Trying to upgrade WordPress brings a thicket of problemsDecember, 2014 Update With some tips for making your server POODLE-proof, and 2016 update to deal with OpenSSL Padding Oracle Vulnerability CVE-2016-2107
Intro
We got audited. There’s always something they catch, right? But I actually appreciate the thoroughness of this audit, and I used its findings to learn a little about one of those mystery areas that never seemed to matter until now: ciphers. Now it matters because cipher weakness was the finding!
I had an older piece of Nortel gear which was running SSL. The auditors found that it allows anonymous authentication ciphers. Have you ever heard of such a thing? I hadn’t either! I am far from an expert in this area, but I will attempt an explanation of the implication of this weakness which, by the way, was scored as a “high severity” – the highest on their scale in fact!
Why Anonymous Authentication is a Severe Matter
The briefly stated reason in the finding is that it allows for a Man In the Middle (MITM) attack. I’ve given it some thought and I haven’t figured out what the core issue is. The correct behaviour is for a client to authenticate a server in an SSL session, usually using RSA. If no authentication occurs, a MITM SSL server could be inserted in between client and server, or so they say.
Reproducing the Problem
OK, so we don’t understand the issue, but we do know enough to reproduce their results. That is helpful so we’ll know when we’ve resolved it without going back to the auditors. Our tool of choice is openssl. In theory, you can list the available ciphers in openssl thus:
openssl ciphers -v
And you’ll probably end up with an output looking like this, without the header which I’ve added for convenience:
Cipher Name|SSL Protocol|Key exchange algorithm|Authentication|Encryption algorithm|MAC digest algorithm
DHE-RSA-AES256-SHA SSLv3 Kx=DH Au=RSA Enc=AES(256) Mac=SHA1
DHE-DSS-AES256-SHA SSLv3 Kx=DH Au=DSS Enc=AES(256) Mac=SHA1
AES256-SHA SSLv3 Kx=RSA Au=RSA Enc=AES(256) Mac=SHA1
KRB5-DES-CBC3-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=3DES(168) Mac=MD5
KRB5-DES-CBC3-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=3DES(168) Mac=SHA1
EDH-RSA-DES-CBC3-SHA SSLv3 Kx=DH Au=RSA Enc=3DES(168) Mac=SHA1
EDH-DSS-DES-CBC3-SHA SSLv3 Kx=DH Au=DSS Enc=3DES(168) Mac=SHA1
DES-CBC3-SHA SSLv3 Kx=RSA Au=RSA Enc=3DES(168) Mac=SHA1
DES-CBC3-MD5 SSLv2 Kx=RSA Au=RSA Enc=3DES(168) Mac=MD5
DHE-RSA-AES128-SHA SSLv3 Kx=DH Au=RSA Enc=AES(128) Mac=SHA1
DHE-DSS-AES128-SHA SSLv3 Kx=DH Au=DSS Enc=AES(128) Mac=SHA1
AES128-SHA SSLv3 Kx=RSA Au=RSA Enc=AES(128) Mac=SHA1
RC2-CBC-MD5 SSLv2 Kx=RSA Au=RSA Enc=RC2(128) Mac=MD5
KRB5-RC4-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=RC4(128) Mac=MD5
KRB5-RC4-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=RC4(128) Mac=SHA1
RC4-SHA SSLv3 Kx=RSA Au=RSA Enc=RC4(128) Mac=SHA1
RC4-MD5 SSLv3 Kx=RSA Au=RSA Enc=RC4(128) Mac=MD5
RC4-MD5 SSLv2 Kx=RSA Au=RSA Enc=RC4(128) Mac=MD5
KRB5-DES-CBC-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=DES(56) Mac=MD5
KRB5-DES-CBC-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=DES(56) Mac=SHA1
EDH-RSA-DES-CBC-SHA SSLv3 Kx=DH Au=RSA Enc=DES(56) Mac=SHA1
EDH-DSS-DES-CBC-SHA SSLv3 Kx=DH Au=DSS Enc=DES(56) Mac=SHA1
DES-CBC-SHA SSLv3 Kx=RSA Au=RSA Enc=DES(56) Mac=SHA1
DES-CBC-MD5 SSLv2 Kx=RSA Au=RSA Enc=DES(56) Mac=MD5
EXP-KRB5-RC2-CBC-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=RC2(40) Mac=MD5 export
EXP-KRB5-DES-CBC-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=DES(40) Mac=MD5 export
EXP-KRB5-RC2-CBC-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=RC2(40) Mac=SHA1 export
EXP-KRB5-DES-CBC-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=DES(40) Mac=SHA1 export
EXP-EDH-RSA-DES-CBC-SHA SSLv3 Kx=DH(512) Au=RSA Enc=DES(40) Mac=SHA1 export
EXP-EDH-DSS-DES-CBC-SHA SSLv3 Kx=DH(512) Au=DSS Enc=DES(40) Mac=SHA1 export
EXP-DES-CBC-SHA SSLv3 Kx=RSA(512) Au=RSA Enc=DES(40) Mac=SHA1 export
EXP-RC2-CBC-MD5 SSLv3 Kx=RSA(512) Au=RSA Enc=RC2(40) Mac=MD5 export
EXP-RC2-CBC-MD5 SSLv2 Kx=RSA(512) Au=RSA Enc=RC2(40) Mac=MD5 export
