Intro
I recently visited a foreign country where I was unable to watch an Amazon Prime Original show because of my location. Annoyed, I decided then and there to investigate OpenVPN. I am an ideal candidate – I already run my own Linux server in the Amazon cloud, and I know Linux and networking, so I’ve pretty much got all the ingredients already present. The software is free and I will incur no additional cost if I ever do get it working since I already pay for my server which is primarily used as a low-demand web server. Little did I know what I was getting myself into!
The details
I seem to have made every mistake in the book, but I have a strong grasp of the networking involved so I was confident in my general approach. Seeing how configurable the software is I decided to ramp up my efforts incrementally, introducing more and more features until I arrived to the minimum desired (still not there, by the way, but getting close!).
The package on various OSes
Conveniently, openvpn is an installable package on SLES and Centos. On SLES a
zypper install openvpn suffices whereas in CentOS a yum install openvpn does the trick. In Debian Linux such as Raspbian, an apt-get install openvpn works to install it.
Then look at the examples at the bottom of the man page for openvpn. I picked two servers where I have root and tried to replicate their most basic example. I think this is really important to crawl before you run. To paraphrase it:
Example 1: A simple tunnel without security
On may:
openvpn --remote june.kg --dev tun1 --ifconfig 10.4.0.1 10.4.0.2 --verb 9
On june:
openvpn --remote may.kg --dev tun1 --ifconfig 10.4.0.2 10.4.0.1 --verb 9
Now verify the tunnel is working by pinging across the tunnel.
On may:
ping 10.4.0.2
On june:
ping 10.4.0.1 |
Example 1: A simple tunnel without security
On may:
openvpn --remote june.kg --dev tun1 --ifconfig 10.4.0.1 10.4.0.2 --verb 9
On june:
openvpn --remote may.kg --dev tun1 --ifconfig 10.4.0.2 10.4.0.1 --verb 9
Now verify the tunnel is working by pinging across the tunnel.
On may:
ping 10.4.0.2
On june:
ping 10.4.0.1
june.kg and may.kg are the IP addresses or FQDNs of the june and may server, respectively.
If you installed from a package you probably don’t need these preliminary steps they mention:
mknod /dev/net/tun c 10 200
modprobe tun |
mknod /dev/net/tun c 10 200
modprobe tun
I checked it by a directory listing of /dev/net/tun:
crw-rw-rw- 1 root root 10, 200 Jan 6 08:35 /dev/net/tun |
crw-rw-rw- 1 root root 10, 200 Jan 6 08:35 /dev/net/tun
and running modprobe tun for good measure.
And, yes, their basic example worked. How? The command creates a virtual adapter, tun0, specially designed for tunnels, which records the private tunnel IP of the server itself as well as the IP of the tunnel endpoint on the other server.
It’s so cool. What’s not well explained is that you ought to choose completely private IPs for building your tunnels that don’t interfere with your other private IPs. You’ll see I eventually settled on 172.27.28.29 – I’ve never seen that range used anywhere.
You quit running the openvpn command and the tun0 adapter is destroyed. It’s very tidy.
A small word about routing for now
What about routing. How does that work? What you probably didn’t appreciate is that in this simple example although you can ping each other using the tunnel IP, you really can’t do any more than that unless you start to introduce additional routes. So as is it’s a long way from where we need to be. More on routing later. Check your route table with a netstat -rn
Finding the right example is surprisingly hard
For such a popular program you’d think examples of what I’m trying to do – change the effective IP of my laptop – would abound and implementation would be a piece of cake. But alas, nothing could be further from the truth. I’ve yet to see a complete example so I cobbled together things from various places.
You gotta understand that for a lot of people with enough tech-savvy to write up what they did, I guess they were just tickled pink to be able to tunnel through their home router and access their home networks. That’s fine and all, but it’s not all that pertinent to my usage, where the routing considerations are pretty different.
Anywho, this article is really helpful, though not sufficient by itself:
https://openvpn.net/index.php/open-source/documentation/miscellaneous/78-static-key-mini-howto.html
That describes a single server/client setup with simple security.
