It’s a little hard to find this information on the Internet, so I’m amplifying the correct answer here by using my blog.
The details
I’m not super-competent with MIBs and such, but I manage for my purposes with my basic understanding. I have access to an F5 bigip with various IPSEC tunnels on it. I want to use Zabbix to check the status of those tunnels. So I do an SMPwalk like this:
snmpwalk -v3 … -c public 127.0.0.1 F5-BIGIP-SYSTEM-MIB::sysIpsecSpdStatTunnelState
which produces output like this line:
F5-BIGIP-SYSTEM-MIB::sysIpsecSpdStatTunnelState.”/Common/tunnel-01″.58401 = STRING: up
But I cannot take that as it is and use it in an snmpget like this:
snmpget -v3 … -c public 127.0.0.1 F5-BIGIP-SYSTEM-MIB::sysIpsecSpdStatTunnelState.”/Common/tunnel-01″.58401
That produces an error like this:
Unknown Object Identifier (Index out of range: /Common/tunnel-01 (sysIpsecSpdStatTrafficSelectorName))
So we need to convert the string into a numeric OID. But how?
The answer
Use the -On switch as an additional argument in your snmpwalk.
You will get a scary long OID, but it will at least be numeric.
Gonig further
You can then deconstruct the response and reconstitute the section at the beginning with a nice name. For my F5 example
.1.3.6.1.4.1.3375.2.1.2.17.1.3.1.14
becomes
F5-BIGIP-SYSTEM-MIB::sysIpsecSpdStatBytes
I think. Then preserve the following digits as is.
Conclusion
We have shown how to output a numeric OID from an snmpwalk. This, specifically, is sueful in converting a string embedded in the output into a numeric OID, which may then be used by other SNMP applications such as Zabbix which may or may not have the MIB file loaded. The secret is simply to use the -On switch in snmpwalk.
The headline says it all. I got my shiny brand new Verizon hotspot from Walmart. I managed to activate it and add it to my Verizon account (not super easy, but after a few stumbles it did work.) I tried it out my home PC – works fine. I tried it out on my work PC. No good. My Global Protect connection was unstable. It connects for about a minute, then disconnects, then connects, etc. Basically unusable.
The details
I have heard of possible problem with the GP client (version 5.2.11) and IPv6. So I looked to see if this hotspot could be handing out IPv6 info. Yes. It is. But is that really making a difference? I concocted a simple test. I disabled IPv6 on my Wi-Fi adapter, then re-tested the GP client. The connection was smooth as glass! No disconnects!
Disable ipv6 on your Wi-Fi adapter
Bring up a powershell as administrator. Then:
get-netadapterbinding -componentid ms_tcpip6
will show you the current state of ipv6 on your adapters.
But, having done all that, I can only occasionally connect to GP. It seems to work slightly better at night. ipv6 does not seem to be the sole hiccup. No idea what the recipe for reliable success is. If I ever learn it I will publish it. Meanwhile, my phone’s hotspot, also VErizon, also handing out ipv6 info, usually permits me to connect to GP. It’s hard to see the difference.
Conclusion
The Verizon Airspeed Hotspot sends out a mix of IPv6 and IPv4 info to dhcp clients. Palo Alto Networks’ Global Protect client does not play well with that setup and wil not have a stable connection.
I do not think there is a way to disable IPv6 on the hotspot. However, for those with admin access it can be disabled on a Windows PC. And then GP will work just fine. Or not.
Oh, and by the way, otherwise the Airspeed works well and is an adequate solution where you need a good reliable hotspot. Well, in fact, don’t expect reliability like you have from a wired connection. After a couple hours, all users just got dropped for no apparent reason whatsoever.
I’ve been reliable running ISC’s BIND server for eons. Recently I had a problem getting my slave servers updated after a change to the primary master. What was going on there?
The details
This was truly a team effort. I saw that the zone file had differing serial numbers on the master versus the slave servers. My attempts to update via an rndc refresh zone was having no effect.
So I tried a zone transfer by hand: dig axfr drjohnstechtalk.com @50.17.188.196
That timed out!
Yet, regular dns qeuries went through fine: dig ns drjohnstechtakl.com @50.17.188.196
I thought about it and remembered zone transfers use TCP whereas standard queries use UDP. So I tried a TCP-based simple query: dig +tcp ns drjohnstechtalk.com @50.17.188.196. It timed out!
