Unlike your home PC, critical security servers basically never just restart on their own. But today I got a Zabbix notification that indeed one of ours had done just that. I set out to investigate to learn the root cause and prevent it from recurring. things took a weird turn at some point.
The details
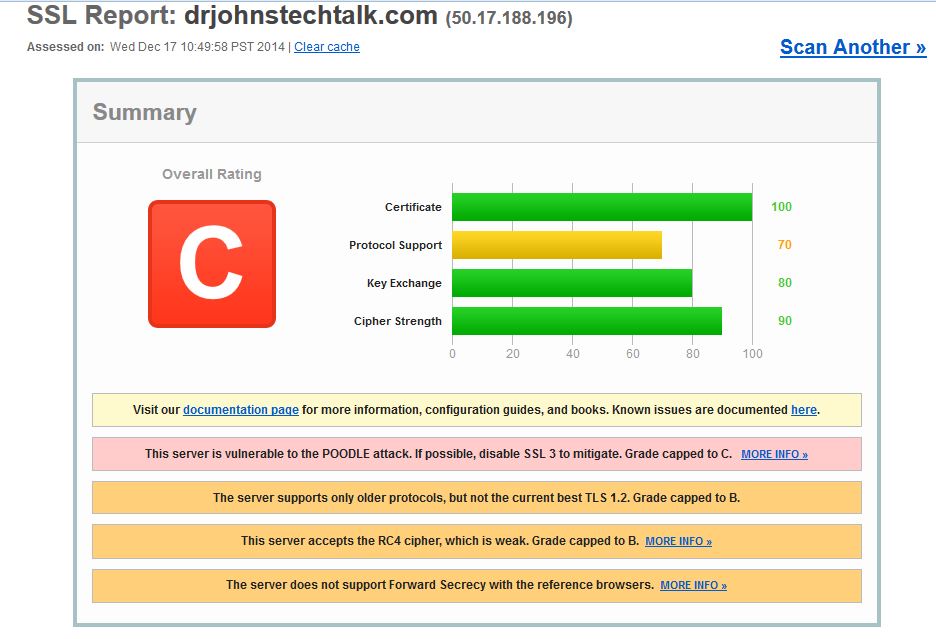
I asked my colleague to investigate the server, He dutifully looked at various logs. There didn’t seem to be anything amiss according to the logs. Then he showed me a screenshot of the CLI prompt. It had been up for 497 days and some hours. So there was no restart.
We speculated that maybe just the ASM module had restarted, but without any real evidence.
System uptime is an SNMP MIB which we monitor in Zabbix.
The graph of this uptime looks like this:
What is the Zabbix trigger expression for this problem? it is:
In words, if the uptime, a linearly increasing value over time, becomes suddenly smaller, then the change from the previous value is negative and it is assumed that signifies a restart.
Then I remembered another way to satisfy that condition. Consider this python math:
>>> 86400*497
42940800
>>> 2**32
4294967296
The first few digits of those two different calculations agree, right? Let me back up. A day has 3600*24 = 86400 seconds. What I’m getting at is that if you assume the uptime units in this MIB are hundredths of a second, then the two numbers become basically the same.
So what happened is that this counter filled up after 497 days and rolled over! So there was no restart after all.
Conclusion
A Zabbix-reported F5 restart on an F5 BIG-IP which had been up for more than 497 days was shown to be a false positive and explained as an artifact of the finite size of the SNMP counter, which rolled over to 0.
Intro
I share some Zabbix items I’ve had to create which I find useful.
Low-level discovery to discover IPSEC tunnels on an F5 BigIP
IPSec tunnels are weird insofar as there is one IKE SA but potentially lots of SAs – two for each traffic selector. So if your traffic selector is called proxy-01, some OIDs you’ll see in your SNMP walk will be like …proxy-01.58769, …proxy-01.58770. So to review, do an snmpwalk on the F5 itself. That command is something like
snmpwalk -v3 -l authPriv -u proxyUser -a SHA -A shaAUTHpwd -x AES -X AESpwd -c public 127.0.0.1 SNMPv2-SMI::enterprises >/tmp/snmpwalk-ent
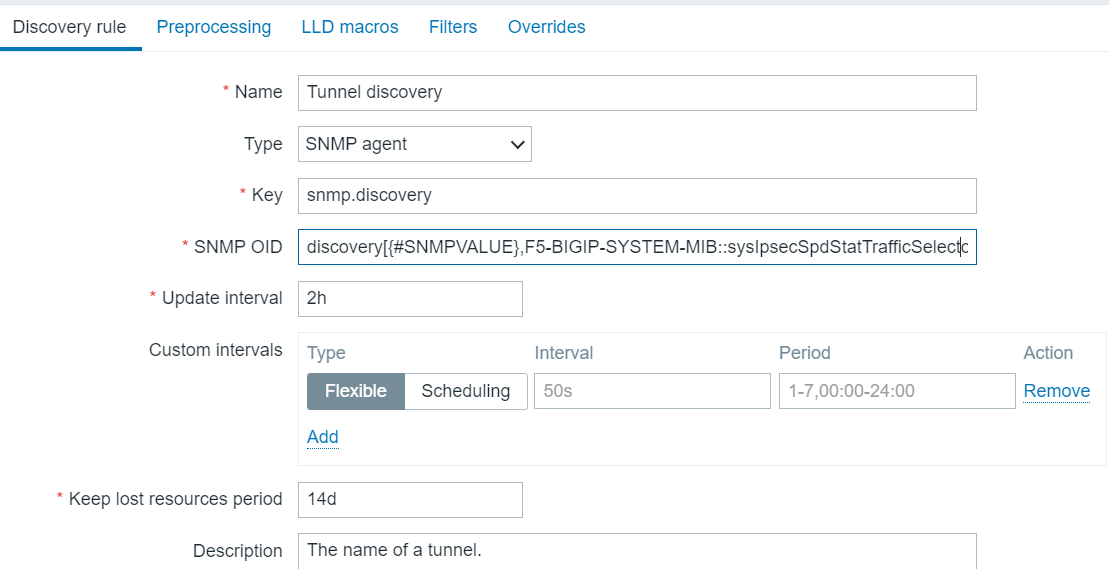
Now…how to translate this LLD? In my case I have a template since there are several F5s which need this. The template already has discovery rules for Pool discovery, Virtual server discovery, etc. So first thing we do is add a Tunnel discovery rule.
Tunnel Discovery Rule
The SNMP OID is clipped at the end. In full it is:
Initially I tried something else, but that did not go so well.
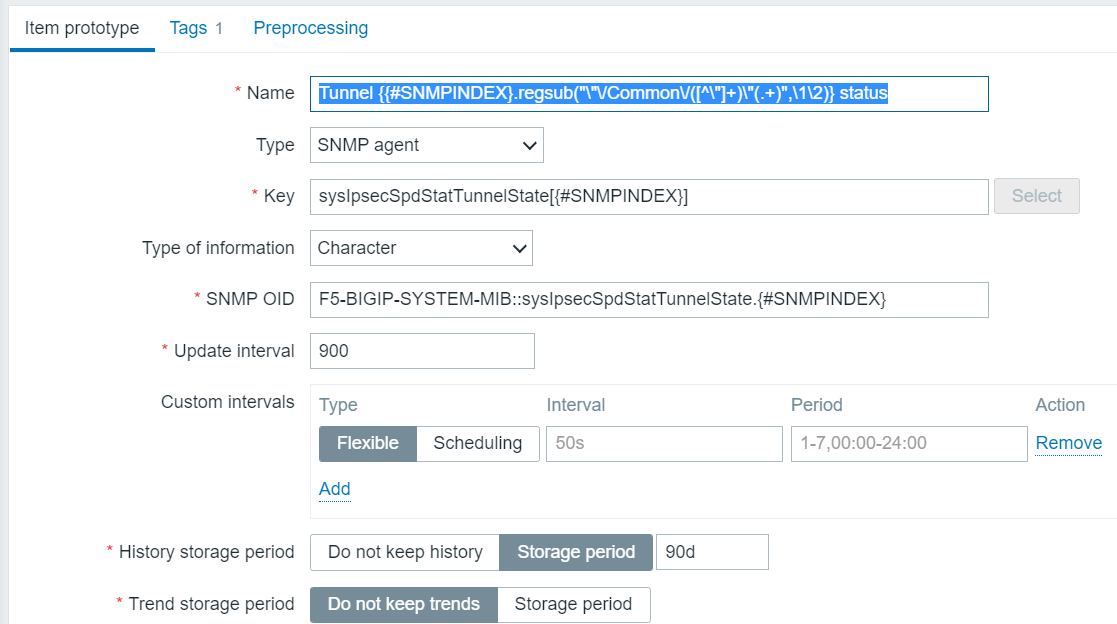
Now we want to know the tunnel status (up or down) and the amount of traffic over the tunnel. We create two item prototypes to get those.
Tunnel Status Item prototype
So, yes, we’re doing some fancy regex to simplify the otherwise ungainly name which would be generated, stripping out the useless stuff with a regsub function, which, by the way, is poorly documented. So that’s how we’re going to discover the statuses of the tunnels. In text, the name is:
Tunnel {{#SNMPINDEX}.regsub(“\”\/Common\/([^\”]+)\”(.+)”,\1\2)} status
I learned how to choose the OID, which is the most critical part, I guess, from a combination of parsing the output of the snmpwalk plus imitation of those other LLD item prortypes, which were writtne by someone more competent than I.
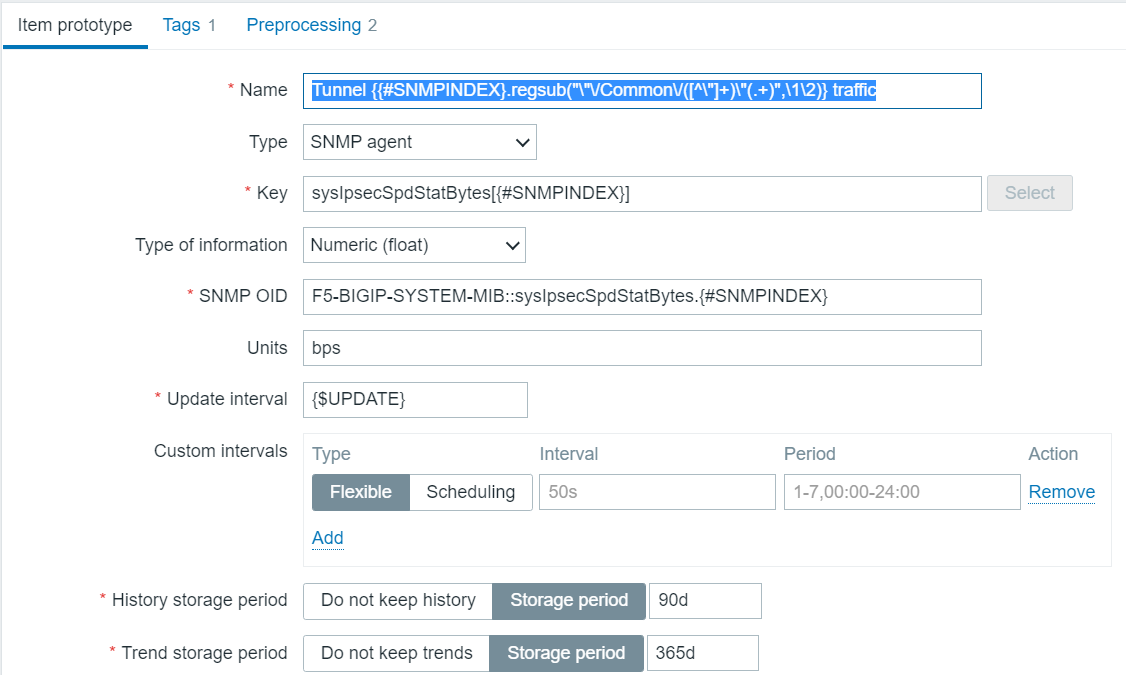
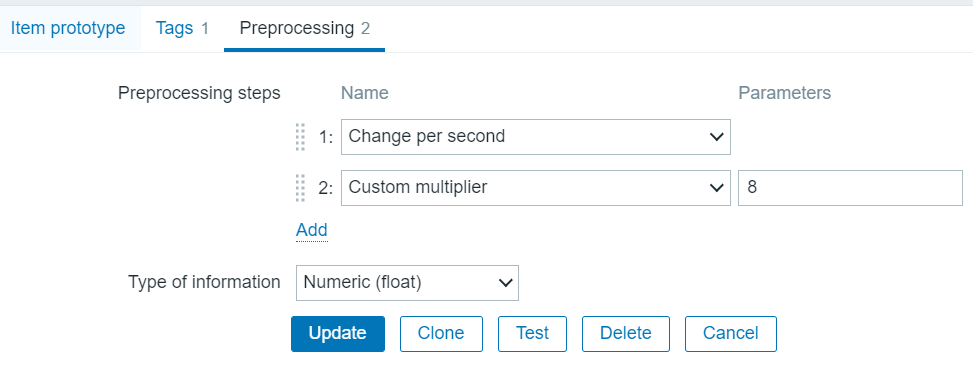
Now the SNMP value for traffic is bytes, but you see I set units of bps? I can do that because of the preprocessing steps which are
Bytes to traffic rate preprocessing steps
Final tip
For these discovery items what you want to do is to disable Create Enabled and disable Discover. I just run it on the F5s which actually have IPSEC tunnels. Execute now actually works and generates items pretty quickly.