Server config
After a lot of debugging and incremental steps, I’m currently using this file with filepath /etc/openvpn/server.conf on my Amazon AWS server:
# -DrJ 1/5/16
# simple one server/one client setup...
# https://openvpn.net/index.php/open-source/documentation/miscellaneous/78-static-key-mini-howto.html
# static.key generated with openvpn --genkey --secret static.key
# iptables NAT discussion: http://www.karlrupp.net/en/computer/nat_tutorial
# using (simple udp test worked): iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
# list: iptables -t nat -L -v
# dig on RasPi: from dnsutils
dev tun
# 1194 is default, but...
port 2096
ifconfig 172.27.28.29 172.27.28.30
secret static.key
#use compresison
comp-lzo
# resist failures
keepalive 10 60
ping-timer-rem
persist-tun
persist-key
# run as daemon
user nobody
group nobody
daemon
proto tcp-server |
# -DrJ 1/5/16
# simple one server/one client setup...
# https://openvpn.net/index.php/open-source/documentation/miscellaneous/78-static-key-mini-howto.html
# static.key generated with openvpn --genkey --secret static.key
# iptables NAT discussion: http://www.karlrupp.net/en/computer/nat_tutorial
# using (simple udp test worked): iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
# list: iptables -t nat -L -v
# dig on RasPi: from dnsutils
dev tun
# 1194 is default, but...
port 2096
ifconfig 172.27.28.29 172.27.28.30
secret static.key
#use compresison
comp-lzo
# resist failures
keepalive 10 60
ping-timer-rem
persist-tun
persist-key
# run as daemon
user nobody
group nobody
daemon
proto tcp-server
An experimental client config file currently looks like this:
# for understanding what openvpn can do...
# simple single server/client setup from https://openvpn.net/index.php/open-source/documentation/miscellaneous/78-static-ke
y-mini-howto.html
# - DrJ 1/6/16
remote drjohnstechtalk.com
# 1994 is default but I'll use this one...
port 2096
dev tun
ifconfig 172.27.28.30 172.27.28.29
secret static.key
# resist failures
keepalive 10 60
ping-timer-rem
persist-tun
persist-key
#use compresison
comp-lzo
# for testing
proto tcp-client
# a test host route
#route 172.16.0.23
# a test network route which includes endpoint
route 172.16.0.0 255.240.0.0
# stands for broad, Internet route which may overlap our route to the openvpn server: doesn't work by itself!
route drjohnstechtalk.com 255.255.255.255 net_gateway
route 50.17.188.0 255.255.255.0 |
# for understanding what openvpn can do...
# simple single server/client setup from https://openvpn.net/index.php/open-source/documentation/miscellaneous/78-static-ke
y-mini-howto.html
# - DrJ 1/6/16
remote drjohnstechtalk.com
# 1994 is default but I'll use this one...
port 2096
dev tun
ifconfig 172.27.28.30 172.27.28.29
secret static.key
# resist failures
keepalive 10 60
ping-timer-rem
persist-tun
persist-key
#use compresison
comp-lzo
# for testing
proto tcp-client
# a test host route
#route 172.16.0.23
# a test network route which includes endpoint
route 172.16.0.0 255.240.0.0
# stands for broad, Internet route which may overlap our route to the openvpn server: doesn't work by itself!
route drjohnstechtalk.com 255.255.255.255 net_gateway
route 50.17.188.0 255.255.255.0
Works through proxy
Amazingly, I can confirm openvpn works through a standard http proxy. This is both cool and a little scary. To the above config file I added something like this:
# use proxy which requires basic authentication
http-proxy proxy-1.johnstechtalk.com 8080 authfile |
# use proxy which requires basic authentication
http-proxy proxy-1.johnstechtalk.com 8080 authfile
where authfile is in the same directory as client.conf (/etc/eopnvpn) and has the proxy username and password on two separate lines.
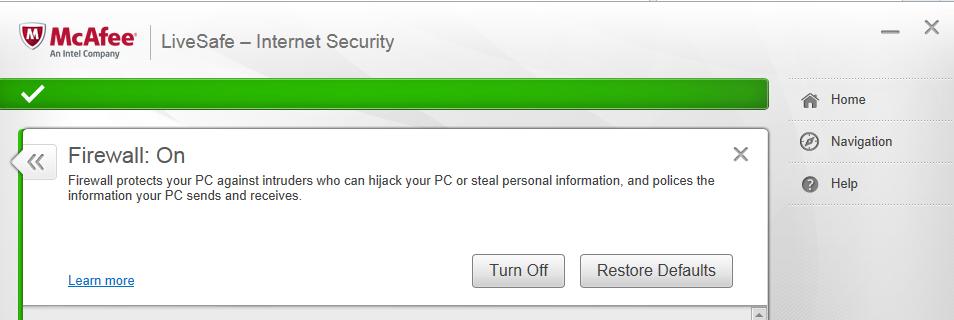
You have to run your server in TCP mode in order to access it from a client that’s behind an http proxy however, hence the proto tcp-server in the config line of the server and the proto tcp-client line in the client config. I’ll experiment with that to see if that’s costing performance.