So of course one suspects the firewall, which is reasonable enough. And when I looked at the firewal I found some funny drops, though i cuoldn’t line them up exactly with my failed tests. But I’m not a firewall expert; I just muddle through.
The next day someone from the DNS group asked how local queries behaved? Hmm. never tried that. So I tried it: dig +tcp ns drjohnstechtalk.com @localhost. That timed out as well! That was a brilliant suggestion as we now could eliminate the firewall and all that complexity from the equation. Because I had tried to do packet traces on two different machines at the same time and line up the results. It wasn’t easy.
The whole issue was very concerning to us because we feared our secondaries would be unable to pudate their slave zones and ultimately time them out. The result would be devastating.
We have support, fortunately. A company that hearkens frmo the good old days, with real subject matter experts. But they’re extremely busy. We did not get a suggestion for a couple weeks. But eventually we did. They had seen this once before.
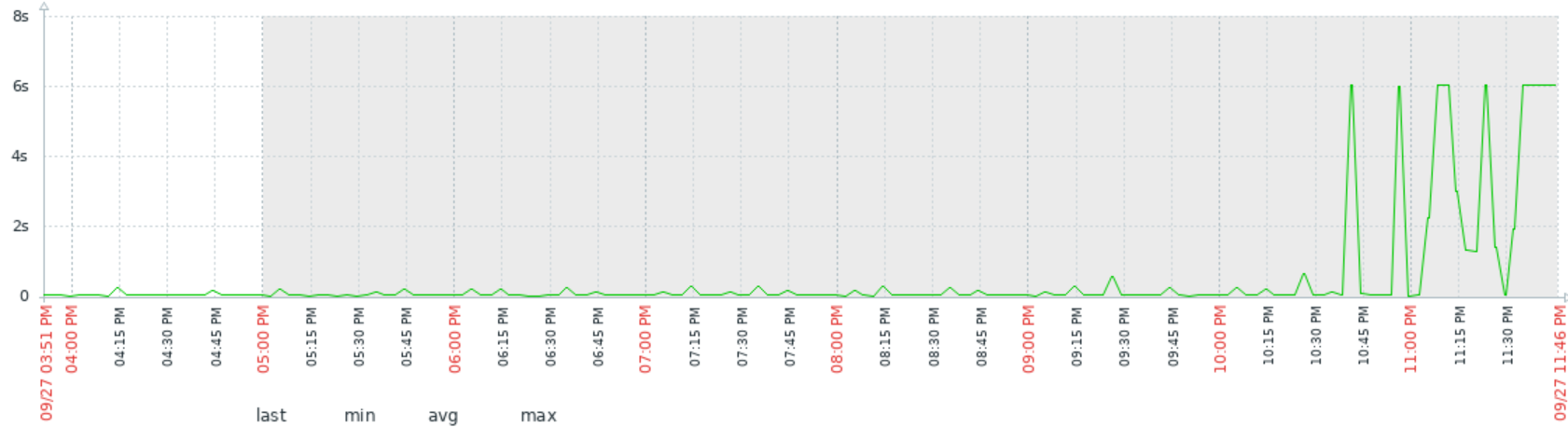
named time to respond to TCP-based queries
The above graph is from a Zabbix monitor showing how long it takes that dns server to respond to that simple query. 6 s is a time-out. I actually set dig to timeout at 2 s, but in wall-clock time it actually takes 6 s.
The fix
We removed this line from the options block of named.conf:
keep-response-order {any; };
The info fmo the experts is that most likely that was configured as a workaround to CVE-2019-6477 but that issue was fixed since 9.15.6.
Conclusion
We encountered the named daemon in a situation where it was unable to respond to TCP-based DNS queries and hence unable to do zone transfers. So although most queries use UDP, this was a serious issue for us and prevented zones from being updated on all authoritative nameservers.
As is the case with so many modern IT problems, the effect was not black or white. Failures were intermittent, and then permanent. A restart fixed ths issue (forgot to mention so far!). But we involved an expert to find the root cause and it was the presence of a single configuration line in our named.conf. After removing that all was good.
I was building some infrastucture around automated speedtest.net tests using speedtest-cli. I noticed the assigned servers keep changing, some servers are categorized as malicious sources, some time out if tested on the hour and half-hour, and results are inconsistent depending on which server you get.