EXP-KRB5-RC4-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=RC4(40) Mac=MD5 export
EXP-KRB5-RC4-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=RC4(40) Mac=SHA1 export
EXP-RC4-MD5 SSLv3 Kx=RSA(512) Au=RSA Enc=RC4(40) Mac=MD5 export
EXP-RC4-MD5 SSLv2 Kx=RSA(512) Au=RSA Enc=RC4(40) Mac=MD5 export |
Cipher Name|SSL Protocol|Key exchange algorithm|Authentication|Encryption algorithm|MAC digest algorithm
DHE-RSA-AES256-SHA SSLv3 Kx=DH Au=RSA Enc=AES(256) Mac=SHA1
DHE-DSS-AES256-SHA SSLv3 Kx=DH Au=DSS Enc=AES(256) Mac=SHA1
AES256-SHA SSLv3 Kx=RSA Au=RSA Enc=AES(256) Mac=SHA1
KRB5-DES-CBC3-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=3DES(168) Mac=MD5
KRB5-DES-CBC3-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=3DES(168) Mac=SHA1
EDH-RSA-DES-CBC3-SHA SSLv3 Kx=DH Au=RSA Enc=3DES(168) Mac=SHA1
EDH-DSS-DES-CBC3-SHA SSLv3 Kx=DH Au=DSS Enc=3DES(168) Mac=SHA1
DES-CBC3-SHA SSLv3 Kx=RSA Au=RSA Enc=3DES(168) Mac=SHA1
DES-CBC3-MD5 SSLv2 Kx=RSA Au=RSA Enc=3DES(168) Mac=MD5
DHE-RSA-AES128-SHA SSLv3 Kx=DH Au=RSA Enc=AES(128) Mac=SHA1
DHE-DSS-AES128-SHA SSLv3 Kx=DH Au=DSS Enc=AES(128) Mac=SHA1
AES128-SHA SSLv3 Kx=RSA Au=RSA Enc=AES(128) Mac=SHA1
RC2-CBC-MD5 SSLv2 Kx=RSA Au=RSA Enc=RC2(128) Mac=MD5
KRB5-RC4-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=RC4(128) Mac=MD5
KRB5-RC4-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=RC4(128) Mac=SHA1
RC4-SHA SSLv3 Kx=RSA Au=RSA Enc=RC4(128) Mac=SHA1
RC4-MD5 SSLv3 Kx=RSA Au=RSA Enc=RC4(128) Mac=MD5
RC4-MD5 SSLv2 Kx=RSA Au=RSA Enc=RC4(128) Mac=MD5
KRB5-DES-CBC-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=DES(56) Mac=MD5
KRB5-DES-CBC-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=DES(56) Mac=SHA1
EDH-RSA-DES-CBC-SHA SSLv3 Kx=DH Au=RSA Enc=DES(56) Mac=SHA1
EDH-DSS-DES-CBC-SHA SSLv3 Kx=DH Au=DSS Enc=DES(56) Mac=SHA1
DES-CBC-SHA SSLv3 Kx=RSA Au=RSA Enc=DES(56) Mac=SHA1
DES-CBC-MD5 SSLv2 Kx=RSA Au=RSA Enc=DES(56) Mac=MD5
EXP-KRB5-RC2-CBC-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=RC2(40) Mac=MD5 export
EXP-KRB5-DES-CBC-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=DES(40) Mac=MD5 export
EXP-KRB5-RC2-CBC-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=RC2(40) Mac=SHA1 export
EXP-KRB5-DES-CBC-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=DES(40) Mac=SHA1 export
EXP-EDH-RSA-DES-CBC-SHA SSLv3 Kx=DH(512) Au=RSA Enc=DES(40) Mac=SHA1 export
EXP-EDH-DSS-DES-CBC-SHA SSLv3 Kx=DH(512) Au=DSS Enc=DES(40) Mac=SHA1 export
EXP-DES-CBC-SHA SSLv3 Kx=RSA(512) Au=RSA Enc=DES(40) Mac=SHA1 export
EXP-RC2-CBC-MD5 SSLv3 Kx=RSA(512) Au=RSA Enc=RC2(40) Mac=MD5 export
EXP-RC2-CBC-MD5 SSLv2 Kx=RSA(512) Au=RSA Enc=RC2(40) Mac=MD5 export
EXP-KRB5-RC4-MD5 SSLv3 Kx=KRB5 Au=KRB5 Enc=RC4(40) Mac=MD5 export
EXP-KRB5-RC4-SHA SSLv3 Kx=KRB5 Au=KRB5 Enc=RC4(40) Mac=SHA1 export
EXP-RC4-MD5 SSLv3 Kx=RSA(512) Au=RSA Enc=RC4(40) Mac=MD5 export
EXP-RC4-MD5 SSLv2 Kx=RSA(512) Au=RSA Enc=RC4(40) Mac=MD5 export
I’m not going to explain all those headers because, umm, I don’t know myself. Perhaps in a later or updated posting. The point I want to make here is that as complete as this listing appears, it’s really incomplete. openssl actually supports additional ciphers as well, as I learned by combining information from the audit, plus Nortel’s documentation. In particular Nortel mentions additional ciphers such as these:
ADH-AES256-SHA SSLv3 DH, NONE AES (256) SHA1
ADH-DES-CBC3-SHA SSLv3 DH, NONE 3DES (168) SHA1
I singled these out because the “NONE” means anonymous authentication – the subject of the audit finding! Note that these ciphers were not present in the openssl listing. So now I know Nortel potentially supports anonymous (also called NULL) authentication. There remains the question of whether my specific implementation supports it. Of course the audit says it does, but I want to have sufficient expertise to verify for myself. So, try this:
openssl s_client -cipher ADH-DES-CBC3-SHA -connect IP_of_Nortel_server:443 |
openssl s_client -cipher ADH-DES-CBC3-SHA -connect IP_of_Nortel_server:443
I get:
---
no peer certificate available
---