Using the api with a token and security by obscurity
I am taking the approach of pulling the token out of a config file where it has been stored, base85 encoded, because, who uses base85, anyway? I call the following script encode.py:
import sys
from base64 import b85encode
s = sys.argv[1]
s_e = s.encode('utf-8')
s64 = b85encode(s_e)
print('s,s_e,s64',s,s_e,s64)
In my case I pull this encoded token from a config file, but to simplify, let’s say we got it from the command line. This is how that goes, and we use it to create the zapi object which can be used in any subsequent api calls. That is the key.
So it’s a few extra lines of code, but the cool thing is that it works. This should be good for version 5.4 and 6.0. Note that if you installed both py-zabbix and pyzabbix, your best bet may be to uninstall both and reinstall just pyzabbix. At least that was my experience going from user/pass to token-based authentication.
Convert DateAndTime SNMP output to human-readable format
Of course this is not very Zabbix-specific, as long as you realize that Zabbix produces the outer skin of the function:
function(value){
function (value) {
// DrJ 2020-05-04// see https://support.zabbix.com/browse/ZBXNEXT-3899 for SNMP DateAndTime format'use strict';//var str = "07 E4 05 04 0C 32 0F 00 2B 00 00";var str = value;// alert("str: " + str);// read values are hexvar y256 = str.slice(0,2);var y = str.slice(3,5);var m = str.slice(6,8);var d = str.slice(9,11);var h = str.slice(12,14);var min = str.slice(15,17);// convert to decimalvar y256Base10 =+("0x"+ y256);// convert to decimalvar yBase10 =+("0x"+ y);var Year =256*y256Base10 + yBase10;// alert("Year: " + Year);var mBase10 =+("0x"+ m);var dBase10 =+("0x"+ d);var hBase10 =+("0x"+ h);var minBase10 =+("0x"+ min);var YR =String(Year);var MM =String(mBase10);var DD =String(dBase10);var HH =String(hBase10);var MIN =String(minBase10);// paddingif(mBase10 <10) MM ="0"+ MM;if(dBase10 <10) DD ="0"+ DD;if(hBase10 <10) HH ="0"+ HH;if(minBase10 <10) MIN ="0"+ MIN;varDate= YR +"-"+ MM +"-"+ DD +" "+ HH +":"+ MIN;returnDate;
// DrJ 2020-05-04
// see https://support.zabbix.com/browse/ZBXNEXT-3899 for SNMP DateAndTime format
'use strict';
//var str = "07 E4 05 04 0C 32 0F 00 2B 00 00";
var str = value;
// alert("str: " + str);
// read values are hex
var y256 = str.slice(0,2); var y = str.slice(3,5); var m = str.slice(6,8);
var d = str.slice(9,11); var h = str.slice(12,14); var min = str.slice(15,17);
// convert to decimal
var y256Base10 = +("0x" + y256);
// convert to decimal
var yBase10 = +("0x" + y);
var Year = 256*y256Base10 + yBase10;
// alert("Year: " + Year);
var mBase10 = +("0x" + m);
var dBase10 = +("0x" + d);
var hBase10 = +("0x" + h);
var minBase10 = +("0x" + min);
var YR = String(Year); var MM = String(mBase10); var DD = String(dBase10);
var HH = String(hBase10);
var MIN = String(minBase10);
// padding
if (mBase10 < 10) MM = "0" + MM; if (dBase10 < 10) DD = "0" + DD;
if (hBase10 < 10) HH = "0" + HH; if (minBase10 < 10) MIN = "0" + MIN;
var Date = YR + "-" + MM + "-" + DD + " " + HH + ":" + MIN;
return Date;
I put that javascript into the preprocessing step of a dependent item, of course.
All my real-life examples do not fill in the last two fields: +/-, UTC offset. So in my case the times must be local times. But consequently I have no idea how a + or – would be represented in HEX! So I just ignored those last fields in the SNNMP DateAndTime which otherwise might have been useful.
Here’s an alternative version which calculates how long its been in hours since the last AV signature update.
// DrJ 2020-05-05// see https://support.zabbix.com/browse/ZBXNEXT-3899 for SNMP DateAndTime format'use strict';//var str = "07 E4 05 04 0C 32 0F 00 2B 00 00";var Start =newDate();var str = value;// alert("str: " + str);// read values are hexvar y256 = str.slice(0,2);var y = str.slice(3,5);var m = str.slice(6,8);var d = str.slice(9,11);var h = str.slice(12,14);var min = str.slice(15,17);// convert to decimalvar y256Base10 =+("0x"+ y256);// convert to decimalvar yBase10 =+("0x"+ y);var Year =256*y256Base10 + yBase10;// alert("Year: " + Year);var mBase10 =+("0x"+ m);var dBase10 =+("0x"+ d);var hBase10 =+("0x"+ h);var minBase10 =+("0x"+ min);var YR =String(Year);var MM =String(mBase10);var DD =String(dBase10);var HH =String(hBase10);var MIN =String(minBase10);var Sigdate =newDate(Year, mBase10 -1, dBase10,hBase10,minBase10);//difference in hoursvar difference =Math.trunc((Start - Sigdate)/1000/3600);return difference;
// DrJ 2020-05-05
// see https://support.zabbix.com/browse/ZBXNEXT-3899 for SNMP DateAndTime format
'use strict';
//var str = "07 E4 05 04 0C 32 0F 00 2B 00 00";
var Start = new Date();
var str = value;
// alert("str: " + str);
// read values are hex
var y256 = str.slice(0,2); var y = str.slice(3,5); var m = str.slice(6,8); var d = str.slice(9,11); var h = str.slice(12,14); var min = str.slice(15,17);
// convert to decimal
var y256Base10 = +("0x" + y256);
// convert to decimal
var yBase10 = +("0x" + y);
var Year = 256*y256Base10 + yBase10;
// alert("Year: " + Year);
var mBase10 = +("0x" + m);
var dBase10 = +("0x" + d);
var hBase10 = +("0x" + h);
var minBase10 = +("0x" + min);
var YR = String(Year); var MM = String(mBase10); var DD = String(dBase10);
var HH = String(hBase10);
var MIN = String(minBase10);
var Sigdate = new Date(Year, mBase10 - 1, dBase10,hBase10,minBase10);
//difference in hours
var difference = Math.trunc((Start - Sigdate)/1000/3600);
return difference;
function customSlice(array, start, end) {
var result = [];
var length = array.length;
// Handle negative start
start = start < 0 ? Math.max(length + start, 0) : start;
// Handle negative end
end = end === undefined ? length : (end < 0 ? length + end : end);
// Iterate over the array and push elements to result
for (var i = start; i < end && i < length; i++) {
result.push(array[i]);
}
return result;
}
function compareRangeWithExtractedIPs(ranges, result) {
// ranges is ["120.52.22.96/27","205.251.249.0/24"]
// I need to know if ips are in some of the ranges
var ipRegex = /\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b/g;
var ips = result.match(ipRegex) || [];
return ips.every(function(ip) {
return ranges.some(function(range) {
var rangeParts = range.split('/');
var rangeIp = rangeParts[0];
var rangeCidr = rangeParts[1];
var rangeIpParts = rangeIp.split('.').map(Number);
var ipParts = ip.split('.').map(Number);
var rangeBinary = rangeIpParts.map(toBinary).join('');
var ipBinary = ipParts.map(toBinary).join('');
return ipBinary.substring(0, rangeCidr) === rangeBinary.substring(0, rangeCidr);
});
});
}
function toBinary(num) {
var binary = num.toString(2);
return '00000000'.substring(binary.length) + binary;
}
function fetchData(url) {
try {
Zabbix.log(4, 'Starting GET request to the provided URL');
var result = {},
req = new HttpRequest(),
resp;
req.addHeader('Content-Type: application/json');
resp = req.get(url);
if (req.getStatus() != 200) {
throw 'Response code: ' + req.getStatus();
}
resp = JSON.parse(resp);
result.data = resp;
var ipPrefixes = resp.prefixes.map(function(prefix) {
return prefix.ip_prefix;
});
result.data = ipPrefixes;
} catch (error) {
Zabbix.log(4, 'GET request failed: ' + error);
result = {};
}
return JSON.stringify(result.data);
}
var result = fetchData('https://ip-ranges.amazonaws.com/ip-ranges.json');
var ranges = JSON.parse(result);
return compareRangeWithExtractedIPs(ranges, value);
This is the preprocessing step of a dependent item which ran a net.dns.record to do DNS outlook and get results as you see them from dig. I don’t fully understand how it works! My colleague wrote it and he used copilot mostly! He started making progress with Copilot once he constrained it to use “duct tape Javascript.” Apparently that’s a thing. This is defined within a template. It compares all of the returned IPs to a json list of expected possible ranges, which are pulled directly from an AWS endpoint. There are currently 7931 ranges, who knew?
Since this returns a true of false there are two subsequent preprocessing steps which Repalce true with 0 and false with 1 and we set the type to Numeric unsigned.
Calculated bandwidth from an interface that only provides byte count
Again in this example the assumption is you have an item, probably from SNMP, that lists the total inbound/outbound byte count of a network interface – hopefully stored as a 64-bit number to avoid frequent rollovers. But the quantity that really excites you is bandwidth, such as megabits per second.
Use a calculated item as in this example for Bluecoat ProxySG:
change(sgProxyInBytesCount)*8/1000000/300
change(sgProxyInBytesCount)*8/1000000/300
Give it type numeric, Units of mbps. sgProxyInBytesCount is the key for an SNMP monitor that uses OID
IF-MIB::ifHCInOctets.{$INTERFACE_TO_MEASURE}
IF-MIB::ifHCInOctets.{$INTERFACE_TO_MEASURE}
where {$INTERFACE_TO_MEASURE} is a macro set for each proxy with the SNMP-reported interface number that we want to pull the statistics for.
The 300 in the denominator of the calculated item is required for me because my item is run every five minutes.
Alternative
No one really cares about the actual total value of byte count, right? So just re-purpose the In Bytes Count item a bit as follows:
add preprocessing step: Change per second
add second preprocessing step, Custom multiplier 8e-6
The first step gives you units of bytes/second which is less interesting than mbps, which is given by the second step. So the final units are mbps.
Be sure to put the units as !mbps into the Zabbix item, or else you may wind up with funny things like Kmbps in your graphs!
Creating a baseline
Even as of Zabbix v 5, there is no built-in baseline item type, which kind of sucks. Baseline can mean many different things to many people – it really depends on the data. In the corporate world, where I’m looking at bandwidth, my data has these distinct characteristics:
varies by hour-of-day, e.g., mornings see heavier usage than afternoons
there is the “Friday effect” where somewhat less usage is seen on Fridays, and extremely less usage occurs on weekends, hence variability by day-of-week
probably varies by day of month, e.g., month-end closings
So for this type of data (except the last criterion) I have created an appropriate baseline. Note I would do something different if I were graphing something like the solar generation from my solar panels, where the day-of-week variability does not exist.
Getting to the point, I have created a rolling lookback item. This needs to be created as a Zabbix Item of type Calculated. The formula is as follows:
In this example sgProxyInBytesCount is my key from the reference item. Breaking it down, it does a rolling lookback of the last six measurements taken at this time of day on this day of the week over the last six weeks and averages them. Voila, baseline! The more weeks you include the more likely you are to include data you’d rather not like holidays, days when things were busted, etc. I’d like to have a baseline that is from a fixed time, like “all of last year.” I have no idea how. I actually don’t think it’s possible.
But, anyway, the baseline approach above should generally work for any numeric item.
Refinement
The above approach only gives you six measurements, hence 1/sqrt(6) ~ 40% standard deviation by the law of large numbers, which is still pretty jittery as it turns out. So I came up with this refined approach which includes 72 measurements, hence 1/sqrt(72) ~ 12% st dev. I find that to be closer to what you intuitively expect in a baseline – a smooth approximation of the past. Here is the refined function:
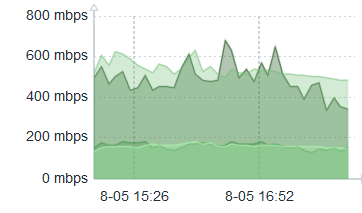
I would have preferred a one-hour interval centered around one week ago, etc., e.g., something like 1w+30m, but such date arithmetic does not seem possible in Zabbix functions. And, yeah, I could put 84600s (i.e., 86400 – 1800), but that is much less meaingful and so harder to maintain. Here is a three-hour graph whose first half still reflects the original (jittery) baseline, and last half the refined function.
Latter part has smoothed baseline in light green
What I do not have mastered is whether we can easily use a proper smoothing function. It does not seem to be a built-in offering of Zabbix. Perhaps it could be faked by a combination of pre-processing and Javascript? I simply don’t know, and it’s more than I wish to tackle for the moment.