So, I saw that the speedtest-cli (linux command-line python script) has a switch for a “mini” server. When I investigated that seemed the answer to the problem – you can set up your own mini server and use that for yuor tests. I.e., control both ends of the test. great.
The speedtest.net mini server was discontinued in 2017! There’s some commercial replacement. So I thought. Forget that. I was disillusioned and then happened upon a breath of fresh air – an open source alternative to speedtest.net. Enter, librespeed.
Some details
librespeed has a command-line program whih is an obvious rip-off of speedtest-cli. In fact it is called librespeed-cli and has many similar switches.
There is also a server setup. Really, just a few files you can put on any apache + php web server. There is a web GUI as well, but in fact I am not even that interested in that. And you don’t need to set it up at all.
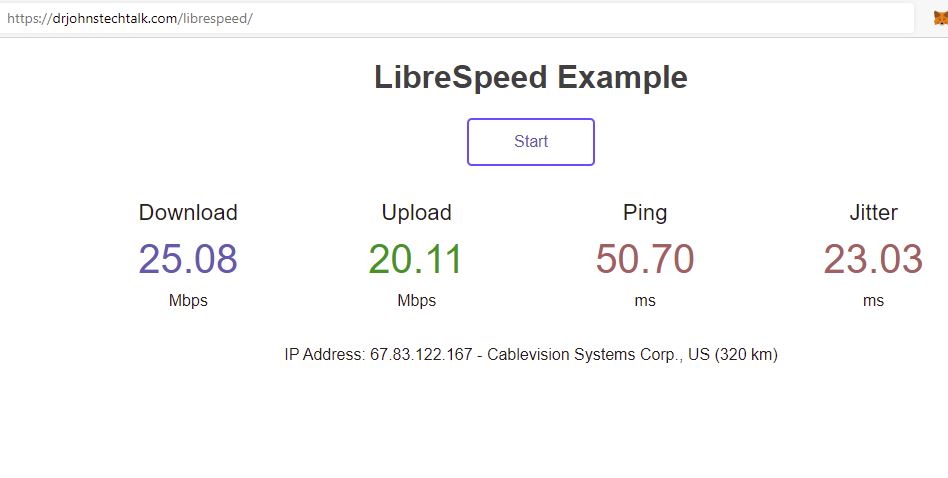
What I like is that with the appropriate switches supplied to librespeed-cli, I can have it run against my own librespeed server. In some testing configurations I was getting 500 Mbps downloads. Under less favorable circumstances, much less.
Testing, testing, testing
I tested between Europe and the US. I tested through a proxy. I tested from the Azure cloud to an Amazon AWS server. I tested with a single cpu linux server (good old drjohnstechtakl.com) either as server, or as the client. This was all possible because I had full control over both ends.
Some tips
Play with the speedtest-cli switches. See what works for you. librespeed-cli -h will shows you all the options.
Increasing the stream count can compensate for slower PING times (assuming both ends have a fast connection)
It does support proxy, but
Downloads don’t really work through proxy if the server is only running http
Counterintuitively, the cpu burden is on the client, not the server! My servers didn’t show the slightest bit of resource usage.
Corollary to 5. My 4-cpu client to 1-cpu server test was much faster than the other way around where server and client roles were reversed.
Most things aren’t sensitive to upload speeds anyway so seriously consider suppressing that test with the appropriate switch. Your tests will also run a lot faster (18 seconds versus 40 seconds).
Worried about consuming too much bandwidth and transferring too much data? I also developed a solution for that (will be my next blog post)
So I am running a librespeed server on my little VM on Amazon AWS but I can’t make it public for fear of getting overrun.
ISPs that have excellent interconnects such as the various cloud providers are probably going to give the best results
It is not true your web server needs write access to its directory in my experience. As long as you don’t care about sharing telemetry data and all that.
To emphasize, they supply the speedtest-cli binary, pre-built, for a whole slew of OSes. You do not and should not compile it yourself. For a standard linux VM you will want the binary called librespeed-cli_1.0.9_linux_386.tar.gz
Example files
The point of these files is to test librespeed-cli, from the directory where you copied it to, against your own librespeed server.
#!/bin/sh
# see ./librespeed-cli -help for all the options
./librespeed-cli --local-json json-ns6 --server 864 --simple --no-upload --no-icmp --ipv4 --concurrent 4 --skip-cert-verify
Purpose: are we getting good speeds?