No client certificate CA names sent
---
SSL handshake has read 411 bytes and written 239 bytes
---
New, TLSv1/SSLv3, Cipher is ADH-DES-CBC3-SHA
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : ADH-DES-CBC3-SHA
Session-ID: 30F1375839B8CFB508CDEFC9FBE4A5BF2D5CE240038DFF8CC514607789CCEDD5
Session-ID-ctx:
Master-Key: B2374E609874D1015DC55BEAA0289310445BAFF65956908A497E5C51DF1301D68CC47AB395DDFEB9A1C77B637A4D306F
Key-Arg : None
Krb5 Principal: None
Start Time: 1317132292
Timeout : 300 (sec)
Verify return code: 0 (ok)
--- |
---
no peer certificate available
---
No client certificate CA names sent
---
SSL handshake has read 411 bytes and written 239 bytes
---
New, TLSv1/SSLv3, Cipher is ADH-DES-CBC3-SHA
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : ADH-DES-CBC3-SHA
Session-ID: 30F1375839B8CFB508CDEFC9FBE4A5BF2D5CE240038DFF8CC514607789CCEDD5
Session-ID-ctx:
Master-Key: B2374E609874D1015DC55BEAA0289310445BAFF65956908A497E5C51DF1301D68CC47AB395DDFEB9A1C77B637A4D306F
Key-Arg : None
Krb5 Principal: None
Start Time: 1317132292
Timeout : 300 (sec)
Verify return code: 0 (ok)
---
You see that it listed the Cipher as the one I requested, ADH-DES-CBC3-SHA. Further note that no certificate names are sent. Normally they are. To see if my method is correct, let’s try one of Google’s secure servers. Certainly Google will not permit NULL authentication if it’s a bad practice:
openssl s_client -cipher aNULL -connect 74.125.67.84:443
produces this output:
21390:error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failure:s23_clnt.c:583: |
21390:error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failure:s23_clnt.c:583:
Google does not permit this cipher! As a control, let’s use openssl without specifying a specific cipher against both servers. First, the Nortel server:
openssl s_client -connect IP_of_Nortel_server:443
produces some long output, which spits out the sever certificates, followed by this:
New, TLSv1/SSLv3, Cipher is DHE-RSA-AES256-SHA
Server public key is 2048 bit
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : DHE-RSA-AES256-SHA
Session-ID: 6D1A4383F3DBF4C14007220715ECCFB83D91C524624ACE641843880291200AE2
Session-ID-ctx:
Master-Key: BE3FB61B169F497A922A9A172D36A4BB15C26074021D7F22D125875980070E157EDA3100572F927B427B03BF81543E1A
Key-Arg : None
Krb5 Principal: None
Start Time: 1317132982
Timeout : 300 (sec)
Verify return code: 0 (ok) |
New, TLSv1/SSLv3, Cipher is DHE-RSA-AES256-SHA
Server public key is 2048 bit
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : DHE-RSA-AES256-SHA
Session-ID: 6D1A4383F3DBF4C14007220715ECCFB83D91C524624ACE641843880291200AE2
Session-ID-ctx:
Master-Key: BE3FB61B169F497A922A9A172D36A4BB15C26074021D7F22D125875980070E157EDA3100572F927B427B03BF81543E1A
Key-Arg : None
Krb5 Principal: None
Start Time: 1317132982
Timeout : 300 (sec)
Verify return code: 0 (ok)
So you see client and server agreed to use the cipher DHE-RSA-AES256-SHA, which from our table uses RSA authentication. And hitting Google again without the ciphers argument we get this:
New, TLSv1/SSLv3, Cipher is RC4-SHA
Server public key is 1024 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : RC4-SHA
Session-ID: 236FDF47DA752E768E7EE32DA10103F1CAD513E9634F075BE8773090A2E7A995
Session-ID-ctx:
Master-Key: 39212DE0E3A98943C441287227CB1425AE11CCA277EFF6F8AF83DA267AB256B5A8D94A6573DFD54FB1C9BF82EA302494
Key-Arg : None
Krb5 Principal: None
Start Time: 1317133483
Timeout : 300 (sec)
Verify return code: 0 (ok)
--- |
New, TLSv1/SSLv3, Cipher is RC4-SHA
Server public key is 1024 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : RC4-SHA
Session-ID: 236FDF47DA752E768E7EE32DA10103F1CAD513E9634F075BE8773090A2E7A995
Session-ID-ctx:
Master-Key: 39212DE0E3A98943C441287227CB1425AE11CCA277EFF6F8AF83DA267AB256B5A8D94A6573DFD54FB1C9BF82EA302494
Key-Arg : None
Krb5 Principal: None
Start Time: 1317133483
Timeout : 300 (sec)
Verify return code: 0 (ok)
---
So in this case it is successful, though it has chosen a different cipher from Nortel, namely RC4-SHA. But we can look it up and see that it’s a cipher which uses RSA authentication. Cool.