A little more on routing
Why the circumspect routes? I’m deathly afraid of locking myself out of these servers by implementing the wrong routes! And I learned a lot bootstrapping my way to broader routes. The thing is, I noticed my AWS server uses this private IP address for its DNS server: 172.16.0.23 (cat /etc/resolv.conf, for example). So I realized that I could introduce a host route to that IP on the openvpn client to begin the arduous process of building up and testing real routing. How to test? Simple. With commands like
> dig ns johnstechtalk.com @172.16.0.23
on the client.
Dig is a useful networking tool. I describe installing it on Windows systems in this post.
Point of concern over performance
Even before expanding the routes I am concerned about TCP performance. I noticed that when I add the +tcp option to dig to force the query to use TCP I get a big performance penalty. a regular query that takes 60 msec to the AWS DNS server from my PC takes anywhere from 200 – 400 msec over TCP! Now there are a bunch more packets a back-and-forth, but all that aside and still there is a disconcerting performance hit of 100 msec or so. By contrast the enterprise-class VPN provided by Juniper suffers from no such TCP performance penalty – I know because I tested dig over a Juniper VPN using the JunOS Pulse client.
Up our game, try to run as a full server w/ DHCP and everything
I’ll show the config file below. Let me just mention that my first attempt didn’t work because I continued to use a shared secret (the secret declaration), but that is incompatible with a new statement I introduced on the server:
server 172.27.28.32 255.255.255.224 |
server 172.27.28.32 255.255.255.224
So I gotta bite the bullet and get my PKI infrastructure up and running. In the old days they bundled easy-rsa with openvpn. Now you have to install it separately. I was able to do a yum install easy-rsa on my CentOS instance.
Hey, easy-rsa is pretty cool – I might be able to use that for other things. I always wanted to know how to create my own CA! The instructions in the Howto are so complete that there’s really no need to go over that here. HowTo link.
I copied my /usr/share/easy-rsa/2.0/* files to /etc/openvpn/rsa and did all the pki-buildingwork there. But I don’t want to go crazy with encyrption so I downgraded diffie-hellman from 2048 to 1024 bits:
$ openssl dhparam -out dh1024.pem 1024
Full Monty – doing a full VPN
Enough warm-up. I tried full VPN and for some reason hit the right configuration on the first try.
Here’s my server.conf file on my Amazon AWS server.
# -DrJ 1/13/16
# multi-client server from https://openvpn.net/index.php/open-source/documentation/howto.html#examples
# static.key generated with openvpn --genkey --secret static.key
# iptables NAT discussion: http://www.karlrupp.net/en/computer/nat_tutorial
# using (simple udp test worked): iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
# list: iptables -t nat -L -v
port 1194
proto udp
dev tun
ca rsa/keys/ca.crt
cert rsa/keys/server.crt
key rsa/keys/server.key # This file should be kept secret
dh rsa/keys/dh1024.pem
# pool of addresses for clients and server. server gets 172.27.28.33
server 172.27.28.32 255.255.255.224
ifconfig-pool-persist ipp.txt
# very experimental
push "redirect-gateway def1 bypass-dhcp"
# just use closest Google DNS server
push "dhcp-option DNS 8.8.8.8"
# resist failures
keepalive 10 60
ping-timer-rem
# use compression
comp-lzo
# only allow two clients max for now
max-clients 2
user nobody
group nobody
persist-key
persist-tun
status openvpn-status.log
# verbosity level. 0 - all but fatal errors, 9 - extremely verbose
verb 3 |
# -DrJ 1/13/16
# multi-client server from https://openvpn.net/index.php/open-source/documentation/howto.html#examples
# static.key generated with openvpn --genkey --secret static.key
# iptables NAT discussion: http://www.karlrupp.net/en/computer/nat_tutorial
# using (simple udp test worked): iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
# list: iptables -t nat -L -v
port 1194
proto udp
dev tun
ca rsa/keys/ca.crt
cert rsa/keys/server.crt
key rsa/keys/server.key # This file should be kept secret
dh rsa/keys/dh1024.pem
# pool of addresses for clients and server. server gets 172.27.28.33
server 172.27.28.32 255.255.255.224
ifconfig-pool-persist ipp.txt
# very experimental
push "redirect-gateway def1 bypass-dhcp"
# just use closest Google DNS server
push "dhcp-option DNS 8.8.8.8"
# resist failures
keepalive 10 60
ping-timer-rem
# use compression
comp-lzo
# only allow two clients max for now
max-clients 2
user nobody
group nobody
persist-key
persist-tun
status openvpn-status.log
# verbosity level. 0 - all but fatal errors, 9 - extremely verbose
verb 3
And here’s my Windows 10 client file.