Data gap between mulitple item measurements looks terrible in Dashboard graph – solution
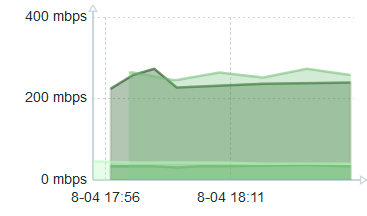
In a Dashboard if you are graphing items which were not all measured at the same time, the results can be frustrating. For instance, an item and its baseline as calculated above. The central part of the graph will look fine, but at either end giant sections will be missing when the timescale of display is 30 minutes or 60 minutes for items measured every five minutes or so. Here’s an example before I got it totally fixed.
Zabbix item timing mismatch
See the left side – how it’s broken up? I had beguin my fix so the right side is OK.
The data gap solution
Use Scheduling Intervals in defining the items. Say you want a measurement every five minutes. Then make your scheduling interval m/5 in all the items you are putting on the same graph. For good measure, make the regular interval value infrequent. I use a macro {$UPDATE_LONG}. What this does is force Zabbix to measure all the items at the same time, in this case every five minutes on minutes divisible by five. Once I did that my incoming bandwith item and its corresponding baseline item aligned nicely.
Low-level Discovery
I cottoned on to the utility of this part of Zabbix a little late. Hey, slow learner, but I eventually got there. What I found in my F5 devices is that using SNMP to monitor the /var filesystem was a snap: it was always device 32 (final OID digit). But /var/log monitoring? Not so much. Every device seemed different, with no obvious pattern. Active and standby units – identical hardware – and some would be 53, the partner 55. Then I rebooted a device and its number changed! So, clearly, dynamically assigned and no way was I going to keep up with it. I had learned the numbers by doing an snmpwalk. The solution to this dynamically changing OID number is to use low-level discovery.
Tip: using zabbix_sender in a more robust fashion
We run the Zabbix proxies as pairs. They are not run as a cluster. Instead one is active and the other is a warm standby. Then we can upgrade at our leisure the standby proxy, switch the hosts to it, then upgrade the other now-unused proxy.
But our scripts which send results using zabbix_sender run on other servers. Their data stops being recorded when the switch is made. What to do?
I learned you can send to both Zabbix proxies. It will fail on the standby one and succeed on the other. Since one proxy is always active, it will always succeed in sending its data!
A nice DNS synthetic monitor
It would have been so easy for Zabbix to have built in the capability of doing synthetic DNS checks against your DNS servers. But, alas, they left it out. Which leaves it to us to fill that gap. Here is a nice and simple but surprisingly effective script for doing synthetic DNS checks. You put it in the external script directory of whatever proxy is monitoring your DNS host. I called it dns.sh.
#!/bin/sh
# arg1 - hostname of nameserver
# arg2 - DNS server to test
# arg3 - FQDN
# arg4 - RR type
# arg5 - match arg
# [arg6] - tcpflag # this argument is optional
# if you set DEBUG=1, and debug through zabbix, set item type to text
DEBUG=0
timeout=2 # secs - seems a good value
name=$1
nameserver=$2
record=$3
type=$4
match=$5
tcpflag=$6
[[ "$DEBUG" -eq "1" ]] && echo "name: $name, nameserver: $nameserver , record: $record , type: $type , match pattern: $match, tcpflag: $tcpflag"
[[ "$tcpflag" = "y" ]] || [[ "$tcpflag" = "Y" ]] && PROTO="+tcp"
# unless you set tries to 1 it will try three times by default!
MATCH=$(dig +noedns +short $PROTO +timeout=$timeout +tries=1 $type $record @${nameserver} )
[[ "$DEBUG" -eq "1" ]] && echo MATCHed line is $MATCH
return=0
[[ "$MATCH" =~ $match ]] && return=1
[[ "$DEBUG" -eq "1" ]] && echo return $return
echo $return
It gives a value of 1 if it matched the match expression, 0 otherwise.
With Zabbix version 7 we finally replaced this nice external dns.sh script with built-in agent items. But it was a little tricky to throw that sort of item into a template – we had to define a host maro containing the IP of the host!
Convert a string to a number in item output
I’ve been bit by this a couple times. Create a dependent item. In the preprocessing steps first do a RegEx match and keep \0. Important to also check the Custom on Fail checkbox. Set value to 0 on fail. In the second step I used a replace and replaced the expected string with a 1.
I had a harder case where the RegEx had alternate strings. But that’s solvable as well! I created additional Replace steps with all possible alternate strings, setting each one to be replaced with 1. Kludge, yes, but it works. And that is how you turn a text item into a boolean style output of 0 or 1.
Conclusion
A couple of really useful but poorly documented items are shared. Perhaps more will be added in the future.
Intro
I panned Zabbix in this post: DIY monitoring. But I have compelling reasons to revisit it. I have to say it has matured, but there remain some very frustrating things about it, especially when compared with SiteScope (now owned by Microfocus) which is so much more intuitive.
But I am impressed by the breadth of the user base and the documentation. But learning how to do any specific thing is still an exercise in futility.
I am going to try to structure this post as a problems encountered, and how they were resolved.
Current production version as of this writing? Answer: 7.0
Zabbix Manual does not work in Firefox
That’s right. I can’t even read the manual in my version of Firefox. Its sections do not expand. Solution: use Chrome
Which database?
You may see references to MYSQL in Zabbix docs. MYSQL is basically dead. what should you do?
Zabbix quick install on Redhat
Answer
Install mariadb which has replaced MYSQL and supports the same commands such as the mysql from the screenshot. On my Redhat instance I have installed these mariadb-related repositories:
Terminology confusion
what is a host, a host group, a template, an item, a web scenario, a trigger, a media type?
Answer
Don’t ask me. When I make progress I’ll post it here.
Web scenario specific issues
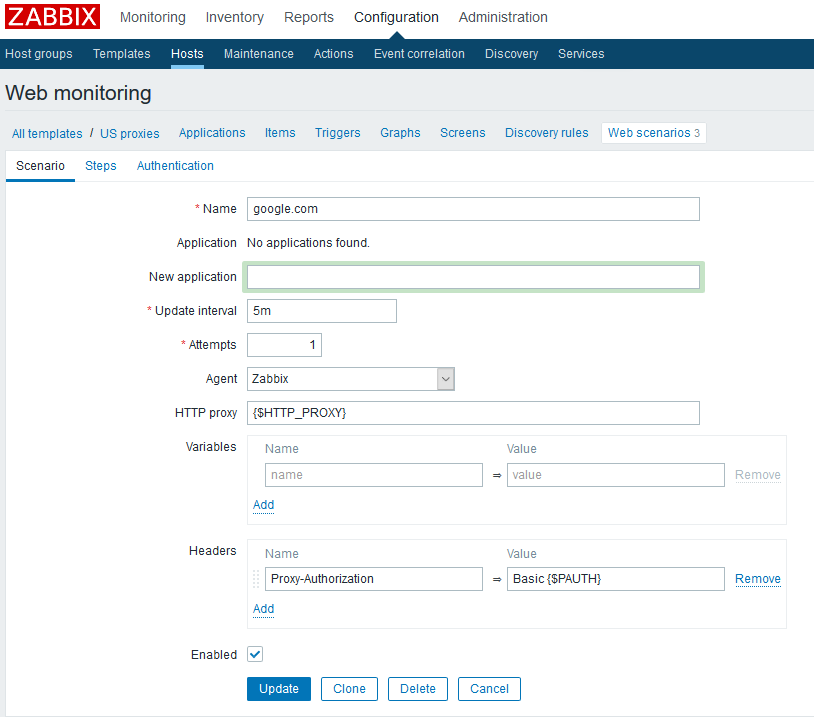
Can different web scenarios use different proxies?
Answer: Yes, no problem. In really old versions this was not possible. See web scenario screenshot below.
Can the proxy be a variable so that the same web scenario can be used for different proxies?
Answer: Yes. Let’s say you attach a web scenario to a host. In that host’s configuration you can define a “macro” which sets the variable value. e.g., the value of HTTP_PROXY in my example. I think you can do the same from a template, but I’m getting ahead of myself.
Similarly, can you do basic proxy auth and hide the credentials in a MACRO? Answer: I think so. I did it once at any rate. See above screenshot.
Why does my google.com web scenario work whereas my amazon.com scenario not when they’re exactly the same except for the URL? Answer: some ideas, but the logging information is bad. Amazon does not take to bots hitting it for health check reasons. It may work better to change the agent type to Linux|Chrome, which is what I am trying now. Here’s my original answer: Even with command-line curl I get an error through this proxy. That can’t be good:
$ curl ‐vikL www.amazon.com
My amazon.com web scenario is not working (status of 1), yet in dashboard does not return any obvious warning or error or red color. Why? Answer: no idea. Maybe you have to define a trigger?
Say you’re on the Monitoring|latest data screen. Does the data get auto-updated? Answer: yes, it seems to refresh every 30 seconds.
In Zabbix Latest Data can you control the history displayed via url parameters? By default only one hour of history is displayed. Answer: There is an undocumented feature I have discovered which permits this. Let’s say your normal URL for your direct link to the latest data of item 1234 is https://drjohns.com/history.php?action=showgraph&itemids[]=1234. The modified version of that to display the last day of data is: https://drjohns.com/history.php?action=showgraph&from=now-1d&to=now&itemids[]=1234
In latest data viewing the graph for one item which has a trigger, sometimes the trigger line is displayed as a dashed line and sometimes not at all. Answer: From what I can tell the threshold line is only displayed if the threshold was entered as a number in the trigger condition. Strange. Unfortunate if true.
Why is the official FAQ so useless? Answer: no idea how a piece of software otherwise so feature-rich could have such a useless FAQ.
Zabbix costs nothing. Is it still actively supported? Answer: it seems very actively supported for some reason. Not sure what the revenue model is, however…
Can I force one or more web scenarios to be run immediately? I do this all the time in SiteScope. Answer: I guess not. There is no obvious way.
Suppose you have defined an item. what is the item key? Answer: You define it. Best to make it unique and use contiguous characters. I’m seeing it’s very important…
What is the equivalent to SiteScope’s script monitors? Answer: Either ssh check or external check.
How would you set up a simple PING monitor, i.e., to see if your host is up? Answer: Create an item as a “simple check”, e.g., with the name ping this host, and the key icmpping[{HOST.IP},3]. That can go into a template, by the way. If it succeeded it will return a 1.
I’ve made an error in my script for an external check. Why does Latest data show nothing at all? Answer: no idea. If the error is bad enough Zabbix will disable the item on you, so it’s not really running any longer. But even when it doesn’t do that, a lot of times I simply see no output whatsoever. Very frustrating.
Help! The Latest Data graph’s Y axis only shows 0’s and 5’s. Answer: Another wonderful Zabbix feature, this happens because your Units are too long. Even “per minute” as Units can get you into trouble if it is trying to draw a Y axis with values 22.0 22.5 23.0, etc: you’ll only see the .0’s and the .5’s. Change units to a maximum of seven characters such as “per min.”
Why is the output from an ssh check truncated, where does the rest go? Answer: no idea.
How do you increase the information contained in the zabbix server log? Let’s say your zabbix server is running normally. Then run this command: zabbix_server ‐R log_level_increase
You can run it multiple times to keep increasing the verbosity (log level), I think.
Attempting to use ssh items with key authentication fails with :”Public key authentication failed: Callback returned error” Initially I thought Zabbix was broken with regards to ssh public key authentication. I can get it to work with password. I can use my public/private key to authenticate by hand from command-line as root. Turns out running command such as sudo -u zabbix ssh … showed that my zabbix account did not have permissions to write to its home directory (which did not even exist). I guess this is a case of RTFM, because they do go over all those steps in the manual. I fixed up permissions and now it works for me, yeah.
Where should the scripts for external checks go? In my install it is /usr/lib/zabbix/externalscripts.
Why is the behaviour of triggers inconsistent. sometimes the same trigger has expected behaviour, sometimes not. Answer: No idea. Very frustrating. See more on that topic below.
How do you force a web scenario check when you are using templates? Answer: No idea.
Why do (resolved) Problems disappear no matter how you search for them if they are older than, say, 30 minutes? Answer: No idea. Just another stupid feature I guess.
Why does it say No media defined for user even though user has been set up with email as his media? Answer: no idea.
Why do too many errors disable an ssh check so that you get Status Disabled and have no graceful way to recover? Answer: no idea. It makes sense that Zabbix should not subject itself to too many consecutive errors. But once you’ve fixed the underlying problem the only recovery I can figure is to delete the item and recreate it. or delete the host and re-create it. Not cool.
I heard dependent items are the way to go to parse complex data coming out of a rich text item. How do you do that? Answer: Yes they are. I have gotten them to work and really give me the fine-grained control I’ve always wanted. I hope to show a real-life example soon. To get started creating a dependent item you can right-click on the dots of an item, or create a new item and choose type Dependent Item.
I am looking at Latest data and one item is grayed out and has no data. Why? Answer: almost no idea. This happens to me in a dependent item formed by a regular expression where the regular expression does not match the content. I am trying to make my RegEx more flexible to match both good and error conditions.