So we’ve “proven” all our assertions thus far. Now how do we fix Nortel? The Nortel GUI lists the ciphers as
ALL@STRENGTH
Pardon me? It turns out there are cipher groupings denoted by aliases, and you can combine the aliases into a cipher list.
ALL – means all cipher suites
EXPORT – includes cipher suites using 40 or 56 bit encryption
aNULL – cipher suites that do not offer authentication
eNULL – cipher suites that have no encryption whatsoever (disabled by default in Nortel)
STRENGTH – is at the end of the list and sorts the list in order of encryption algorithm key length
List operators are:
! – permanently deletes the cipher from the list.
+ – moves the cipher to the end of the list
: – separator of cipher strings
aNULL is a subset of ALL, and that’s what’s killing us. Putting all this together, the cipher I tried in place of ALL@STRENGTH is:
ALL:!EXPORT:!aNULL@STRENGTH
In this way I prevent NULL authentication and remove the weaker export ciphers. As soon as I applied this cipher list, I tested it. Yup – works. I can no longer hit it by using anonymous authentication:
openssl s_client -cipher aNULL -connect IP_of_Nortel_server:443
produces
2465:error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failure:s23_clnt.c:583: |
2465:error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failure:s23_clnt.c:583:
and using cipher eNULL produces the same error. To make sure I’m sending a cipher which openssl understands, I tried a nonsense cipher as a control – one that I know does not exist:
openssl s_client -cipher eddNULL -connect IP_of_Nortel_server:443
That gives a different error:
error setting cipher list
2482:error:1410D0B9:SSL routines:SSL_CTX_set_cipher_list:no cipher match:ssl_lib.c:1188:
providing assurance that aNULL and eNULL are cipher families understood and supported by openssl, and that I have done the hardening correctly!
Now you can probably count the number of people still using Nortel gear with your two hands! But this discussion, obviously, has wider applicability. In Apache/mod_ssl there is an SSLCipherSuite line where you specify a cipher list. The auditor’s recommendation is more detailed than what I tried. They suggest the list ALL:!aNULL:!ADH:!eNULL:!LOW:!EXP:RC4+RSA:+HIGH:+MEDIUM
October 2014 Update
Well, now we’ve encountered the SSLv3 vulnerability POODLE, which compels us to forcibly eliminate use of SSLv3 on all servers and clients. Let’s say we updated our clients to require use of TLS. How do we gain confidence the update worked? Set one of our servers to not use TLS! Here’s how I did that on a BigIP server:
I ran a quick test using openssl s_client -connect server:443 as above, and got what I was looking for:
...
SSL handshake has read 3038 bytes and written 479 bytes
---
New, TLSv1/SSLv3, Cipher is AES256-SHA
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : SSLv3
Cipher : AES256-SHA
... |
...
SSL handshake has read 3038 bytes and written 479 bytes
---
New, TLSv1/SSLv3, Cipher is AES256-SHA
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : SSLv3
Cipher : AES256-SHA
...
Note the protocol says SSLv3 and not TLS.
Turning off SSLv3 to deal with POODLE
So that is normally exactly the opposite of what you want to do to turn off SSLv3 – that was just to run a control test. Here’s what to do to turn off SSLv3 on a BigIP:
DEFAULT:!RC4:!SSLv3:@STRENGTH |
DEFAULT:!RC4:!SSLv3:@STRENGTH
OK, yes, RC4 is a discredited cipher so disable that as well. Most clients (but not all) will be able to work with a server which is set like this.
Apache and POODLE prevention
Well, I went to the Qualys site and found I was not exactly eating my own dogfood! My own server was considered vulnerable to POODLE, supported weak protocols, etc and only scored a “C.” 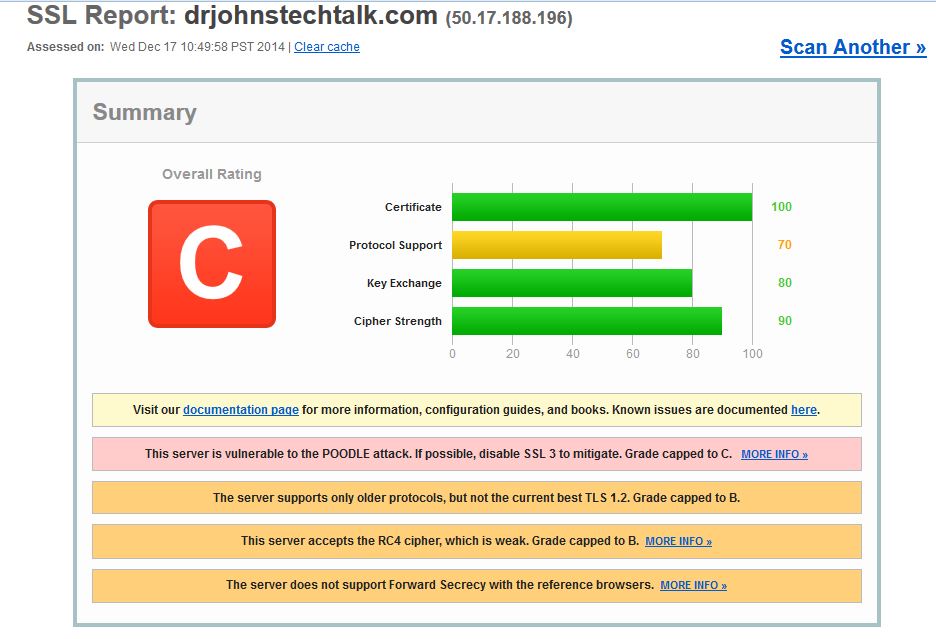 Determined to incorporate more modern approaches to my apache server settings and stealing from others, I improved things dramatically by throwing these additional configuration lines into my apache configuration:
Determined to incorporate more modern approaches to my apache server settings and stealing from others, I improved things dramatically by throwing these additional configuration lines into my apache configuration:
(the following apache configuration lines are deprecated – see further down below)
...
