh connection. It was slow and the menu very limited. But it did permit us to connect multiple serial consoles to one concentrator device at least.
For low-end firewalls we had been using DigiConnects, one per firewall. They are small, which may be thir one advantage. They are tricky to initially set up. Then they are slow to use.
In with the new
We heard about the Raritan Dominion line of products, stranegly enough, from some IT guys in Europe. It’s strange because they are right here in New Jersey – the company name probably comes form the Raritan river. But our usual reseller never heard of them. The specific device is a Dominion SXII.
It’s so much better than those older products. You can use their GUI to connect. This is a vendor who got their act together and eliminated Java. So many other security vendors have yet to do that, incredible as it is to say that.
It tries to autosense the wiring of the serial connector. That doesn’t always work, but it’s very easy for you to hardwire a port as DCE, or if that dosn’t work, try DTE. I use one type for my Symantec devices, another for firewalls.
Labelling the port with meaningful names is a snap, of course.
The Digis would interfere with the reboot process of the firewall so we’d have to detach them if we were going to rbeoot the firewall. These do not. So much better…
You can combine them with power control but we aren’t going to do that.
Don’t want to use the GUI? No problem, console access through ssh is also possible. Of configure dedicated ports that you ssh to for individual consoles.
Sending signals and cleanly disconnecting is easy with their menuss. Connecting to multiple consoles is alsono problem.
They have something called in-the-rack access. I know this will be useful but I haven’t figured out how to use it yet. But if it is what it sounds like it is, it will allow me to be in the server room and access any console by using a direct connection of some sort to the Dominion SXII.
And they’re just plain faster. A lot faster.
And, considering, they’re not so expensive.
They worked so much better than expected that we pretty much immediately filled up the ports with firewalls and other stuff.
Conclusion
A leap forward in productivity was realized by utilizing Raritn’s Dominion SXII serial port concentrator. Commissioning new security gear has never been esaier…
Intro
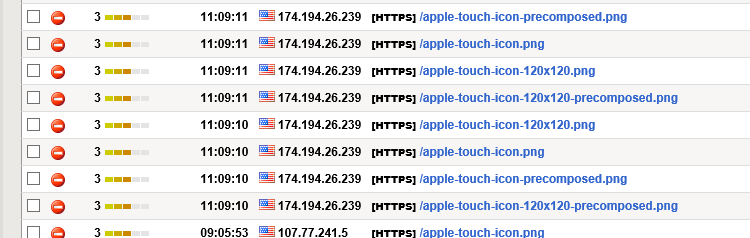
Displaying the ASM event log is slow – it can take minutes on our older equipment. So anything that helps cut out the clutter in the returned log entries may save precious minutes of, e.g., paging to the next screen (also a minute). At some point I realized the logs were mostly filled with complaints about illegal URLs beginning with /apple-touch-icon… So i found a way to suppress those. This is for version 12.1
The problem Typical example from a typical WAF log
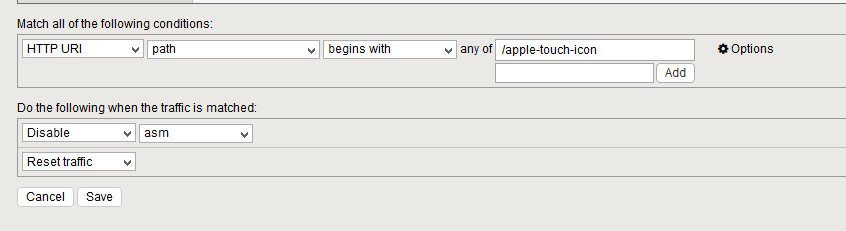
The details LTM policy to suppress those entries
How to edit policy
These are policies in the Local Traffic section. It’s not that intuitive. Clicking on the policy name will give you a read-only view and no evident way to switch to an edit mode. What you do is click on Create Draft. That creates a “draft policy” which you can edit. There you can introduce the rule above. Drag it to the top. Hit Save and publish draft and it should go live.
The best way?
It’s debatable if this is the best way to suppress these. if they come from legitmate devices mistakenly asking for these URLs it’s probably nicer to send them a 404 Not found. An iRule would be required for that.
Conclusion
We show how to suppress annoying ASM log entries saying illegal URL, /apple-touch-icon… on an F5 web application firewall. What is producing these URL attempts I just don’t know at this point. I suspect them to be innocuous.