My purpose in what I am constructing is to verify we are getting good download speeds. I am not trying to hit it out of the park. That consumes (read, wastes) a lot of resources. I am targeting to prove we can achieve about 150 Mbps downloads. I don’t know anyone who can point to 150 Mbps and honestly say that’s insufficient for them. For some setups that may take four simultaneous streams, for others six. But it is definitely achievable. By not going crazy we are saving a lot of data transfers. AWS charges me for my network usage. So a six stream download test at 150 Mbps (Megabits per second) consumes about 325 MBytes download data. If you’re not being careful with your switches, you can easily nudge that up to 1 GB downloads for a single test.
My librespeed client to server tests ran overnight alongside my old approach using speedtest. The speedtest results are all over the place, with a bunch of zeroes for whatever reason, as is typical, while librespeed – and mind you this is from a client in the US, going through a proxy, to a server in Europe – produced much more consistent results. In one case where the normal value was 130 mbps, it dipped down to 110 mbps.
Testing it out at home
Test from a home PC against my own librespeed server
I made my test URL on my AWS server private, but a public one is available at https://librespeed.de/
There were two final issues with speedtest that were the straws that broke the camel’s back, and they are closely related.
When you resolve www.speedtest.net it hits a Content Distribution Network (CDN), and the returned results vary. For instance right now we get:
;; QUESTION SECTION:
;www.speedtest.net. IN A
;; ANSWER SECTION:
www.speedtest.net. 4301 IN CNAME zd.map.fastly.net.
zd.map.fastly.net. 9 IN A 151.101.66.219
zd.map.fastly.net. 9 IN A 151.101.194.219
zd.map.fastly.net. 9 IN A 151.101.2.219
zd.map.fastly.net. 9 IN A 151.101.130.219
Note that you can also run speedtest-cli with the –list switch to get a list of speedtest servers. So in my case I found some servers which procuced good results. There was one where I even know the guy who runs the ISP and know he does an excellent job. His speedtest server is 15 miles away. But, in its infinite wisdom, speedtest sometimes thinks my server is in Lousiana, and other times thinks it’s in New Jersey! So the returned server list is completely different for the two cases. And, even though each server gets assigned a unique number, and you can specify that number with the –server switch, it won’t run the test if that particular server wasn’t proposed to you in its initial listing. (It always makes a server listing call whether you specified –list or not, for its own purposes as to which servers to use.)
I tried to use some of tricks to override this behaviour, but short of re-writing the whole thing, it was not going to work. I imagined I could force speedtest-cli to always use a particular IP address, overwriting the return from the fastly results, but getting that to work through proxy was not feasible. On the other hand if you suck it up and accept their randomly assigned server, you have to put up with a lot of garbage results.
So set up your own server, right? The –mini switch seems built to accommodate that. But the mini server was discontinued in 2017. The commercial replacement seemed to have some limits. So it’s dead end upon dead end with speedtest.net.
Conclusion
An open source alternative to speedtest.net’s speedtest-cli has been identified and tested, both server and client. It is librespeed. It gives you a lot more control than speedtest, if that is your thing and you know a smidgeon of linux.
librespeed server: https://github.com/librespeed/speedtest . You basically can git clone it (just a bunch of js and php files) from: https://github.com/librespeed/speedtest.git
If, in spite of every positive thing I’ve had to say about librespeed, you still want to try the more commercial speedtest-cli, here is that link: https://www.speedtest.net/apps/cli
In this context a lot of people feel iperf is also worth exploring. I think it is a built-in linux command.
A complex environment produces some too-strange-to-be-true type of issues. Yesterday was one of those days. Let me try to set this up like a script from a play.
The setting
A non-descript server room somewhere in the greater New York City area.
The equipment
A generic security appliance we’ll call ThousandEyes PX, just to make up a name.
Cisco Nexus 7K plus a FEX
The players
Dr John – the protagonist
PCT – a generic network vendor
Florence Ranjard – an admin of ThousandEyes PX in France
Shake Abel – a server room resource in PA
Cloud Johnson – someone in Request Management
Bill Otto – a network guy at heart, forced to deal with his now vendor-managed network via ITIL
The processes
ITIL – look it up
Scene 1
An email from Dr John….
Hi Bill,
Thanks.