# lock things down to get a better score from Qualys - DrJ 12/17/14
# 4 possible values: All, SSLv2, SSLv3, TLSv1. Allow TLS only:
SSLProtocol all -SSLv2 -SSLv3
SSLCipherSuite ALL:!aNULL:!eNULL:!SSLv2:!LOW:!EXP:!RC4:!MD5:@STRENGTH
... |
...
# lock things down to get a better score from Qualys - DrJ 12/17/14
# 4 possible values: All, SSLv2, SSLv3, TLSv1. Allow TLS only:
SSLProtocol all -SSLv2 -SSLv3
SSLCipherSuite ALL:!aNULL:!eNULL:!SSLv2:!LOW:!EXP:!RC4:!MD5:@STRENGTH
...
The results after strengthening apache configuration
I now get an “A-” and am not supporting any weak ciphers! Yeah! 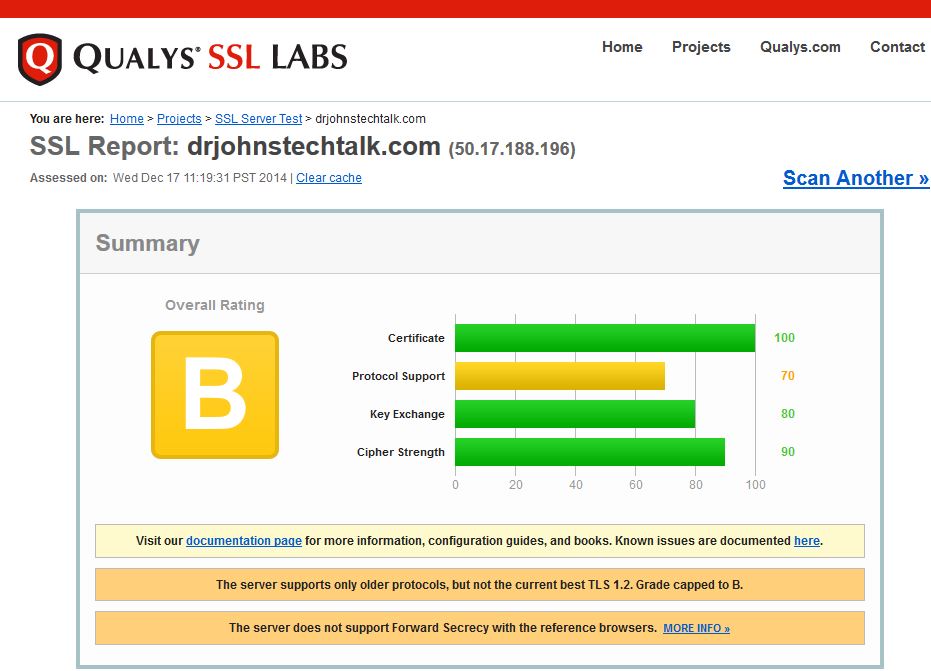 It’s because those configuration lines mean that I explicitly don’t permit SSLv2/v3 or the weak RC4 cipher. I need to study to determine if I should support TLSv1.2 and forward secrecy to go to the best possible score – an “A.” (Months later) Well now I do get an A and I’m not exactly sure why the improved score.
It’s because those configuration lines mean that I explicitly don’t permit SSLv2/v3 or the weak RC4 cipher. I need to study to determine if I should support TLSv1.2 and forward secrecy to go to the best possible score – an “A.” (Months later) Well now I do get an A and I’m not exactly sure why the improved score.
BREACH prevention
After all the above measures the Digicert certificate inspector I am evaluating says my drjohnstechtalk site is vulnerable to the Breach attack. From my reading the only practical solution, at least for my case, is to upgrade from apache 2.2 to apache 2.4. Hence the Herculean efforts to compile apache 2.4 as detailed in this blog post. My preliminary finding is that without changing the SSL configuration at all apache 2.4 does not show a vulnerability to BREACH. But upon digging further, it has to do with the absence of the use of compression in apache 2.4 and I’m not yet sure why it isn’t being used!
2016 Update for CVE-2016-2107
I was going to check to see if my current score at SSLLabs is an A-, and what I can do to boost it to an A. Well, I got an F! I guess the lesson here is to conduct periodic tests. Things change!