Why do my dependent items, when running a Check Now, say Cannot send request: wrong data type, yet they are producing data just fine when viewed through Latest data? Answer: this happens if you ran a Check Now on your template rather than when viewing an individual host. Make sure you select a host before you run Check Now. Actually, even still it does not work, so final answer: no idea.
Why do some regular expressions check out just fine on regex101.com yet produce a match for value of type “string”: pattern does not match error in Zabbix? Answer: Some idea. Fancy regular expressions do not seem to work for some reason.
Every time I add an item it takes the absolute maximum amount of time before I see data, whether or not I run check Now until I turn blue in the face. Why? Answer: no idea. Very frustrating.
If the Zabbix server is in one time zone and I am in another, can I have my view of timestamps customized to my time zone? Otherwise I see all times in the timezone of the Zabbix server. Answer: You are out of luck. The suggestion is to run two GUIs, one in your time zone. But there is a but. Support for this has been announced for v 5.20. Stay tuned…
My DNS queries using net.dns don’t do anything. Why? Answer: no idea. Maybe your host is not running an actual Zabbiox agent? That’ll do it. Forget that net.dns check if you can’t install an agent. Zabbix has no agentless DNS monitor for some strange reason.
A DNS query which returns many address records fails (such as querying an AD domain), though occasionally succeeds. Why?Answer: So your key looks something like this, right? net.dns.record[10.1.2.3,my-AD-domain.net,A,10,2,tcp]. And when you do the query through dig it works fine, right? E.g., dig +tcp my-AD-domain.net @10.1.2.3. And you’ve set the Zabbix response to type text? It seems to be just another Zabbix bug. You may have to use a script instead. Zabbix support has been able to reproduce this bug and they are working on it as we speak.
What does Check/Execute Now really do? Answer: this sometimes works and causes the itme to be run outside of its scheduled window, but it may takes a few seconds. However, if you have enough permissions, what you can do when you’re looking at an item for a specific Host is to run Test. Then Get Value. I sometimes get Permission Denied, however.
I want to show multiple things on a dashboard widget graph like an item plus its baseline (Ed: see references for calculating a baseline). What’s the best way? Answer: You can use the add new data set feature for instance to add your baseline. In your additional data set you put your baselines. Then I like to make the width 2, transparency 0 and fill 0. This will turn it into a thin bold line with a complementary color while not messing too much with the original colors of your items. The interface is squirrely, but, hey, it’s Zabbix, what did you expect?
I have a lot of hosts I want to add to a template. Does that Mass Update feature actually work? Answer: yes. Use it. It will save you time.
Help! I accidentally deleted an entire template. I meant to just delete one of its macros. Is there a revert? Answer: it doesn’t look like it. Hope you remember what you did…
It seems if I choose units in an item which have too many characters, e.g., client connections, the graph (in Latest Data) cuts it off and doesn’t even display the scale? Answer: seems so. It’s a bug. This won’t happen when using vector graphs in Dashboard. The graphs in Latest Data are PNG and limited to short Units, e.g., mbps. Changing to vector graphs has been in the roadmap but then disappeared.
Can I create a baseline? Nope. It’s on the roadmap. However, see this clever idea for building one on your own without too much effort.
I’ve put a few things on the same Dashboard graph. Why don’t they align? There are these big gaps. Zabbix runs the items when it feels like, and the result is gaps in data which Zabbix makes no attempt to conceal at the beginning and end of a graph. You can use Scheduling Intervals on your items to gain some control over this. See this article for details.
Besides cloning the whole thing, how can I change the name of a Dashboard? Answer: If you just click to edit a Dashboard the name appears fixed. However, click on the gear icon and that gives you the option to edit the dashboard name. It’s kind of an undocumented feature.
My SNMP MIB has bytes in/out for an interface when what I really want is bandwidth, i.e., Megabits per second. A little preprocessing on a 64-bit bytes value and you are there (32 bit values may roll over too frequently). See this article for details.
In functions like avg (sec|#num,<time_shift>), why is the time_shift argument so restricted? It can’t be a macro, contain a formula like 1w-30m, or anything semi-sophisticated. It just accepts a dumb literal like 5h? Answer: It’s just another shortcoming in Zabbix. How much did you pay for it? 🙂
I have an SNMP template with items for a hostgroup of dispersed servers. Some work fine. The one in Asia returns a few values, but not all. I am using Bulk Request.Answer (to your implied question!) You must have bad performance to that one. Use a Zabbix proxy with a longer timeout for SNMP requests. I was in that situation and that worked for me.
SNMPv3 situation. I have two identical virtual servers monitored by the same Zabbix proxy. Only one works. Command-line testing of snmpwalk looks fine. What could it be?’Answer: We are fighting this now. In our case the SNMP v3 engineIDs are identical on the two virtual servers because they were from the same image, whereas, if you read the specs, they are supposed to be unique, like a MAC address. Who knew? And, yes, once we made the engineIDs unique, they were fine in Zabbix.
Riddle: when is 80% not 80%? Answer: when pulling in used storage on a filesystem via SNMP and comparing it to storage size! I had carefully gotten a filesystem 83% full based on the output of df -m. But my trigger, set to go off at 80%, never went off. How could it be? The 83% includes some kind of reserved user space on the filesystem which is not included when you do the calculation directly. So I was at 78% or so in actuality. I changed the trigger to 75%.
My trigger for a DNS item, which relies on a simple diff(), goes off from time-to-time yet the response is the same. Why? Answer: We have seen this behavior for a CNAME DNS item. The response changed the case of the returned FQDN from time-to-time, and that is enough to set off the Zabbix diff()-based trigger! We pre-processed the output with a RegEx to just get the bits we wanted to examine to fix this.
Related question. My diff() trigger for a DNS item does NOT go off when the server actually goes down. What’s up with that? Answer: Although you might expect a suddenly unavailable server constitutes a “difference,” in Zabbix’s contorted view of reality it does not. I recommend an additional trigger using the function nodata().
Does the new feature of login using SAML actually work? Answer: Yes, we are using it in Zabbix v 5.0.
My OIDs for my filesystems keeps shifting around. What to do? Answer: Use low-level discovery. It’s yet another layer of abstraction and confusion, but it’s probably worth it. I intend to write up my approach in my practical Zabbix examples blog post.
After an Zabbix agent item goes bad (no data), Zabbix refuses to test it for a full 30 minutes after it went bad, despite an update interval of 5 minutes. Why? Answer: In one of the worst architectural decisions of all time, Zabbix created the concept of unsupported items. It works something like this: the very moment when you need to be told Hey there’s something wrong here is when Zabbix goes quiet. Your item became unsupported, which is like being in the penalty box for 30 minutes, during which time nothing works like you naively expected it to. Even the fact that your item becameunsupported is almost impossible to find out from a trigger. An example of software which treats this situation correctly is Microfocus SiteScope. In Zabbix in version 5.0 there’s a global timeout for all unsupported items. Ours is set to 30 minutes, you see. In some cases that may make sense and prevent Zabbix from consuming too many resources trying to measure things which don’t work. I find it annoying. For DNS, specifically, best to use a key of type net.dns and not net.dns.record. That returns a simple 0 or 1 and does not become unsupported if the dns server can’t be reached. V 5.2 will provide some more options around this issue. For a HTTP agent and I suppose many other items, it’s best to create triggers which use the nodata() function, which can somewhat compensate for this glaring weakness in Zabbix. If you run Zabbix v 5.2, you should use the new preprocessing rule “Check for not supported value” and then set new value e.g. “Error”. Then the Item won’t become unsupported and can also be used for triggers.
We’ve got SNMP items set up for a host. What’s the best way to alert for a total outage? Answer: I just learned this. This is closely related to the previous question. To avoid that whole unsupported item thing, you make a Zabbix internal item. the key is literally this: zabbix[host,snmp,available] and type is numeric unsigned. This wil continue to poll even if the other host items became unsupported. This is another poorly documented Zabbix feature.
While trying to set up a host for SNMP monitoring I get the error Cannot update Host. Cannot find host interface on host_name for item key item_name. Answer: You probably used an interface type of Agent instead of SNMP. Under Interfaces for the host, add one for type SNMP and remove the Agent one. Or, maybe the reverse: your item type is of type Zabbix agent but your host’s interface is of type SNMP – that combo also produces this error.
In Zabbix my SNMP item shows error No such instance currently exists at this OID, yet my snmpwalk for same shows it works. Why? Answer: In my case I switched to snmpget for my independent testing and reproduced that error, and found that I needed a literal .”0″ at the end of the OID (specifically for swap used on an F5 device). Once I included the .”0″ (with the double-quotes) in the OID in Zabbix it began to work. In another case I could do the snmpget from the same zabbix proxy where I was getting this error message. The custom MIB was right there in /usr/share/snmp/mibs on the Zabbix proxy. Zabbix hadn’t been started in awhile. I restarted it and the problem went away.
I wish to use a DNS value instead of an IP in net.tcp.service[service,IP,port] because I use geoDNS or round-robin DNS. Can I? Answer: It seems to work, yes.
Can I send alerts to MS teams? Answer: This is obviously a fake question. But the answer is Yes. You set up a Connector in a MS Teams channel. It’s pretty staight forward and it’s pretty cool. I’ll try to publish more in my Zabbix tips post if I have time.
Get a lot of false positives? Answer: Yes! On F5 equipment this one is vexing me:
Resolved: BIG-IP is unreachable via SNMP for 15 minutes
And for others (pool member unavailable for a few minutes) I tried to require two consecutive failures before sending an alert. Basically still working on it.
I have a bunch of HTTP items on this one Zabbix proxy. They all sort of go bad at the same time (false positives) and Zabbix says this agent is unreachable for five minutes around the same time. Answer: Seen that. Short term it may be advisable to create a dependent trigger: https://www.zabbix.com/documentation/5.0/manual/config/triggers/dependencies Mid-term I am going to ask support about this problem.
Why is the name field truncated in Monitoring | Latest Data, with no possibility to increase it? Answer: If you have Show Details selected you see very few characters. Deselect that.
What, Zabbix version 5.2 RPMs are not available for RHEL 7? Answer: that is correct, unfortunately, as of this writing. You can run as high as v 5.0.7. We are trying to pressure them to provide this compatibility. Lots of people still run Redhat v 7.
Can you send reminder alerts periodically for a problem which persists? Answer: Yes you can. For instance, every four hours. Read all about it in the manual, under Action | Escalations, and look at their examples. However, the documentation is at odds with the product’s behaviour if you have multiple alerts with different durations defined. I am studying it…
Is Zabbix affected by the same hack that infected SolarWinds? Answer: No idea. Let’s see. Developed in Eastern Europe. Basically, no one’s saying. Let’s hope not.
Is Zabbix stupid enough to send multiple alerts for the same problem? Answer: In a word, yes. If you are unlucky enough to have defined overlapping alert conditions in your various alerts, Zabbix will make no effort to consolidate them.
What does it mean when I look at a host and I see inaccessible template? Answer: Most likely explanation is that you don’t have permission to see that template.
Can the y-axis be drawn in a logarithmic scale in a dashboard graph? I have low values (time for a DNS query) which sometimes soar to high ones. Answer: No. This feature has been requested now for almost 10 years and still is lacking. I will try to make a feature request.
Why does our Zabbix agent time out so often? The message is Zabbix agent on hostname is unreachable for five minutes. The problem is sporadic but it really interferes with the items like our simple net.dns checks. Answer: If you use a lot of net.dns agent items you can actually cause this behavior if you are running agent2. The default agent item is passive. We had better luck using an Active Agent item. We had severe but random timeouts and they all went away.
Our Webhook to MS Teams was working fine. Then we set up a new one to a new channel which wouldn’t work at all. A brief error message says invalid Webhook or something. What’s the fix? Answer: It is a known bug which is fixed in v 5.0.8. Of course a lot else could be wrong. In fairness Microsoft changes the format for webhooks from time-to-time so that could be the problem. This Microsoft page is a great resource to do your own testing of the Webhook: Sending messages to Connectors and Webhooks – Teams | Microsoft Docs
The formatting of alert emails is screwy, especially with line breaks in the wrong places. Can I force it to send HTML email to gain more control? Answer: Sort of. You can define a media type where you use HTML email instead of plain text email. I personally don’t have access to do that. But it is not possible to selectively use HTML email within the Custom email form of the alert setup screen. With the more straightforward custom emails, the trick is to put in extra line breaks. A single solitary linebreak is sometimes ignored, especially if the sequence is MACRO-FUNCTION linebreak more text. But if you use two consecutive linebreaks it will inject two linebreaks.
I swear Zabbix is ignoring my macros in trigger functions used in templates which refer to time values in minutes, and just filling in 0 instead. Is that even possible? Answer: I’m still investigating this one. I will withold my customary sardonic comments about Zabbix until I know who or what is to blame. [Later] I’m thinking this one is on me, not Zabbix.
Do Zabbix items, particularly HTTP items, have the concept of a hidden field to hide confidential data such as passwords from others with the same level of access? Answer: Apparently not. But if you believe in the terrible idea of security by obscurity, you can obscure values by stuffing them into a macro.