# from https://openvpn.net/index.php/open-source/documentation/howto.html#examples
# - DrJ 1/17/16
client
dev tun
proto udp
remote drjohnstechtalk.com 1194
nobind
# resist failures
keepalive 10 60
ping-timer-rem
persist-tun
persist-key
#use compresison
comp-lzo
# SSL/TLS parmas
ca ca.crt
cert client1.crt
key client1.key
# stands for broad, Internet route which may overlap our route to the openvpn server: doesn't work by itself!
route drjohnstechtalk.com 255.255.255.255 net_gateway
verb 3 |
# from https://openvpn.net/index.php/open-source/documentation/howto.html#examples
# - DrJ 1/17/16
client
dev tun
proto udp
remote drjohnstechtalk.com 1194
nobind
# resist failures
keepalive 10 60
ping-timer-rem
persist-tun
persist-key
#use compresison
comp-lzo
# SSL/TLS parmas
ca ca.crt
cert client1.crt
key client1.key
# stands for broad, Internet route which may overlap our route to the openvpn server: doesn't work by itself!
route drjohnstechtalk.com 255.255.255.255 net_gateway
verb 3
I was a bit concerned the DHCP stuff might not work, but it did, including assigning a Google DNS server at 8.8.8.8.
I generated the client1.crt and client1.key using easy-rsa. These plus ca.crt I copied down to my laptop. For security I then deleted client1.key on my server (so no one else can grab it).
Performance
Performance is amazing. There no longer is the penalty for doing dig over tcp. speedtest.net actually shows better results when I am connected over my VPN! This is a totally unexpected surprise. I guess that’s due to the compression, using UDP and not using overly strong encryption.
Speedtest results
speedtest.net results without VPN, i.e., regular mode: 8.0 mbps download, 1.0 mbps upload. With VPN I got 11.0 mbps download and 1.2 mbps upload.
A platform that didn’t work
You’ll see from my other blogs that I am a Raspberry Pi fan. so naturally I wanted to bring up a VPN client on the Raspberry Pi. I am stuck on this point however because unlike the SLES Linux I tested with, Raspbian brings up a tun interface but then drops the wlan0 IP address so all communication to it is lost. Maybe it would work better wired – I’ll try it and post the results.
Still more about routing
I never understood how the openvpn examples were supposed to work until I had to implement them. Indeed they generally wouldn’t work until you address some routing and NAT issues. There is no magic. I did traces to show my client was trying to communicate with its assigned private IP of 172.27.28.29. Well that’s never going to work. You have to make sure routing is enabled on your server:
On Linux, use the command:
$ echo 1 > /proc/sys/net/ipv4/ip_forward
But that’s not sufficient either. That doesn’t address that the packets from your client have the wrong IP address as far as the outside world is concerned. So you have to NAT (address translate) those packets. I don’t like iptables but this turned out to be easier than expected. As mentioned in my server config file you run:
$ iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
This is the boiled down summary from this helpful article.
Don’t forget that to look at your NAT rules you need a command like this:
$ iptables -t nat -L -v
not simply an iptables -L.
Note that this is a hide NAT – I am not making the openvpn client visible as a server on the Internet. That’s a lot harder with IP addresses being in scarce supply.
Does it work to solve my original problem? Well I’m not in a foreign country to run that test, but I can vouch that I can run Amazon Prime through openvpn. So I expect it will work overseas as well.
It works so well how do I know I’m really running through openvpn?