Well that’s messed up, as they say. I wouldn’t believe it if I hadn’t seen it for myself. Someone, “stole” our port and assigned it to a different device on a different vlan – despite the fact that it was in active use!
I guess I will try to “steal” it back, assuming I can find the IT Catalog article, or maybe with the help of Cloud.
Fortunately I have console access to the Fireeye. I artificially introduced traffic, which I see reflected in the port statistics. So I know the ThousandEyes is still connected to this port, despite the wrong vlan and description.
Regards,
Dr John
Scene 2
One Week earlier
Siting at home due to Covid, Florence realizes she can no longer access the management port of her group’s ThousandEyes security appliance located in another continent. She beings to investigate and even contacts the vendor…
I began to implement the autmoation of speedtest checks. I was running the jobs every 10 minutes, but we noticed something flaky in the results. On the hour and on the half hour the tests seemed to be garbage. What’s going on?
Our findings
Well, if you use a scheduler to run a speedtest every 10 minutes, it will start exactly on the hour and exactly on the half-hour, amongst other start times. We were running it eight times to test eight different paths. Only the last two were returning reliable results. The early ones were throwing errors. So I introduced an offset to run the jobs at 2,12,22,32,42,52 minutes. And with this offset, the results became much more reliable.
The inevitable conclusion is that too many other people are running tests exactly on the hour and half hour. A single run takes roughly 30 seconds to complete. And it must be that the servers which speedtest rely on are simply overwhelmed and refuse to do more tests.
I don’t think we ask a lot of our switches. A packet comes in on this port and goes out on this other port. That sort of thing. But, apparently, when the switch is a Cisco Nexus, that is asking too much. Maybe it will go to that other port. Let’s see, it depends who sent it. So then again, maybe not. So maybe device A can ping device B. Device B cannot ping device A. But it can ping device C and device C can ping A. Or maybe Jack can ping device 1 but not device 2 on the same subnet. Yet Jill can ping device 2 but not device 1!
Yes. Those are not theoretical examples, but, sadly, actual examples lifted from recent massive debugging sessions I’ve participated in, which, eventually, focused on the Nexus switch not treating all traffic as it should. Another example: larger packets were not getting through on the same vlan.
Sometimes the Cisco support engineer is too clever by half. We had one find a few errors on supervisor board 5 so we switched to board 6. That did nothing. We finally noticed that all problems were related to FEXes connected to slot 8. As a test we plugged a FEX into a different slot and, voila, things began to work better. But the Cisco guy did not see any errors on slot 8.
Well, you only get the same Cisco engineer for a limited time. Then their shift turns over and you get to explain the whole problem all over again to the next one. Yeah, supposedly they’re briefed, but ni reality not so much. So finally the second engineer was a little more pragmatic than the first too-clever guy. This is a quote from her: “I do not see errors on that module, but logically, it has to be the problem.” This of course is after we presented all the evidence to her. So we ordered an RMA, replaced that board and yes everything began to work.
I’ve been involved in two such massive debugging session over the last four months. No one from the Cisco side is saying it, but I will. These Nexus switches define flows behind the scenes. They can probably do some very clever things with these flows. But it is no longer a simple switch. And, sadly, when the flows don’t all work, no one at Cisco is prepared to look for that issue or even consider it as a possibility. They look for obscure errors. And, heaven forbid, they are, I guess, incapable of proving to themselves their switch as at fault – eating packets – by doing what any first semester network class would have, namely, mirroring some of the ports and examining the traffic for themselves. It is instead up to the customer to prove the switch is at fault.
So in my first debugging session, which lasted about 16 hours, Cisco did not really find the errors that would lead them to believe slot 8 was a problem. Yet its replacement fixed everything. In fairness, in the second debugging session, which only lasted five hours or so, they did see errors which justified a replacement. But at no time did they ever use the word flow or offer in detail how the errors they saw could have produced the weird results we were seeing (that was the Jack and Jill example from above).
Conclusion
We guys who run servers would like to think a switch is a switch is a switch. But Cisco is requiring us to up our game, even if they don’t up theirs. Their Nexus switches absolutely can eat some of your network traffic while passing other over the same ports. I’d like to call that flows, even if they refuse to use that term.