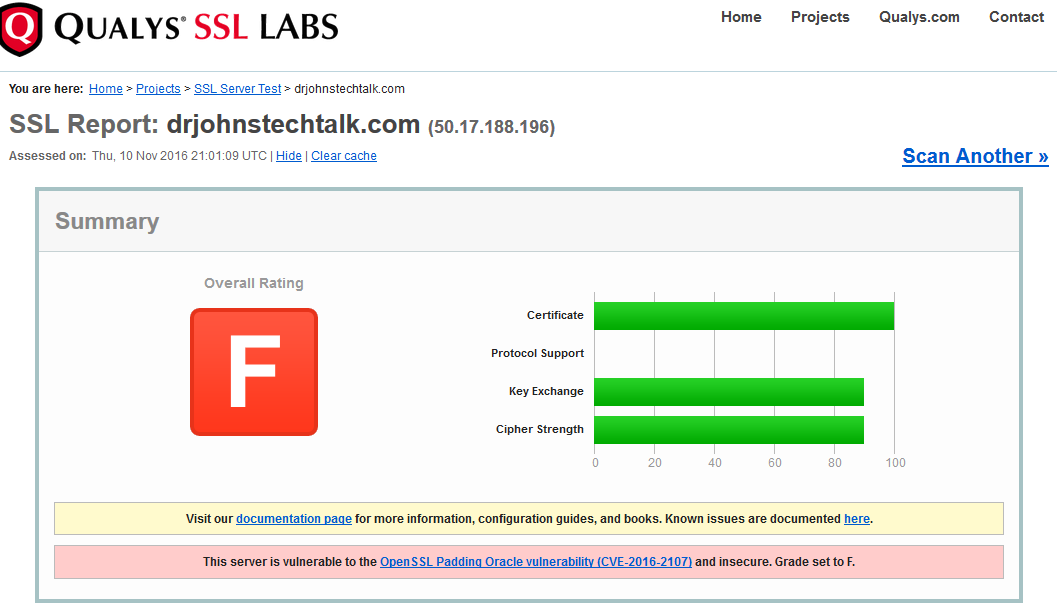
I saw from descriptions elsewhere that my version of openssl, openssl-1.0.1e-30.el6.11, was likely out-of-date. So I looked at my version of openssl on my CentOS server:
$ sudo rpm ‐qa|grep openssl
and updated it:
$ sudo yum update openssl‐1.0.1e‐30.el6.11
Now (11/11/16) my version is openssl-1.0.1e-48.el6_8.3.
Would this upgrade suffice without any further action?
Some background. I had compiled – with some difficulty – my own version of apache version 2.4: https://drjohnstechtalk.com/blog/2015/07/compiling-apache24-on-centos/.
I was pretty sure that my apache dynamically links to the openssl libraries by virtue of the lack of their appearance as listed compiled-in modules:
$ /usr/local/apache24/bin/httpd ‐l
Compiled in modules:
core.c
mod_so.c
http_core.c
prefork.c |
Compiled in modules:
core.c
mod_so.c
http_core.c
prefork.c
Simply installing these new openssl libraries did not do the trick immediately. So the next step was to restart apache. Believe it or not, that did it!
Going back to the full ssllabs test, I currently get a solid A. Yeah!
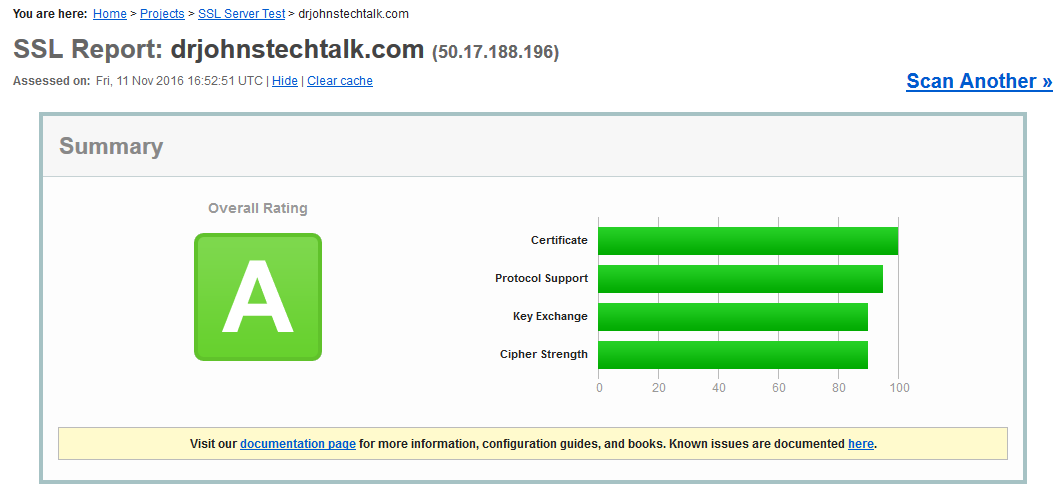
In the spirit of let’s learn something here beyond what the immediate problem requires, I learned then that indeed the openssl libraries were dynamically linked to my apache version. Moreover, I learned that dynamic linking, despite the name, still has a static aspect. The shared object library must be read in at process creation time and perhaps only occasionally re-read afterwards. But it is not read with every single invocation, which I suppose makes sense form a performance point-of-view.
2016 apache 2.4 SSL config section
For the record…
...