My Zabbix admin won’t let me get creative. No external items, no ssh items, etc. I can run some interesting scripts on my linux server. How to stuff the results into Zabbix? Answer: Install zabbix_sender utility on your linux. Then set up an item of type Zabbix trapper. The link to the RPM for zabbix_sender is in the references.
These days nothing is either black or white. So when a trigger fires, it’s likely it will return to good status, and then bad, and then good, etc. The alerts are killing us and casual users tend to discount all of them. What to do? Answer: This is common-sense, but, a very good strategy in these cases is to define a recovery expression for that trigger that looks at the average value for the last 3600 seconds and requires it to be in the good range before the trigger that all is good gets sent out as an alert.
I’m using the dynamic host feature in a dashboard. Unfortunately, one of my hosts has a really short name that matches so many other hosts that it never appears in the drop-down list. What to do? Answer: Click the “select” button to the right of the search field. Then you can choose the host group and from there the host. Or rename the host to somethng more unique.
I wish to add some explanatory text in the dashboard I’ve created. Is it possible? Answer: This is laughably kludgy, but you can do this with a map widget. What you can do is to create a map, add a text box to it, and put your desired text into the text box. But it is hard to get the sizing correct as things shrink when putting the widget on the dashboard.
My top hosts widget is now displaying 0’s. Answer: This happened after we upgraded from v 6.0 to 6.0.8. In characteristically Zabbix illogical fashion, if you now sort by BottomN instead of TopN you should see the expected results (highest on top). Not all our widgets displayed this bug!
I have an item which only runs once a week. Monitoring > Latest Data doesn’t show any values. Is that a bug or feature? Answer: There is a setting somewhere where you can change this behavior. Set it to last two weeks and all will be well.
While using the pyzabbix Zabbix api I had trouble switching from username/password to use an authentication token. Answer: Perhaps yuo installed both py-zabbix as well as pyzabbix? I’m confused by this. as there is some overlap. To use the token auth method – preferred by experts – uninstall both these packages and re-install only pyzabbix. I will give an example in my other Zabbix blog post, Practical Zabbix examples.
The trigger.create api call says a dependent triggerid must be passed? Is that really mandatory? It makes no sense. Answer: No. I experimented with it and found you can just leave the dependencies out altogether. The documentation is wrong.
I need to create about 100 custom alerts. Is there seriously no way to do this via the api? Answer: apparently not.
What’s the correct way to send a compound filter expression via the api? Answer: Watch out! If you are trying to filter on suppressed problems, do not put a reference to suppressed in your filter. Instead it goes outside the filter like so: zapi.problem.get(…,suppressed=False,filter={‘name’:…})
Monitoring > Problems > History view is slow. Then it grays out periodically. Answer: Zabbix is spending all its time figuring out which host groups you have access to. To speed things up, explicitly enter only your accessible host groups in the filter.
geoMAP in Zabbix 6.0 is cool until you blow up a continent and see all the local geographical names written in their native language. So Asian placenames are inscrutable to Enlgih speakers. Is there any fix? Answer: You are probably using the provider, OpenStreetMap in this case, which is using localized names. You can switch providers (global setting).
I’m using a RegEx in the regsub function on an LLD macro. What flavor of RegEx are supported and what characters need to be escaped? Answer: Supposedly Perl-compatible (PCRE) RegExes are supported. For anything remotely complex, enclose your RegEx in double-quotes. Then, for good measure put a backslash (\) in front of any double-quote (“) you require as a match character, and a backslash in front of any slash (/) match character, plus the usual rules.
Why am I seeing the same host graph twice? Answer: This is a bug I have personally discovered in Zabbix 6.0. It occurs when you have a template with just a single item and a single graph. They will be working on it as of August 2022.
In latest data I see: Value of type “string” is not suitable for value type “numeric unsigned.” Why? Answer: I got this in Zabbix 6.4 when I used zabbix_sender with argument -o 36 which I thought would feed in the integer 36. But no, it got interpreted as a string. I tried to introduce a preprcoessing step but I could not get it to work. In the end I created a dependent item with a RegEx to convert it. I made the original item type character. I could not beat this in a simple way.
I can’t get my new agent to be seen by its Zabbix proxy. Error is failed to accept an incoming connection: from [agent]: reading first byte from connection failed: [104] Connection reset. Answer: You may be running a Palo Alto firewall perhaps? They will permit the tcp handshake and then drop the connection with a “reset both sides.” which produces this error. Thus super simplified connection tests you run by hand with nc/nmp may appear to work.
I just created my first passive agent item. The agents log shows this error: failed to process an incoming connection from x.y.z.w: cannot accept unencrypted connection. Answer: I solved this issue by editing the agent’s config to have these lines TLSAccept=unencrypted and #TLSAccept=psk
I can only measure what I seek to know as an item with type Zabbix agent, e.g., net.dns.record for testing a dns server from a Zabbix agent. Yet I want that item to be associated with the target and not so much with the agent running the item so I can create normal triggers. Answer: On your host dns server, create a calculated item and use a function such as last(/host/key) to pull in the results from the agent! Wish I had known that about four years ago!
Does changing the name of a host change its hostid? Answer: No. We have a multi-stage discovery process which relies on this fact.
Does the hosts IP filter accept a subnet mask? Answer: No, it is very primitive. It does accept a partial IP, strangely enough, so 10.9.9 matches 10.9.9.0/24.
Why is the simple item type so darn simple? In udp-land the only thing you can check is ntp. Answer: It is unfortunate, isn’t it? I need a simple DNS service check.
In preprocessing of an item, do the things in Validation produce a boolean value? Answer: That would make sense, wouldn’t it? So of course in keeping with the mantra that nothing in Zabbix should be intuitive, that is not the case. See my Prtactical Zabbix Examples for a workaround.
I have an item which is never runs, yet testing it or executing it produces the exepected results. Answer: You will do a head-slap. This happened to us recently when someone set the Update Interval to 300. It just never ran. You need to put the time quantifier in the update Interval such as 300s or 5m!
I get this error, even while testing an SSH agent item type with known good username/password: Password authentication failed: Access denied for ‘password’. Authentication that can continue: publickey,password,keyboard-interactive. Answer: When this happened to me I tested the ssh from the Zabbix proxy and found it had an old key for the host in /root/.ssh/known_hosts. I manually deleted the offending entry and all was good.
A word about SSH checks and triggers
Through the school of hard knocks I have learned that my ssh check is clipping the output from the executed command. So you know that partial data you see when you look at latest data, and thought it was truncating it for display purposes? Nuh, ah. That’s all you’re getting to go up against in your trigger, which sucks. It’s something like 260 characters. I got lucky in a sense to discover this early by running an ssh check against dns resolution of amazon.com. The response I got varied almost every 60 seconds depending on whether or not the response came out of the dns cache. So this was an excellent testbed to learn about the flakiness of triggers as well as waste an entire day.
Another thing about triggers with a regex. As far as I can tell the logic is reversed. So you think you’re defining the OK condition when you seek to match the output and have it given the value of 1. But instead try to match the desired output for the OK condition, but assign it a value of 0. I guess. Only that approach seems to work for me. And getting the regex to treat multiple lines as a unit was also a little tricky. I think by default it favored testing only against the last line.
So let’s say my output as scraped from Monitoring|Latest Data alternated between either
proxy1>test dns amazon.com
Performing DNS lookup for: amazon.com
DNS Response data:
Official Host Name: amazon.com
Resolved Addresses:
205.251.242.103
176.32.98.166
176.32.103.205
Cache TTL: 1, cache HIT
DNS Resolver Response: Success
proxy1>test dns amazon.com
Performing DNS lookup for: amazon.com
DNS Response data:
Official Host Name: amazon.com
Resolved Addresses:
205.251.242.103
176.32.98.166
176.32.103.205
Cache TTL: 1, cache HIT
DNS Resolver Response: Success
or
proxy1>test dns amazon.com
Performing DNS lookup for: amazon.com
Sending A query for amazon.com to 192.168.135.145.
Sending A query for amazon.com to 8.8.8.8.
DNS Response data:
Official Host Name: amazon.com
Resolved Addresses:
20
proxy1>test dns amazon.com
Performing DNS lookup for: amazon.com
Sending A query for amazon.com to 192.168.135.145.
Sending A query for amazon.com to 8.8.8.8.
DNS Response data:
Official Host Name: amazon.com
Resolved Addresses:
20
, then here is my iregexp expression which seems to do the correct thing (treat both of these outcomes as successes):
{proxy1:ssh.run[resolve DNS,1.2.3.4,22,utf-8].iregexp("(?s)((205\.251\.|176\.32\.)|Sending A query.+\s20)")}=0
{proxy1:ssh.run[resolve DNS,1.2.3.4,22,utf-8].iregexp("(?s)((205\.251\.|176\.32\.)|Sending A query.+\s20)")}=0
Note that the (?s) at the beginning helps, I think, to treat the newline character as just another character which matches “.”. I may have an extra set of parentheses around the outermost alternating expression, but I can only experiment so much…
I ran various tests such as to change just one of the numbers to make sure it triggered.
I now think I will get better, i.e., more complete, results if I make the item of type text rather than character, at least that switch definitely helped with another truncated output I was getting from another ssh check. So, yes, now I am capturing all the output. So, note to self, use type text unless you have really brief output from your ssh check.
So with all that gained knowledge, my simplified expression now reads like this:
{proxy:ssh.run[resolve a dns name,1.2.3.4,22,utf-8].iregexp("(205\.251\.|176\.32\.)")}=0
{proxy:ssh.run[resolve a dns name,1.2.3.4,22,utf-8].iregexp("(205\.251\.|176\.32\.)")}=0
Here’s a CPU trigger. From a show status it focuses on the line:
CPU utilization: 29%
and so if I want to trigger a problem for 95% or higher CPU, this expression works for me:
So I will accept the results as OK as long as at most one of five packets was dropped.
A lesson learned from SNMP monitoring of F5 devices
My F5 BigIP devices began producing problems as soon as we set up the SNMP monitoring. Something like this:
Node /Common/drj-10_1_2_3 is not available in some capacity: blue (4)
Node /Common/drj-10_1_2_3 is not available in some capacity: blue (4)
It never seemed to matter until now that my nodes appear blue. But perhaps SNMP is enforcing a best practice and expecting nodes to not be blue, meaning to be monitored. And it turns out you can set up a default monitor for your nodes (I use gateway_icmp). It’s found in Nodes | Default Monitor. I’m not sure why this is not better documented by F5. After this, many legacy nodes turn red so I am cleaning them up… But my conclusion is that I have learned something about my own systems from the act of implementing this monitoring, and that’s a good thing.
To be continued…
References and related
A good commercial solution for infrastructure monitoring: Microfocus SiteScope.
Just to put it out there: If you like Zabbix you may also like Specto. Specto is an open-source tool for monitoring web sites (“synthetic” monitoring). I know one major organization which uses it so it can’t be too bad. https://specto.sourceforge.net/
Since this document is such a mess I’m starting to document some of my interesting items and Practical Zabbix examples in this newer and cleaner post. It includes the baseline calculation formula.
Intro
A large organization needed to have considerable flexibility in serving out its proxy PAC file to web browsers. The legacy approach – perl script on web servers – was replaced by a TCL script I developed which runs on one of their F5 load balancers. In this post I lay out the requirements and how I tackled an unfamiliar language, TCL, to come up with an efficient and elegant solution.
Even if you have no interest in PAC files, if you are developing an irule you’ll probably scratch your head figuring out the oddities of TCL programming. This post may help in that case too.
The irule
# - DrJ 8/3/17
when CLIENT_ACCEPTED {set cip [IP::client_addr]}
when HTTP_REQUEST {set debug 0# supply an X-DRJ-PAC, e.g., w/ curl, to debug: curl -H 'X-DRJ-PAC: 1.2.3.4' 50.17.188.196/proxy.pacif{[HTTP::header exists "X-DRJ-PAC"]}{
# overwrite client ip from header value for debugging purposes
log local0. "DEBUG enabled. Original ip: $cip"set cip [HTTP::header value "X-DRJ-PAC"]set debug 1
log local0. "DEBUG. overwritten ip: $cip"}
# security precaution: don't accept any old uriif{!([HTTP::uri] starts_with "/proxy.pac" || [HTTP::uri] starts_with "/proxy/proxy.cgi")}{
drop
log local0. "uri: [HTTP::uri], drop section. cip: $cip"}else{
#set LDAPSUFFIX ""if{[HTTP::uri] ends_with "cgi"}{set LDAPSUFFIX "-ldap"}# determine which central location to useif{[class match $cip equals PAC-subnet-list]}{
# If client IP is in the datagroup, send user to appropriate locationset LOCATION [class lookup $cip PAC-subnet-list]if{$debug}{log local0. "DEBUG. match list: LOCATION: $LOCATION"}}elseif{$cip ends_with "0" || $cip ends_with "1" || $cip ends_with "4" || $cip ends_with "5"}{
# client IP was not amongst the subnets, use matching of last digit of last octet to set the NJ proxy (01)set LOCATION "01"if{$debug}{log local0. "DEBUG. match last digit prefers NJ : LOCATION: $LOCATION"}}else{
# set LA proxy (02) as the default choiceset LOCATION "02"if{$debug}{log local0. "DEBUG. neither match list nor match digit matched: LOCATION: $LOCATION"}}
HTTP::respond200 content "
function FindProxyForURL(url, host)
{
// o365 and other enterprise sites handled by dedicated proxy...
var cesiteslist = \"*.aadrm.com;*.activedirectory.windowsazure.com;*.cloudapp.net;*.live.com;*.microsoft.com;*.microsoftonline-p.com;*.microsoftonline-p.net;*.microsoftonline.com;*.microsoftonlineimages.com;*.microsoftonlinesupport.net;*.msecnd.net;*.msn.co.jp;*.msn.co.uk;*.msn.com;*.msocdn.com;*.office.com;*.office.net;*.office365.com;*.onmicrosoft.com;*.outlook.com;*.phonefactor.net;*.sharepoint.com;*.windows.net;*.live.net;*.msedge.net;*.onenote.com;*.windows.com\";
var cesites = cesiteslist.split(\";\");
for (var i = 0; i < cesites.length; ++i){
if (shExpMatch(host, cesites\[i\])) {
return \"PROXY http-ceproxy-$LOCATION.drjohns.net:8081\" ;
}
}
// client IP: $cip.