Answer: the one where their switch eats the DHCPDISCOVER packets. And the amazing thing is they never learn. And the second amazing thing is that they actually don’t apply the most basic networking debugging techniques when such a problem occurs. I’m talking your basic, DHCPDISCOVER packet goes to your switch, same DHCPDISCOVER packet never arrives to the DHCP server on same switch. We know it to be the case, but, to help convince yourself that your switch is eating the packets, do networky things like create a span port of the DHCP server’s port to prove to yourself that no DHCP requests are coming in. And yet, they are never prepared to do that, to propose that. So instead indirect proxies are used to draw the conclusion.
I’ve been involved in three of four such debugging sessions. They take hours. I took notes when it happened again this weekend. I guess that setup is pretty typical of how it plays out. A data center was moved, including a DHCP server. The new data center has a MAN network to the old one. All IPs were preserved. When they turned on the moved DHCP server DHCP lease were no longer getting handed out. In fact it was worse than that. With the moved DHCP sever turned off, most DHCP leases were working. But with it on, that’s when things really began to go south!
Here’s the switch port they noted for the iDRAC:
sh run int gi1/0/24
Building configuration…
Current configuration : 233 bytes
!
interface GigabitEthernet1/0/24
description --- To-cnshis01-iDRAC - iDRAC
switchport access vlan 202
switchport mode access
logging event link-status
speed 100
duplex full
spanning-tree portfast
ip dhcp snooping trust
end
The first line of course if the IOS command. OK, so they had that on the iDRAC, right. But on the actual server port they had this:
sh run int gi1/0/23
Building configuration…
Current configuration : 258 bytes
!
interface GigabitEthernet1/0/23
description --- To-cnshis01-Gb1 - Gb1
switchport access vlan 202
switchport mode access
logging event link-status
spanning-tree portfast
service-policy input PMAP_COS_REMARK_IN
service-policy output PMAP_COS_OUT
end
I basically told them cheekily up front that this is usually a network switch problem and that they have to play with the DHCP snooping enable setting.
And I have to say that the usual hours of debugging were short-circuited this time as they seemed to believe me, and simply experimented by adding
ip dhcp snooping trust
to the DHCP server’s main port. We immediately began seeing DHCPDISCOVER pakcets come in to the DHCP server, and the team testified that people were getting leases.
Final mystery explained
Now why were things behaving really badly – no leases – when the DHCP server was up but no DHCPDISCOVER requests were getting to it? I have the explanation for that as well. You see there is a standby DHCP server which is designed for failure of the primary DHCP server. But not for this type of failure! That’s right. There is an out-of-band (by that I mean not carried over DHCP ports like UDP port 67) communication between standby and primary which tells the standby Hey, although you got this DHCPDISCOVER request, ignore it becasue the primary is active and will serve it! And meanwhile, as we have said, the primary wasn’t getting the requests at all. Upshot: no one gets leases.
Just to mention it
My second-to-last debugging session of this sort was a little different. There they mentioned that there was a “global setting” which governed this DHCP snooping on the switch. So they had to do something with that (enable or disable or something). So there was no issue with the individual switch ports. For me that’s just a variation on the same theme.
2023 debugging session
Well, nothing has really changed two years after I originslly posted this article and I get on these troubleshooting sessions with the vendor, people from the firewall team, vendor management people – it’s quite an affair. And as before it always takes a minimum of a couple hours for the network vendor to find their mistakes in their configuration. I have just done two of these sessions in the last week.
The last one was a tad different. There was a firewalled segment. The PCs behind it were not receiving IPs from the dhcp server. It is worth mentioning. Someone suggested a traceroute from the dhcp server to this subnet. And then a traceroute to another subnet (non-firewalled) at the same site which was working. They looked completely different after the first few hops! So about an hour after that they found that they had forgotten to add a route for this subnet pointing to the firewall. And that makes sense in that on the dhcp server – unlike in most cases – I was see the DHCP DISCOVER and it was replying with a DHCP OFFER. But that DHCP OFFER was simply not getting to the firewall at the site.
Cute Mnemonic to remember the four DHCP phases
Can you never remember the phases of the DHCP protocol like me? Then remember only this: DORA.
Discover
Offer
Request
Ack
What’s the idea behind this feature?