Many ways. For instance my routing table. From a CMD window:
C:> netstat -rn
IPv4 Route Table
===========================================================================
Active Routes:
Network Destination Netmask Gateway Interface Metric
0.0.0.0 0.0.0.0 192.168.2.1 192.168.2.8 25
0.0.0.0 128.0.0.0 172.27.28.37 172.27.28.38 20
50.17.188.196 255.255.255.255 192.168.2.1 192.168.2.8 25
127.0.0.0 255.0.0.0 On-link 127.0.0.1 306
127.0.0.1 255.255.255.255 On-link 127.0.0.1 306
127.255.255.255 255.255.255.255 On-link 127.0.0.1 306
128.0.0.0 128.0.0.0 172.27.28.37 172.27.28.38 20
169.254.0.0 255.255.0.0 On-link 192.168.2.8 306
169.254.255.255 255.255.255.255 On-link 192.168.2.8 281
172.27.28.33 255.255.255.255 172.27.28.37 172.27.28.38 20
172.27.28.36 255.255.255.252 On-link 172.27.28.38 276
172.27.28.38 255.255.255.255 On-link 172.27.28.38 276
172.27.28.39 255.255.255.255 On-link 172.27.28.38 276
192.168.2.0 255.255.255.0 On-link 192.168.2.8 281
192.168.2.8 255.255.255.255 On-link 192.168.2.8 281
192.168.2.255 255.255.255.255 On-link 192.168.2.8 281
224.0.0.0 240.0.0.0 On-link 127.0.0.1 306
224.0.0.0 240.0.0.0 On-link 192.168.2.8 281
224.0.0.0 240.0.0.0 On-link 172.27.28.38 276
255.255.255.255 255.255.255.255 On-link 127.0.0.1 306
255.255.255.255 255.255.255.255 On-link 192.168.2.8 281
255.255.255.255 255.255.255.255 On-link 172.27.28.38 276 |
IPv4 Route Table
===========================================================================
Active Routes:
Network Destination Netmask Gateway Interface Metric
0.0.0.0 0.0.0.0 192.168.2.1 192.168.2.8 25
0.0.0.0 128.0.0.0 172.27.28.37 172.27.28.38 20
50.17.188.196 255.255.255.255 192.168.2.1 192.168.2.8 25
127.0.0.0 255.0.0.0 On-link 127.0.0.1 306
127.0.0.1 255.255.255.255 On-link 127.0.0.1 306
127.255.255.255 255.255.255.255 On-link 127.0.0.1 306
128.0.0.0 128.0.0.0 172.27.28.37 172.27.28.38 20
169.254.0.0 255.255.0.0 On-link 192.168.2.8 306
169.254.255.255 255.255.255.255 On-link 192.168.2.8 281
172.27.28.33 255.255.255.255 172.27.28.37 172.27.28.38 20
172.27.28.36 255.255.255.252 On-link 172.27.28.38 276
172.27.28.38 255.255.255.255 On-link 172.27.28.38 276
172.27.28.39 255.255.255.255 On-link 172.27.28.38 276
192.168.2.0 255.255.255.0 On-link 192.168.2.8 281
192.168.2.8 255.255.255.255 On-link 192.168.2.8 281
192.168.2.255 255.255.255.255 On-link 192.168.2.8 281
224.0.0.0 240.0.0.0 On-link 127.0.0.1 306
224.0.0.0 240.0.0.0 On-link 192.168.2.8 281
224.0.0.0 240.0.0.0 On-link 172.27.28.38 276
255.255.255.255 255.255.255.255 On-link 127.0.0.1 306
255.255.255.255 255.255.255.255 On-link 192.168.2.8 281
255.255.255.255 255.255.255.255 On-link 172.27.28.38 276
Specifically note the two routes to 0.0.0.0 netmask 128.0.0.0 and 128.0.0.0 netmask 128.0.0.0 via gateway 172.27.28.37. That’s just what this experimental command in my server config file was supposed to do:
push "redirect-gateway def1 bypass-dhcp" |
push "redirect-gateway def1 bypass-dhcp"
namely, create two broad routes to the entire Internet, just slightly more specific than a default route so they take precedence over the default route – I think it’s a clever idea. And of course ipconfig shows my private IP address:
Ethernet adapter Ethernet 2:
Connection-specific DNS Suffix . :
Link-local IPv6 Address . . . . . : fe80::8871:c910:185e:953b%5
IPv4 Address. . . . . . . . . . . : 172.27.28.38
Subnet Mask . . . . . . . . . . . : 255.255.255.252
Default Gateway . . . . . . . . . : |
Ethernet adapter Ethernet 2:
Connection-specific DNS Suffix . :
Link-local IPv6 Address . . . . . : fe80::8871:c910:185e:953b%5
IPv4 Address. . . . . . . . . . . : 172.27.28.38
Subnet Mask . . . . . . . . . . . : 255.255.255.252
Default Gateway . . . . . . . . . :
References and related
No patience to roll your own? Five top commercial VPN offerings are described here: http://www.itworld.com/article/3152904/security/top-5-vpn-services-for-personal-privacy-and-security.html
A lightweight dig installation method for Windows is described here.
My article about iptables.