// Direct connections to local domain
if (dnsDomainIs(host, \"127.0.0.1\") ||
dnsDomainIs(host, \".drjohns.com\") ||
dnsDomainIs(host, \".drjohnstechtalk.com\") ||
dnsDomainIs(host, \".vmanswer.com\") ||
dnsDomainIs(host, \".johnstechtalk.com\") ||
dnsDomainIs(host, \"localdomain\") ||
dnsDomainIs(host, \".drjohns.net\") ||
dnsDomainIs(host, \".local\") ||
shExpMatch(host, \"10.*\") ||
shExpMatch(host, \"192.168.*\") ||
shExpMatch(host, \"172.16.*\") ||
isPlainHostName(host)
) {
return \"DIRECT\";
}
else
{
return \"PROXY http-proxy-$LOCATION$LDAPSUFFIX.drjohns.net:8081\" ;
}
}
" \
"Content-Type""application/x-ns-proxy-autoconfig" \
"Expires""[clock format [expr ([clock seconds]+7200)] -format "%a, %d %h %Y %T GMT" -gmt true]"}}
# - DrJ 8/3/17
when CLIENT_ACCEPTED {
set cip [IP::client_addr]
}
when HTTP_REQUEST {
set debug 0
# supply an X-DRJ-PAC, e.g., w/ curl, to debug: curl -H 'X-DRJ-PAC: 1.2.3.4' 50.17.188.196/proxy.pac
if {[HTTP::header exists "X-DRJ-PAC"]} {
# overwrite client ip from header value for debugging purposes
log local0. "DEBUG enabled. Original ip: $cip"
set cip [HTTP::header value "X-DRJ-PAC"]
set debug 1
log local0. "DEBUG. overwritten ip: $cip"
}
# security precaution: don't accept any old uri
if { ! ([HTTP::uri] starts_with "/proxy.pac" || [HTTP::uri] starts_with "/proxy/proxy.cgi") } {
drop
log local0. "uri: [HTTP::uri], drop section. cip: $cip"
} else {
#
set LDAPSUFFIX ""
if {[HTTP::uri] ends_with "cgi"} {
set LDAPSUFFIX "-ldap"
}
# determine which central location to use
if { [class match $cip equals PAC-subnet-list] } {
# If client IP is in the datagroup, send user to appropriate location
set LOCATION [class lookup $cip PAC-subnet-list]
if {$debug} {log local0. "DEBUG. match list: LOCATION: $LOCATION"}
} elseif { $cip ends_with "0" || $cip ends_with "1" || $cip ends_with "4" || $cip ends_with "5" } {
# client IP was not amongst the subnets, use matching of last digit of last octet to set the NJ proxy (01)
set LOCATION "01"
if {$debug} {log local0. "DEBUG. match last digit prefers NJ : LOCATION: $LOCATION"}
} else {
# set LA proxy (02) as the default choice
set LOCATION "02"
if {$debug} {log local0. "DEBUG. neither match list nor match digit matched: LOCATION: $LOCATION"}
}
HTTP::respond 200 content "
function FindProxyForURL(url, host)
{
// o365 and other enterprise sites handled by dedicated proxy...
var cesiteslist = \"*.aadrm.com;*.activedirectory.windowsazure.com;*.cloudapp.net;*.live.com;*.microsoft.com;*.microsoftonline-p.com;*.microsoftonline-p.net;*.microsoftonline.com;*.microsoftonlineimages.com;*.microsoftonlinesupport.net;*.msecnd.net;*.msn.co.jp;*.msn.co.uk;*.msn.com;*.msocdn.com;*.office.com;*.office.net;*.office365.com;*.onmicrosoft.com;*.outlook.com;*.phonefactor.net;*.sharepoint.com;*.windows.net;*.live.net;*.msedge.net;*.onenote.com;*.windows.com\";
var cesites = cesiteslist.split(\";\");
for (var i = 0; i < cesites.length; ++i){
if (shExpMatch(host, cesites\[i\])) {
return \"PROXY http-ceproxy-$LOCATION.drjohns.net:8081\" ;
}
}
// client IP: $cip.
// Direct connections to local domain
if (dnsDomainIs(host, \"127.0.0.1\") ||
dnsDomainIs(host, \".drjohns.com\") ||
dnsDomainIs(host, \".drjohnstechtalk.com\") ||
dnsDomainIs(host, \".vmanswer.com\") ||
dnsDomainIs(host, \".johnstechtalk.com\") ||
dnsDomainIs(host, \"localdomain\") ||
dnsDomainIs(host, \".drjohns.net\") ||
dnsDomainIs(host, \".local\") ||
shExpMatch(host, \"10.*\") ||
shExpMatch(host, \"192.168.*\") ||
shExpMatch(host, \"172.16.*\") ||
isPlainHostName(host)
) {
return \"DIRECT\";
}
else
{
return \"PROXY http-proxy-$LOCATION$LDAPSUFFIX.drjohns.net:8081\" ;
}
}
" \
"Content-Type" "application/x-ns-proxy-autoconfig" \
"Expires" "[clock format [expr ([clock seconds]+7200)] -format "%a, %d %h %Y %T GMT" -gmt true]"
}
}
I know general programming concepts but before starting on this project, not how to realize my ideas in F5’s version of TCL. So I broke all the tasks into little pieces and demonstrated that I had mastered each one. I describe in this blog post all that I leanred.
How to use the browser’s IP in an iRule
If you’ve ever written an iRule you’ve probably used the section that starts with when HTTP_REQUEST. But that is not where you pick up the web browser’s IP. For that you go to a different section, when CLIENT_ACCEPTED. Then you throw it into a variable cip like this:
set cip [IP::client_addr]
And you can subsequently refer back to $cip in the when HTTP_REQUEST section.
How to send HTML (or Javascript) body content
It’s also not clear you can use an iRule by itself to send either HTML or Javascript in this case. After all until this point I’ve always had a back-end load balancer for that purpose. But in fact you don’t need a back-end web server at all. The secret is this line:
HTTP::respond200 content "
function FindProxyForURL(url, host)
...
HTTP::respond 200 content "
function FindProxyForURL(url, host)
...
So with this command you set the HTTP response status (200 is an OK) as well as send the body.
Variable interpolation in the body
If the body begins with ” it will do variable interpolation (that’s what we Perl programmers call it, anyway, where your variables like $cip get turned into their value before being delivered to the user). You can also begin the body with a {, but what follows that is a string literal which means no variable interpolation.
The bad thing about the ” character is that if your body contains the ” character, or a [ or ], you have to escape each and every one. And mine does – a lot of them in fact.
But if you use { you don’t have to escape characters, even $, but you also don’t have a way to say “these bits are variables, interpolate them.” So if your string is dynamic you pretty mcuh have to use “.
Defeat scanners
This irule will be the resource for a VS (virtual server) which effectively acts like a web server. So dumb enterprise scanners will probably come across it and scan for vulnerabilities, whether it makes sense or not. A common thing is for these scanners to scan with random URIs that some web servers are vulnerable to. My first implementation had this VS respond to any URI with the PAC file! I don’t think that’s desirable. Just my gut feeling. We’re expecting to be called by one of two different names. Hence this logic:
if { ! ([HTTP::uri] starts_with "/proxy.pac" || [HTTP::uri] starts_with "/proxy/proxy.cgi") } {
drop
...
else
(send PAC file)
The original match operator was equals, but I found that some rogue program actually appends ?Type=WMT to the normal PAC URL! How annoying. That rogue application, by the way, seems to be Windows Media Player. You can kind of see where they were goinog with this, for Windows Media PLayer you might want to present a different set of proxies, I suppose.
Match IP against a list of subnets and pull out value
Some background. Company has two proxies with identical names except one ends in 01, the other in 02. 01 and 02 are in different locales. So we created a data group of type address: PAC-subnet-list. The idea is you put in a subnet, e.g., 10.9.7.0/24 and a proxy value, either “01” or “02”. This TCL line checks if the client IP matches one of the subnets we’ve entered into the datagroup:
if{[class match $cip equals PAC-subnet-list]}{
if { [class match $cip equals PAC-subnet-list] } {
Then this tcl line is used to match the client IP against one of those subnets and retrieve the value and store it into variable LOCATION:
set LOCATION [class lookup $cip PAC-subnet-list]
set LOCATION [class lookup $cip PAC-subnet-list]
The reason for the datagroup is to have subnets with LAN-speed connection to one of the proxies use that proxy.
Something weird
Now something weird happens. For clients within a subnet that doesn’t match our list, we more-or-less distribute their use of both proxies equally. So at a remote site, users with IPs ending in 0, 1, 4, or 5 use proxy 01:
and everyone else uses proxy 02. So users can be sitting right next to each other, each using a proxy at a different location.
Why didn’t we use a regular expression, besides the fact that we don’t know the syntax 😉 ? You read about regular expressions in the F5 Devcentral web site and the first thing it says is don’t use them! Use something else like start_with, ends_with, … I guess the alternatives will be more efficient.
Further complexity: different proxies if called by different name
Some specialized desktops are configured to use a PAC file which ends in /proxy/proxy.cgi. This PAC file hands out different proxies which do LDAP authentication, as opposed to NTLM/IWA authentication.. Hence the use of the variable LDAPSUFFIX. The rest of the logic is the same however.
Debugging help
I like this part – where it helps you debug the thing. Because you want to know what it’s really doing and that can be pretty hard to find out, right? You could run a trace but that’s not fun. So I create this way to do debugging.
if {[HTTP::header exists "X-DRJ-PAC"]} {
# overwrite client ip from header value for debugging purposes
log local0. "DEBUG enabled. Original ip: $cip"
set cip [HTTP::header value "X-DRJ-PAC"]
set debug 1
log local0. "DEBUG. overwritten ip: $cip"
}
if {[HTTP::header exists "X-DRJ-PAC"]} {
# overwrite client ip from header value for debugging purposes
log local0. "DEBUG enabled. Original ip: $cip"
set cip [HTTP::header value "X-DRJ-PAC"]
set debug 1
log local0. "DEBUG. overwritten ip: $cip"
}
It checks for a custom HTTP request header, X-DRJ-PAC. You can call it with that header, from anywhere, and for the value put the client iP you wish to test, e.g., 1.2.3.4. That will overwrite the client IP varibale, cip, set the debug variable, and add some log lines which get nicely printed out into your /var/log/ltm file. So your ltm file may log info about your script’s goings-on like this:
Aug 8 14:06:48 f5drj1 info tmm[17767]: Rule /Common/PAC-irule : DEBUG enabled. Original ip: 11.195.136.89
Aug 8 14:06:48 f5drj1 info tmm[17767]: Rule /Common/PAC-irule : DEBUG. overwritten ip: 12.196.68.91
Aug 8 14:06:48 f5drj1 info tmm[17767]: Rule /Common/PAC-irule : DEBUG. match last digit prefers NJ : LOCATION: 01
Aug 8 14:06:48 f5drj1 info tmm[17767]: Rule /Common/PAC-irule : DEBUG enabled. Original ip: 11.195.136.89
Aug 8 14:06:48 f5drj1 info tmm[17767]: Rule /Common/PAC-irule : DEBUG. overwritten ip: 12.196.68.91
Aug 8 14:06:48 f5drj1 info tmm[17767]: Rule /Common/PAC-irule : DEBUG. match last digit prefers NJ : LOCATION: 01
And with curl it is not hard at all to send this custom header as I mention in the comments:
Expires header
We add an expires header so that the PAC file is good for two hours (7200 seconds). I don’t think it does much good but it seems like the right thing to do. Don’t ask me, I just stole the whole line from f5devcentral.
A PAC file should have the MIME type application/x-ns-proxy-autoconfig. So we set that explicit MIME type with
The “\” at the end of some lines is a line continuation character.
Performance
They basically need this to run several hundred times per second. Occasionally PAC file requests “go crazy.” Will it? This part I don’t know. It has yet to be battle-tested. But it is production tested. It’s been in production for over a week. The virtual server consumes 0% of the load balancer’s CPU, which is great. And for the record, the traffic is 0.17% of total traffic from the proxy server, so very modest. So at this point I believe it will survive a usage storm much better than my apache web servers did.
Why bother?
After I did all this work someone pointed out that this all could have been done within the Javascript of the PAC file itself! I hadn’t really thought that through. But we agreed that doesn’t feel right and may force the browser to do more evaluation than what we want. But maybe it would have executed once and the results cached somehow?? It’s hard to see how since each encountered web site could have potentially a different proxy or none at all so an evaluation should be done each time. So we always try to pass out a minimal PAC file for that reason.
Why not use Bluecoat native PAC handling ability?
Bluecoat proxySG is great at handing out a single, fixed PAC file. It’s not so good at handing out different PAC files, and I felt it was just too much work to force it to do so.
References and related
F5’s DevCentral site is invaluable and the place where I learned virtually everything that went into the irule shown above. devcentral.f5.com Excessive calls to PAC file.
Intro
F5’s BigIP load balancers have an API accessible via iRules which are written in their bastardized version of the TCL language.
I wanted to map all incoming source IPs to a unique source IP belonging to the load balancer (source NAT or snat) to avoid session stealing issues encountered in GUIxt.
First iteration
In my first approach, which was more proof-of-concept, I endeavored to preserve the original 4th octet of the scanner’s IP address (scanners are the users of GUIxt which itself is just a gateway to an SAP load balancer). I have three unused class C subnets available to me on the load balancer. So I took the third octet and did a modulo 3 operation to effectively randomly spread out the IPs in hopes of avoiding overlaps.
rule snat-test2 {
# see https://devcentral.f5.com/questions/snat-selected-source-addresses-on-a-vs# and https://devcentral.f5.com/questions/load-balance-on-source-ip-address# spread things out by taking modulus of 3rd octet# - DrJ 2/11/16
when CLIENT_ACCEPTED {
# maybe IP::client_addrset snat_Subnet_base "141"set ip3 [lindex[split[IP::client_addr]"."]2]set ip4 [lindex[split[IP::client_addr]"."]3]set offset [expr$ip3%3]set snat_Subnet [expr$snat_Subnet_base + $offset]set newip "10.112.$snat_Subnet.$ip4"# log local0. "Client IP: [IP::client_addr], ip4: $ip4, ip3: $ip3, offset: $offset, newip: $newip"
snat $newip}}
rule snat-test2 {
# see https://devcentral.f5.com/questions/snat-selected-source-addresses-on-a-vs
# and https://devcentral.f5.com/questions/load-balance-on-source-ip-address
# spread things out by taking modulus of 3rd octet
# - DrJ 2/11/16
when CLIENT_ACCEPTED {
# maybe IP::client_addr
set snat_Subnet_base "141"
set ip3 [lindex [split [IP::client_addr] "."] 2]
set ip4 [lindex [split [IP::client_addr] "."] 3]
set offset [expr $ip3 % 3]
set snat_Subnet [expr $snat_Subnet_base + $offset]
set newip "10.112.$snat_Subnet.$ip4"
# log local0. "Client IP: [IP::client_addr], ip4: $ip4, ip3: $ip3, offset: $offset, newip: $newip"
snat $newip
}
}
It worked for awhile but eventually there were overlaps anyway and session stealing was reported.
The next act steps it up
So then I decided to cycle through all roughly 765 addresses available to me on the LB and maintain a mapping table. Maintaining variable state is tricky on the LB, as is working with arrays, syntax, version differences, … In fact the whole environment is pretty backwards, awkward, poorly documented and unpleasant. So you feel quite a sense of accomplishment when you actually get working code!
rule snat-GUIxt {
# see https://devcentral.f5.com/questions/snat-selected-source-addresses-on-a-vs# and https://devcentral.f5.com/questions/load-balance-on-source-ip-address# spread things out by taking modulus of 3rd octet# - DrJ 2/22/16
when CLIENT_ACCEPTED {
# DrJ 2/16# use ~ 750 addresses available to us in the SNAT pool# initialization. uncomment after first run##set ::counter 0set clientip [IP::client_addr]# can we find it in our array?set indx [array get ::iparray$clientip]set ip [lindex$indx0]if{$ip == ""}{
# add new IP to arrayincr ::counter# IPs = # IPs per subnet * # subnets = 255 * 3set IPs 765set serial [expr$::counter%$IPs]set subnetOffset [expr$serial / 255]set ip4 [expr$serial%255]
log local0. "Matched blank ip. clientip: $clientip, counter: $::counter, serial: $serial, ip4: $ip4 , subnetOffset: $subnetOffset"set ::iparray($clientip)$ip4set ::subnetarray($clientip)$subnetOffset}else{
# already seen IPset ip4 [lindex$indx1]set sindx [array get ::subnetarray$clientip]set subnetOffset [lindex$sindx1]# log local0. "Matched seen ip. counter: $::counter, ip4: $ip4 , subnetOffset: $subnetOffset"}set thrdOctet [expr141 + $subnetOffset]set snat_Subnet "10.112.$thrdOctet"set newip "$snat_Subnet.$ip4"# log local0. "Client IP: [IP::client_addr], indx: $indx, ip4: $ip4, counter, $::counter, ip3: $thrdOctet, newip: $newip"
snat $newip# one-time re-set when updating the code...# Re-set procedure: uncomment, run, commnt out, run again... Plus set ::counter at the top#unset ::iparray#unset ::subnetarray}}
rule snat-GUIxt {
# see https://devcentral.f5.com/questions/snat-selected-source-addresses-on-a-vs
# and https://devcentral.f5.com/questions/load-balance-on-source-ip-address
# spread things out by taking modulus of 3rd octet
# - DrJ 2/22/16
when CLIENT_ACCEPTED {
# DrJ 2/16
# use ~ 750 addresses available to us in the SNAT pool
# initialization. uncomment after first run
##set ::counter 0
set clientip [IP::client_addr]
# can we find it in our array?
set indx [array get ::iparray $clientip]
set ip [lindex $indx 0]
if {$ip == ""} {
# add new IP to array
incr ::counter
# IPs = # IPs per subnet * # subnets = 255 * 3
set IPs 765
set serial [expr $::counter % $IPs]
set subnetOffset [expr $serial / 255]
set ip4 [expr $serial % 255 ]
log local0. "Matched blank ip. clientip: $clientip, counter: $::counter, serial: $serial, ip4: $ip4 , subnetOffset: $subnetOffset"
set ::iparray($clientip) $ip4
set ::subnetarray($clientip) $subnetOffset
} else {
# already seen IP
set ip4 [lindex $indx 1]
set sindx [array get ::subnetarray $clientip]
set subnetOffset [lindex $sindx 1]
# log local0. "Matched seen ip. counter: $::counter, ip4: $ip4 , subnetOffset: $subnetOffset"
}
set thrdOctet [expr 141 + $subnetOffset]
set snat_Subnet "10.112.$thrdOctet"
set newip "$snat_Subnet.$ip4"
# log local0. "Client IP: [IP::client_addr], indx: $indx, ip4: $ip4, counter, $::counter, ip3: $thrdOctet, newip: $newip"
snat $newip
# one-time re-set when updating the code...
# Re-set procedure: uncomment, run, commnt out, run again... Plus set ::counter at the top
#unset ::iparray
#unset ::subnetarray
}
}
Criticism of this approach
Even though there are far fewer users than my 765 addresses, they get their addresses dynamically from many different subnets. So soon the iRule will have encountered 765 unique addresses and be forced to re-use its IPs from the beginning. At that point session stealing is likely to occur all over again! I’ve just delayed the onset.
What I would really need to do is to look for the opportunity to clear out the global arrays and the global counter when it is near its maximum value and the time is favorable, like 1 AM Sunday. But this environment makes such things so hard to program…
A word about the snat pool
I used tmsh to create a snat pool. It looks like this:
Conclusion
A couple real-world iRules were presented, one significantly more sophisticated than the other. They show how awkward the language is. But it is also powerful and allows to execute some otherwise out-there ideas.
Intro
We got audited. There’s always something they catch, right? But I actually appreciate the thoroughness of this audit, and I used its findings to learn a little about one of those mystery areas that never seemed to matter until now: ciphers. Now it matters because cipher weakness was the finding!
I had an older piece of Nortel gear which was running SSL. The auditors found that it allows anonymous authentication ciphers. Have you ever heard of such a thing? I hadn’t either! I am far from an expert in this area, but I will attempt an explanation of the implication of this weakness which, by the way, was scored as a “high severity” – the highest on their scale in fact!
Why Anonymous Authentication is a Severe Matter
The briefly stated reason in the finding is that it allows for a Man In the Middle (MITM) attack. I’ve given it some thought and I haven’t figured out what the core issue is. The correct behaviour is for a client to authenticate a server in an SSL session, usually using RSA. If no authentication occurs, a MITM SSL server could be inserted in between client and server, or so they say.
Reproducing the Problem
OK, so we don’t understand the issue, but we do know enough to reproduce their results. That is helpful so we’ll know when we’ve resolved it without going back to the auditors. Our tool of choice is openssl. In theory, you can list the available ciphers in openssl thus:
openssl ciphers -v
And you’ll probably end up with an output looking like this, without the header which I’ve added for convenience:
I’m not going to explain all those headers because, umm, I don’t know myself. Perhaps in a later or updated posting. The point I want to make here is that as complete as this listing appears, it’s really incomplete. openssl actually supports additional ciphers as well, as I learned by combining information from the audit, plus Nortel’s documentation. In particular Nortel mentions additional ciphers such as these:
I singled these out because the “NONE” means anonymous authentication – the subject of the audit finding! Note that these ciphers were not present in the openssl listing. So now I know Nortel potentially supports anonymous (also called NULL) authentication. There remains the question of whether my specific implementation supports it. Of course the audit says it does, but I want to have sufficient expertise to verify for myself. So, try this:
---
no peer certificate available
---
No client certificate CA names sent
---
SSL handshake has read 411 bytes and written 239 bytes
---
New, TLSv1/SSLv3, Cipher is ADH-DES-CBC3-SHA
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : ADH-DES-CBC3-SHA
Session-ID: 30F1375839B8CFB508CDEFC9FBE4A5BF2D5CE240038DFF8CC514607789CCEDD5
Session-ID-ctx:
Master-Key: B2374E609874D1015DC55BEAA0289310445BAFF65956908A497E5C51DF1301D68CC47AB395DDFEB9A1C77B637A4D306F
Key-Arg : None
Krb5 Principal: None
Start Time: 1317132292
Timeout : 300 (sec)
Verify return code: 0 (ok)
---
---
no peer certificate available
---
No client certificate CA names sent
---
SSL handshake has read 411 bytes and written 239 bytes
---
New, TLSv1/SSLv3, Cipher is ADH-DES-CBC3-SHA
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : ADH-DES-CBC3-SHA
Session-ID: 30F1375839B8CFB508CDEFC9FBE4A5BF2D5CE240038DFF8CC514607789CCEDD5
Session-ID-ctx:
Master-Key: B2374E609874D1015DC55BEAA0289310445BAFF65956908A497E5C51DF1301D68CC47AB395DDFEB9A1C77B637A4D306F
Key-Arg : None
Krb5 Principal: None
Start Time: 1317132292
Timeout : 300 (sec)
Verify return code: 0 (ok)
---
You see that it listed the Cipher as the one I requested, ADH-DES-CBC3-SHA. Further note that no certificate names are sent. Normally they are. To see if my method is correct, let’s try one of Google’s secure servers. Certainly Google will not permit NULL authentication if it’s a bad practice:
Google does not permit this cipher! As a control, let’s use openssl without specifying a specific cipher against both servers. First, the Nortel server:
openssl s_client -connect IP_of_Nortel_server:443
produces some long output, which spits out the sever certificates, followed by this:
New, TLSv1/SSLv3, Cipher is DHE-RSA-AES256-SHA
Server public key is 2048 bit
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : DHE-RSA-AES256-SHA
Session-ID: 6D1A4383F3DBF4C14007220715ECCFB83D91C524624ACE641843880291200AE2
Session-ID-ctx:
Master-Key: BE3FB61B169F497A922A9A172D36A4BB15C26074021D7F22D125875980070E157EDA3100572F927B427B03BF81543E1A
Key-Arg : None
Krb5 Principal: None
Start Time: 1317132982
Timeout : 300 (sec)
Verify return code: 0 (ok)
New, TLSv1/SSLv3, Cipher is DHE-RSA-AES256-SHA
Server public key is 2048 bit
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : DHE-RSA-AES256-SHA
Session-ID: 6D1A4383F3DBF4C14007220715ECCFB83D91C524624ACE641843880291200AE2
Session-ID-ctx:
Master-Key: BE3FB61B169F497A922A9A172D36A4BB15C26074021D7F22D125875980070E157EDA3100572F927B427B03BF81543E1A
Key-Arg : None
Krb5 Principal: None
Start Time: 1317132982
Timeout : 300 (sec)
Verify return code: 0 (ok)
So you see client and server agreed to use the cipher DHE-RSA-AES256-SHA, which from our table uses RSA authentication. And hitting Google again without the ciphers argument we get this:
New, TLSv1/SSLv3, Cipher is RC4-SHA
Server public key is 1024 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : RC4-SHA
Session-ID: 236FDF47DA752E768E7EE32DA10103F1CAD513E9634F075BE8773090A2E7A995
Session-ID-ctx:
Master-Key: 39212DE0E3A98943C441287227CB1425AE11CCA277EFF6F8AF83DA267AB256B5A8D94A6573DFD54FB1C9BF82EA302494
Key-Arg : None
Krb5 Principal: None
Start Time: 1317133483
Timeout : 300 (sec)
Verify return code: 0 (ok)
---
New, TLSv1/SSLv3, Cipher is RC4-SHA
Server public key is 1024 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : RC4-SHA
Session-ID: 236FDF47DA752E768E7EE32DA10103F1CAD513E9634F075BE8773090A2E7A995
Session-ID-ctx:
Master-Key: 39212DE0E3A98943C441287227CB1425AE11CCA277EFF6F8AF83DA267AB256B5A8D94A6573DFD54FB1C9BF82EA302494
Key-Arg : None
Krb5 Principal: None
Start Time: 1317133483
Timeout : 300 (sec)
Verify return code: 0 (ok)
---
So in this case it is successful, though it has chosen a different cipher from Nortel, namely RC4-SHA. But we can look it up and see that it’s a cipher which uses RSA authentication. Cool.