Having done a total of zero minutes of research on the topic, I will anyway weigh in with my opinion! Suppose someone comes along and plugs in a consumer grade home router into your network. It’s probably going to act as a rogue DHCP server. Imagine the fun trying to debug that situation? We’ve all been there… These rogue devices are probably fairly common. So if your corporate switch doesn’t suppress certain DHCP packets from ports where they are not expected, then this rogue device will begin to take down your subnet and totally bewilder everyone. I imagine this setting that is the topic of this blog post stems from trying to suppress all unknown DHCP packets in advance. Its just that sometimes the setting is taken too far and, e.g., a firewall which relays DHCP requests is also getting its DHCP packets suppressed.
Conclusion
I normally would have presented this as part of my IT Detective series. But I feel this is more like a lament about the sad state of affairs with our network providers. And though I’ve seen this issue about four times in the past 12 months, they always act like they have no idea what we’re talking about. They’ve never encountered this problem. They have no idea how to fix it. And they have no idea how to further debug it.. What steps does the customer wish?
We woke up yesterday to no Internet. The usual remedies consumers go through did nothing to resolve the issue. What to do?
The details – November 25, 2020
The usual restarts or my router and the cable modem did not work. I plugged in my work laptop directly to the cable modem for some quick tests but that did not work.
I plugged my work-issued VPN router directly to the cable modem and it did not pick up an IP and re-establish the tunnel.
When I logged into my router I saw that its WAN IP was listed as 0.0.0.0, which means none at all.
I called the ISP twice. Both time they said they could “see” my modem, and they tried to restart it on their end, but that did not seem to do anything at all, based on the constant status LEDs (see picture below). I got my service visit moved up from Dec 11th to Dec 2nd, but still that would mean a week without Internet – not so great when three people are relying on it for their work.
I rebooted the cable modem a couple times at least. Nothing changed.
Then I started some research on quickie alternatives. Ask a friend from work for a spare Cradlepoint air card? They’re already out on vacation. Get a Chinese-made unlocked hotspot with pre-purchased data? Seems fishy, and ultimately expensive. Verizon brand hotspot? We had a borrowed one. Very finicky. And no ethernet ports.
Raspberry Pi + DIY approach?
At one point in the evening, convinced I would have to wait days for for a visit from the cable guy, I rigged up a spare Raspberry Pi to act as a router between a mobile hotspot (a companion tablet to a Verizon phone) and my Linksys router. Why bother? Why not just use the hotspot directly? Mostly because it’s a pain in the rear to reprogram all those Internet of Things devices one has in ones home these days, notably the several Echo Dots, but as well, a wireless printer, a few laptops, Firesticks, tablets, etc. With this approach I keep the WiFi SSID as it was for all those devices. And, it sort of worked! At least I got one Echo Dot to work. I didn’t push my luck. This stuff consumes a lot of data, even when “idle.”
To be continued…
Linksys WRT1200AC status lights – when healthy!Cable Modem tatus lights – when operating normally
But I am pretty good at troubleshooting. What I know that less experienced people may not is that all the testing I’ve done to that point was not ironclad proof of failure of the cable modem. I know the traditional advice of old is to hook up a laptop directly to the ethernet port and work with it that way. Furthermore the cable company support said that my status lights were reading normally. So, when I tested my work laptop? Are you kidding? That thing has so many problems when I switch between SSIDs due to some new security software – it loves to display the Globe in the system tray, and the only recourse is to reboot. That’s what I was seeing, but notice I said a quickie test? I did not have time to do that reboot and all that. And that work-issued VPN router? I don’t know how that thing really works either. Never having set it up that way I did not trust reading too much into its results (which was essentially an orange status light instead of the usual white).
So when I had more time in the evening, I hooked up a home laptop which I know should work. After a cable modem reboot in fact I did get an IP and could surf the Internet. That was a glimmer of hope. So I put my router back in place. Still it did not pick up an WAN IP address. Still reading 0.0.0.0 for its IP.
Then I put the laptop back, writing down the IP, subnet mask and default gateway. Then I put my router back, switched its WAN mode from DHCP to fixed IP, putting on the exact IP address the laptop had picked up, with correct subnet mask and default gateway. Still it was not working. When the router is not working the WAN status light is sort of orange-ish. It’s white (pictured above) when the WAN link is communicating.