SSLProtocol all -SSLv2 -SSLv3
# it used to be this simple
#SSLCipherSuite ALL:!aNULL:!eNULL:!SSLv2:!LOW:!EXP:!RC4:!MD5:@STRENGTH
# Now it isn't - DrJ 6/2/15. Based on SSL Labs https://weakdh.org/sysadmin.html - DrJ 6/2/15
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA
SSLHonorCipherOrder on
... |
...
SSLProtocol all -SSLv2 -SSLv3
# it used to be this simple
#SSLCipherSuite ALL:!aNULL:!eNULL:!SSLv2:!LOW:!EXP:!RC4:!MD5:@STRENGTH
# Now it isn't - DrJ 6/2/15. Based on SSL Labs https://weakdh.org/sysadmin.html - DrJ 6/2/15
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA
SSLHonorCipherOrder on
...
How to see what ciphers your browser supports
Your best bet is the SSLLABS.com web site. Go to Test my Browser.
University of Hannover offers this site. Just go this page. But lately I noticed that it does not list ciphers using CBC whereas the SSLlabs site does. So SSLlabs provides a more accurate answer.
2017 update for PCI compliance
Of course this article is ancient and I hesitate to further complicate it, but I also don’t want to tear it down. Anyway, for PCI compliance you’ll soon need to drop 3DES ciphers (3DES is pronounced “triple-DES” if you ever need to read it aloud). I have this implemented on F5 BigIP devices. I have set the ciphers to:
and this did the trick. Here’s how to see what effect that has from the BigIP command line:
$ tmm ‐‐clientciphers ‘DEFAULT:!DHE:!3DES:+RSA’
ID SUITE BITS PROT METHOD CIPHER MAC KEYX
0: 49200 ECDHE-RSA-AES256-GCM-SHA384 256 TLS1.2 Native AES-GCM SHA384 ECDHE_RSA
1: 49199 ECDHE-RSA-AES128-GCM-SHA256 128 TLS1.2 Native AES-GCM SHA256 ECDHE_RSA
2: 49192 ECDHE-RSA-AES256-SHA384 256 TLS1.2 Native AES SHA384 ECDHE_RSA
3: 49172 ECDHE-RSA-AES256-CBC-SHA 256 TLS1 Native AES SHA ECDHE_RSA
4: 49172 ECDHE-RSA-AES256-CBC-SHA 256 TLS1.1 Native AES SHA ECDHE_RSA
5: 49172 ECDHE-RSA-AES256-CBC-SHA 256 TLS1.2 Native AES SHA ECDHE_RSA
6: 49191 ECDHE-RSA-AES128-SHA256 128 TLS1.2 Native AES SHA256 ECDHE_RSA
7: 49171 ECDHE-RSA-AES128-CBC-SHA 128 TLS1 Native AES SHA ECDHE_RSA
8: 49171 ECDHE-RSA-AES128-CBC-SHA 128 TLS1.1 Native AES SHA ECDHE_RSA
9: 49171 ECDHE-RSA-AES128-CBC-SHA 128 TLS1.2 Native AES SHA ECDHE_RSA
10: 157 AES256-GCM-SHA384 256 TLS1.2 Native AES-GCM SHA384 RSA
11: 156 AES128-GCM-SHA256 128 TLS1.2 Native AES-GCM SHA256 RSA
12: 61 AES256-SHA256 256 TLS1.2 Native AES SHA256 RSA
13: 53 AES256-SHA 256 TLS1 Native AES SHA RSA
14: 53 AES256-SHA 256 TLS1.1 Native AES SHA RSA
15: 53 AES256-SHA 256 TLS1.2 Native AES SHA RSA
16: 53 AES256-SHA 256 DTLS1 Native AES SHA RSA
17: 60 AES128-SHA256 128 TLS1.2 Native AES SHA256 RSA
18: 47 AES128-SHA 128 TLS1 Native AES SHA RSA
19: 47 AES128-SHA 128 TLS1.1 Native AES SHA RSA
20: 47 AES128-SHA 128 TLS1.2 Native AES SHA RSA
21: 47 AES128-SHA 128 DTLS1 Native AES SHA RSA |
ID SUITE BITS PROT METHOD CIPHER MAC KEYX
0: 49200 ECDHE-RSA-AES256-GCM-SHA384 256 TLS1.2 Native AES-GCM SHA384 ECDHE_RSA
1: 49199 ECDHE-RSA-AES128-GCM-SHA256 128 TLS1.2 Native AES-GCM SHA256 ECDHE_RSA
2: 49192 ECDHE-RSA-AES256-SHA384 256 TLS1.2 Native AES SHA384 ECDHE_RSA
3: 49172 ECDHE-RSA-AES256-CBC-SHA 256 TLS1 Native AES SHA ECDHE_RSA
4: 49172 ECDHE-RSA-AES256-CBC-SHA 256 TLS1.1 Native AES SHA ECDHE_RSA
5: 49172 ECDHE-RSA-AES256-CBC-SHA 256 TLS1.2 Native AES SHA ECDHE_RSA
6: 49191 ECDHE-RSA-AES128-SHA256 128 TLS1.2 Native AES SHA256 ECDHE_RSA
7: 49171 ECDHE-RSA-AES128-CBC-SHA 128 TLS1 Native AES SHA ECDHE_RSA
8: 49171 ECDHE-RSA-AES128-CBC-SHA 128 TLS1.1 Native AES SHA ECDHE_RSA
9: 49171 ECDHE-RSA-AES128-CBC-SHA 128 TLS1.2 Native AES SHA ECDHE_RSA
10: 157 AES256-GCM-SHA384 256 TLS1.2 Native AES-GCM SHA384 RSA
11: 156 AES128-GCM-SHA256 128 TLS1.2 Native AES-GCM SHA256 RSA
12: 61 AES256-SHA256 256 TLS1.2 Native AES SHA256 RSA
13: 53 AES256-SHA 256 TLS1 Native AES SHA RSA
14: 53 AES256-SHA 256 TLS1.1 Native AES SHA RSA
15: 53 AES256-SHA 256 TLS1.2 Native AES SHA RSA
16: 53 AES256-SHA 256 DTLS1 Native AES SHA RSA
17: 60 AES128-SHA256 128 TLS1.2 Native AES SHA256 RSA
18: 47 AES128-SHA 128 TLS1 Native AES SHA RSA
19: 47 AES128-SHA 128 TLS1.1 Native AES SHA RSA
20: 47 AES128-SHA 128 TLS1.2 Native AES SHA RSA
21: 47 AES128-SHA 128 DTLS1 Native AES SHA RSA
2018 update and comment about PCI compliance
I tried to give the owners of e1st.smapply.org a hard time for supporting such a limited set of ciphersuites – essentially only the latest thing (which you can see yourself by running it through sslabs.com): TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384. If I run this through SSL interception on a Symantec proxy with an older image, 6.5.10.4 from June, 2017, that ciphersuite isn’t present! I had to upgrade to 6.5.10.7 from October 2017, then it was fine. But getting back to the rationale, they told me they have future-proofed their site for the new requirements of PCI and they would not budge and support other ciphersuites (forcing me to upgrade).
Another site in that same situation is https://shop-us.bestunion.com/. I don’t know if it’s a misconception on the part of the site administrators or if they’re onto something. I’ll know more when I update my own PCI site to meet the latest requirements.
2020 Update
In this year they are trying to phase out TLS v 1.0 and v 1.1 in favor of TLS v 1.2 or v 1.3. Now my web site’s grade is capped at a B because it still supports those older protocols.
Additional resources and references
As you see from the above openssl is a very useful tool, and there’s lots more you can do with it. Some of my favorite openssl commands are documented in this blog post.
A great site for testing the strength of any web site’s SSL setup, vulnerability to POODLE, etc is this Qualys SSL Labs testing site. No obnoxious ads either. A much more basic one is https://www.websiteplanet.com/webtools/ssl-checker/ SSLlabs is much more complete, but it only works on web sites running on the default port 443. websiteplanet is more about whether your certificate is installed properly and such.
Need to know what ciphers your browser supports? Qualys SSL Labs again to the rescue: https://www.ssllabs.com/ssltest/viewMyClient.html shows you all your browser’s supported ciphers. However, the results may not be reliable if you are using a proxy.
An excellent article explaining in technical terms what the problem with SSLv3 actually is is posted by, who else, Paul Ducklin the Sophos NakedSecurity blogger.
This RFC discusses why TLS v 1.2 or higher is preferred over TLS 1.0 or TLS 1.1: https://tools.ietf.org/html/rfc7525
The Digicert certificate inspector includes a vulnerability assessment as well. It seems useful.
Want a readily understandable explanation of what CBC (Cipher Block Chaining) means? It isn’t too hard to understand. This is an excellent article from Sophos’ Paul Ducklin. It also explains the Sweet32 attack.
An equally greatly detailed explanation of the openssl padding oracle vulnerability is here. https://blog.cloudflare.com/yet-another-padding-oracle-in-openssl-cbc-ciphersuites/
A fast dedicated test for CVE-2016-2107, the oracle padding vulnerability: https://filippo.io/CVE-2016-2107/. SSLlabs test is more thorough – it checks for everything – but much slower.
Compiling apache version 2.4 is described here: https://drjohnstechtalk.com/blog/2015/07/compiling-apache24-on-centos/ and more recently, here: https://drjohnstechtalk.com/blog/2020/04/trying-to-upgrade-wordpress-brings-a-thicket-of-problems/
If you want to see how your browser deals with different certificate issues (expired, bad chained CERT) as well different ciphers, this has a test case for all of that. This is very useful for testing SSL Interception product behavior. https://badssl.com/
Aimed at F5 admins, but a really good review for anyone about sipher suites, SSL vs TLS and all that is this F5 document. I recommend it for anyone getting started.
This site will never run SSL! This can be useful when you are trying to login to a hotel’s guest WiFi, which may not be capable of intercepting SSL traffic to force you to heir sign-on page: http://neverssl.com/.
Want to test if a web site requires client certificates, e.g., for authentication? This post has some suggestions.
Conclusion
We now have some idea of what those kooky cipher strings actually mean and our eyes don’t gloss over when we encounter them! Plus, we have made our Nortel gear more secure by deploying a cipher string which disallows anonymous authentication.
It seems SSL exploits have been discovered at reliable pace since this article was first published. It’s best to check your servers running SSL at least twice a year or better every quarter using the SSLlabs tool.