So we’ve “proven” all our assertions thus far. Now how do we fix Nortel? The Nortel GUI lists the ciphers as
ALL@STRENGTH
Pardon me? It turns out there are cipher groupings denoted by aliases, and you can combine the aliases into a cipher list.
ALL – means all cipher suites
EXPORT – includes cipher suites using 40 or 56 bit encryption
aNULL – cipher suites that do not offer authentication
eNULL – cipher suites that have no encryption whatsoever (disabled by default in Nortel)
STRENGTH – is at the end of the list and sorts the list in order of encryption algorithm key length
List operators are:
! – permanently deletes the cipher from the list.
+ – moves the cipher to the end of the list
: – separator of cipher strings
aNULL is a subset of ALL, and that’s what’s killing us. Putting all this together, the cipher I tried in place of ALL@STRENGTH is:
ALL:!EXPORT:!aNULL@STRENGTH
In this way I prevent NULL authentication and remove the weaker export ciphers. As soon as I applied this cipher list, I tested it. Yup – works. I can no longer hit it by using anonymous authentication:
and using cipher eNULL produces the same error. To make sure I’m sending a cipher which openssl understands, I tried a nonsense cipher as a control – one that I know does not exist:
error setting cipher list
2482:error:1410D0B9:SSL routines:SSL_CTX_set_cipher_list:no cipher match:ssl_lib.c:1188:
providing assurance that aNULL and eNULL are cipher families understood and supported by openssl, and that I have done the hardening correctly!
Now you can probably count the number of people still using Nortel gear with your two hands! But this discussion, obviously, has wider applicability. In Apache/mod_ssl there is an SSLCipherSuite line where you specify a cipher list. The auditor’s recommendation is more detailed than what I tried. They suggest the list ALL:!aNULL:!ADH:!eNULL:!LOW:!EXP:RC4+RSA:+HIGH:+MEDIUM
October 2014 Update
Well, now we’ve encountered the SSLv3 vulnerability POODLE, which compels us to forcibly eliminate use of SSLv3 on all servers and clients. Let’s say we updated our clients to require use of TLS. How do we gain confidence the update worked? Set one of our servers to not use TLS! Here’s how I did that on a BigIP server:
DEFAULT:!TLSv1:@STRENGTH
DEFAULT:!TLSv1:@STRENGTH
I ran a quick test using openssl s_client -connect server:443 as above, and got what I was looking for:
...
SSL handshake has read 3038 bytes and written 479 bytes
---
New, TLSv1/SSLv3, Cipher is AES256-SHA
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : SSLv3
Cipher : AES256-SHA
...
...
SSL handshake has read 3038 bytes and written 479 bytes
---
New, TLSv1/SSLv3, Cipher is AES256-SHA
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : SSLv3
Cipher : AES256-SHA
...
Note the protocol says SSLv3 and not TLS.
Turning off SSLv3 to deal with POODLE
So that is normally exactly the opposite of what you want to do to turn off SSLv3 – that was just to run a control test. Here’s what to do to turn off SSLv3 on a BigIP:
DEFAULT:!RC4:!SSLv3:@STRENGTH
DEFAULT:!RC4:!SSLv3:@STRENGTH
OK, yes, RC4 is a discredited cipher so disable that as well. Most clients (but not all) will be able to work with a server which is set like this.
Apache and POODLE prevention
Well, I went to the Qualys site and found I was not exactly eating my own dogfood! My own server was considered vulnerable to POODLE, supported weak protocols, etc and only scored a “C.” Determined to incorporate more modern approaches to my apache server settings and stealing from others, I improved things dramatically by throwing these additional configuration lines into my apache configuration:
(the following apache configuration lines are deprecated – see further down below)
...
# lock things down to get a better score from Qualys - DrJ 12/17/14
# 4 possible values: All, SSLv2, SSLv3, TLSv1. Allow TLS only:
SSLProtocol all -SSLv2 -SSLv3
SSLCipherSuite ALL:!aNULL:!eNULL:!SSLv2:!LOW:!EXP:!RC4:!MD5:@STRENGTH
...
...
# lock things down to get a better score from Qualys - DrJ 12/17/14
# 4 possible values: All, SSLv2, SSLv3, TLSv1. Allow TLS only:
SSLProtocol all -SSLv2 -SSLv3
SSLCipherSuite ALL:!aNULL:!eNULL:!SSLv2:!LOW:!EXP:!RC4:!MD5:@STRENGTH
...
The results after strengthening apache configuration
I now get an “A-” and am not supporting any weak ciphers! Yeah! It’s because those configuration lines mean that I explicitly don’t permit SSLv2/v3 or the weak RC4 cipher. I need to study to determine if I should support TLSv1.2 and forward secrecy to go to the best possible score – an “A.” (Months later) Well now I do get an A and I’m not exactly sure why the improved score.
BREACH prevention
After all the above measures the Digicert certificate inspector I am evaluating says my drjohnstechtalk site is vulnerable to the Breach attack. From my reading the only practical solution, at least for my case, is to upgrade from apache 2.2 to apache 2.4. Hence the Herculean efforts to compile apache 2.4 as detailed in this blog post. My preliminary finding is that without changing the SSL configuration at all apache 2.4 does not show a vulnerability to BREACH. But upon digging further, it has to do with the absence of the use of compression in apache 2.4 and I’m not yet sure why it isn’t being used!
2016 Update for CVE-2016-2107
I was going to check to see if my current score at SSLLabs is an A-, and what I can do to boost it to an A. Well, I got an F! I guess the lesson here is to conduct periodic tests. Things change!
I saw from descriptions elsewhere that my version of openssl, openssl-1.0.1e-30.el6.11, was likely out-of-date. So I looked at my version of openssl on my CentOS server:
$ sudo rpm ‐qa|grep openssl
and updated it:
$ sudo yum update openssl‐1.0.1e‐30.el6.11
Now (11/11/16) my version is openssl-1.0.1e-48.el6_8.3.
Would this upgrade suffice without any further action?
I was pretty sure that my apache dynamically links to the openssl libraries by virtue of the lack of their appearance as listed compiled-in modules:
$ /usr/local/apache24/bin/httpd ‐l
Compiled in modules:
core.c
mod_so.c
http_core.c
prefork.c
Compiled in modules:
core.c
mod_so.c
http_core.c
prefork.c
Simply installing these new openssl libraries did not do the trick immediately. So the next step was to restart apache. Believe it or not, that did it!
Going back to the full ssllabs test, I currently get a solid A. Yeah!
In the spirit of let’s learn something here beyond what the immediate problem requires, I learned then that indeed the openssl libraries were dynamically linked to my apache version. Moreover, I learned that dynamic linking, despite the name, still has a static aspect. The shared object library must be read in at process creation time and perhaps only occasionally re-read afterwards. But it is not read with every single invocation, which I suppose makes sense form a performance point-of-view.
2016 apache 2.4 SSL config section
For the record…
...
SSLProtocol all -SSLv2 -SSLv3
# it used to be this simple
#SSLCipherSuite ALL:!aNULL:!eNULL:!SSLv2:!LOW:!EXP:!RC4:!MD5:@STRENGTH
# Now it isn't - DrJ 6/2/15. Based on SSL Labs https://weakdh.org/sysadmin.html - DrJ 6/2/15
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA
SSLHonorCipherOrder on
...
...
SSLProtocol all -SSLv2 -SSLv3
# it used to be this simple
#SSLCipherSuite ALL:!aNULL:!eNULL:!SSLv2:!LOW:!EXP:!RC4:!MD5:@STRENGTH
# Now it isn't - DrJ 6/2/15. Based on SSL Labs https://weakdh.org/sysadmin.html - DrJ 6/2/15
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA
SSLHonorCipherOrder on
...
How to see what ciphers your browser supports
Your best bet is the SSLLABS.com web site. Go to Test my Browser.
University of Hannover offers this site. Just go this page. But lately I noticed that it does not list ciphers using CBC whereas the SSLlabs site does. So SSLlabs provides a more accurate answer.
2017 update for PCI compliance
Of course this article is ancient and I hesitate to further complicate it, but I also don’t want to tear it down. Anyway, for PCI compliance you’ll soon need to drop 3DES ciphers (3DES is pronounced “triple-DES” if you ever need to read it aloud). I have this implemented on F5 BigIP devices. I have set the ciphers to:
DEFAULT:!DHE:!3DES:+RSA
DEFAULT:!DHE:!3DES:+RSA
and this did the trick. Here’s how to see what effect that has from the BigIP command line:
2018 update and comment about PCI compliance
I tried to give the owners of e1st.smapply.org a hard time for supporting such a limited set of ciphersuites – essentially only the latest thing (which you can see yourself by running it through sslabs.com): TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384. If I run this through SSL interception on a Symantec proxy with an older image, 6.5.10.4 from June, 2017, that ciphersuite isn’t present! I had to upgrade to 6.5.10.7 from October 2017, then it was fine. But getting back to the rationale, they told me they have future-proofed their site for the new requirements of PCI and they would not budge and support other ciphersuites (forcing me to upgrade).
Another site in that same situation is https://shop-us.bestunion.com/. I don’t know if it’s a misconception on the part of the site administrators or if they’re onto something. I’ll know more when I update my own PCI site to meet the latest requirements.
2020 Update
In this year they are trying to phase out TLS v 1.0 and v 1.1 in favor of TLS v 1.2 or v 1.3. Now my web site’s grade is capped at a B because it still supports those older protocols.
A great site for testing the strength of any web site’s SSL setup, vulnerability to POODLE, etc is this Qualys SSL Labs testing site. No obnoxious ads either. A much more basic one is https://www.websiteplanet.com/webtools/ssl-checker/ SSLlabs is much more complete, but it only works on web sites running on the default port 443. websiteplanet is more about whether your certificate is installed properly and such.
Need to know what ciphers your browser supports? Qualys SSL Labs again to the rescue: https://www.ssllabs.com/ssltest/viewMyClient.html shows you all your browser’s supported ciphers. However, the results may not be reliable if you are using a proxy.
An excellent article explaining in technical terms what the problem with SSLv3 actually is is posted by, who else, Paul Ducklin the Sophos NakedSecurity blogger.
Want a readily understandable explanation of what CBC (Cipher Block Chaining) means? It isn’t too hard to understand. This is an excellent article from Sophos’ Paul Ducklin. It also explains the Sweet32 attack.
A fast dedicated test for CVE-2016-2107, the oracle padding vulnerability: https://filippo.io/CVE-2016-2107/. SSLlabs test is more thorough – it checks for everything – but much slower.
If you want to see how your browser deals with different certificate issues (expired, bad chained CERT) as well different ciphers, this has a test case for all of that. This is very useful for testing SSL Interception product behavior. https://badssl.com/
Aimed at F5 admins, but a really good review for anyone about sipher suites, SSL vs TLS and all that is this F5 document. I recommend it for anyone getting started.
This site will never run SSL! This can be useful when you are trying to login to a hotel’s guest WiFi, which may not be capable of intercepting SSL traffic to force you to heir sign-on page: http://neverssl.com/.
Want to test if a web site requires client certificates, e.g., for authentication? This post has some suggestions.
Conclusion
We now have some idea of what those kooky cipher strings actually mean and our eyes don’t gloss over when we encounter them! Plus, we have made our Nortel gear more secure by deploying a cipher string which disallows anonymous authentication.
It seems SSL exploits have been discovered at reliable pace since this article was first published. It’s best to check your servers running SSL at least twice a year or better every quarter using the SSLlabs tool.