I decided the fault should lie more with my router than anywhere else, and since it wasn’t working and no number of power cycles was changing that situation, I decided that a factory reset is the thing to try. The last thing I could try. I noted the exact name and passwords of my SSIDs, held the reset button for 15 seconds until the status lights flicked out, and let it start up. It went through a start-up process, which i saw after connecting to its default IP of 192.168.1.1. It was clear it was not seeing the cable modem at the point where it should, but it had some very specific advice to try: power off cable modem, wait two minutes, power it back on, and then it would try again. And that did work! Yeah!
What may have precipitated this
My local cable company was recently bought by a much bigger company. I know for a fact what my WAN IP used to be, and I see it has changed. They now draw from a giant pool of IPs – a /14 in CIDR notation – that’s 262,000 addresses – that belongs to the new owner. So I believe the problem occurred due to a poor implementation of the dhcp protocol within my router, or a poor interplay between my router’s DHCP client and the ISP’s DHCP server. But I can’t research that line of troubleshooting because the ISP’s DHCP policies would require a lot of time-consuming experimentation on my part to reverse engineer based on observed behaviour under different conditions. And I would need an open source DHCP client – but I have the Raspberry Pi running dnsmasq for that, so that end could gather all the needed client information.
Prior to this acquisition I would tend to keep the same WAN IP for years – that’s how stable it was.
Another approach
Very germane to this topic is the fact that my neighbor down the street experienced his own Internet outage the day after I did! His solution was to buy a better cable modem. I did not know you could do that – I thought they were proprietary. He also saw his router with the 0.0.0.0 WAN address. And his approach also worked. This makes me less sure my router was really at fault – maybe Altice screwed up their DHCP service for half a day.
Conclusion
Unusual for me, I’m going to write the conclusion before writing the tedious part which is the full explanation in the middle.
By the end of the day I got the Internet working. After isolating the problem to my home router, the Linksys WRT1200AC, and determining that any amount of power cycling was not clearing things up, a factory reset did the trick! The cable modem and my cable Internet service was fine all along.
Intro
You have to dig a little to find out about this somewhat obscure topic. You want to send syslog output, e.g., from the named daemon, to a syslog server with beefed up security, such that it requires the use of TLS so traffic is encrypted. This is how I did that.
The details
This is what worked for me:
...
# DrJ fixes - log local0 to DrJ's dmz syslog server - DrJ 5/6/20
# use local0 for named's query log, but also log locally
# see https://www.linuxquestions.org/questions/linux-server-73/bind-queries-log-to-remote-syslog-server-4175
669371/
# @@ means use TCP
$DefaultNetstreamDriver gtls
$DefaultNetstreamDriverCAFile /etc/ssl/certs/GlobalSign_Root_CA_-_R3.pem
$ActionSendStreamDriver gtls
$ActionSendStreamDriverMode 1
$ActionSendStreamDriverAuthMode anon
local0.* @@(o)14.17.85.10:6514
#local0.* /var/lib/named/query.log
local1.* -/var/log/localmessages
#local0.*;local1.* -/var/log/localmessages
local2.*;local3.* -/var/log/localmessages
local4.*;local5.* -/var/log/localmessages
local6.*;local7.* -/var/log/localmessages
...
# DrJ fixes - log local0 to DrJ's dmz syslog server - DrJ 5/6/20
# use local0 for named's query log, but also log locally
# see https://www.linuxquestions.org/questions/linux-server-73/bind-queries-log-to-remote-syslog-server-4175
669371/
# @@ means use TCP
$DefaultNetstreamDriver gtls
$DefaultNetstreamDriverCAFile /etc/ssl/certs/GlobalSign_Root_CA_-_R3.pem
$ActionSendStreamDriver gtls
$ActionSendStreamDriverMode 1
$ActionSendStreamDriverAuthMode anon
local0.* @@(o)14.17.85.10:6514
#local0.* /var/lib/named/query.log
local1.* -/var/log/localmessages
#local0.*;local1.* -/var/log/localmessages
local2.*;local3.* -/var/log/localmessages
local4.*;local5.* -/var/log/localmessages
local6.*;local7.* -/var/log/localmessages
The above is the important part of my /etc/rsyslog.conf file. The SIEM server is running at IP address 14.17.85.10 on TCP port 6514. It is using a certificate issued by Globalsign. An openssl call confirms this (see references).
Other gothcas
I am running on a SLES 15 server. Although it had rsyslog installed, it did not support tls initially. I was getting a dlopen error. So I figured out I needed to install this module: