Intro
I share some Zabbix items I’ve had to create which I find useful.
Low-level discovery to discover IPSEC tunnels on an F5 BigIP
IPSec tunnels are weird insofar as there is one IKE SA but potentially lots of SAs – two for each traffic selector. So if your traffic selector is called proxy-01, some OIDs you’ll see in your SNMP walk will be like …proxy-01.58769, …proxy-01.58770. So to review, do an snmpwalk on the F5 itself. That command is something like
snmpwalk -v3 -l authPriv -u proxyUser -a SHA -A shaAUTHpwd -x AES -X AESpwd -c public 127.0.0.1 SNMPv2-SMI::enterprises >/tmp/snmpwalk-ent
Now…how to translate this LLD? In my case I have a template since there are several F5s which need this. The template already has discovery rules for Pool discovery, Virtual server discovery, etc. So first thing we do is add a Tunnel discovery rule.
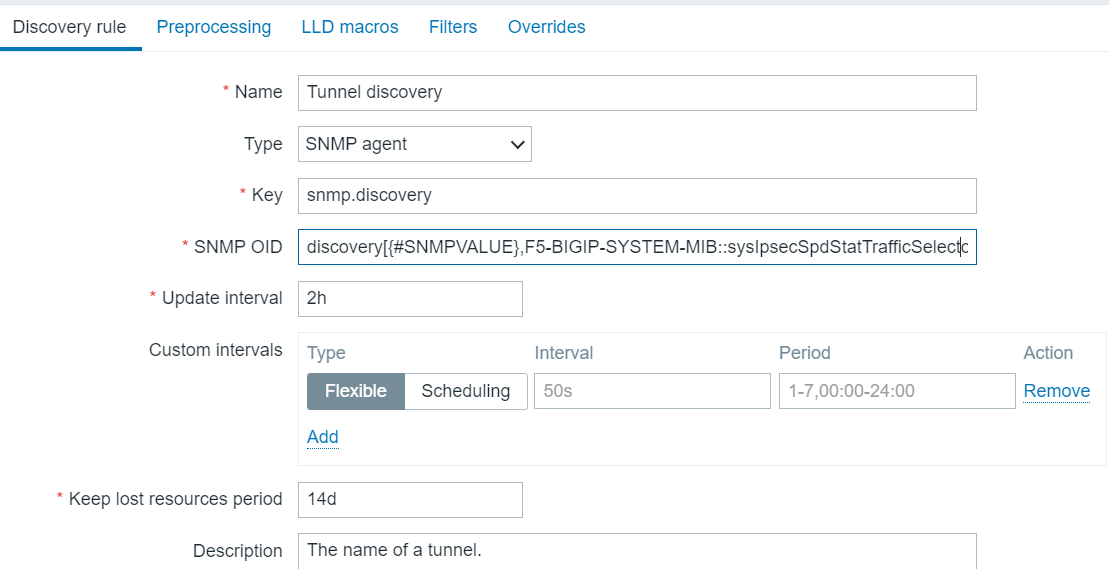
Tunnel Discovery Rule
The SNMP OID is clipped at the end. In full it is:
Initially I tried something else, but that did not go so well.
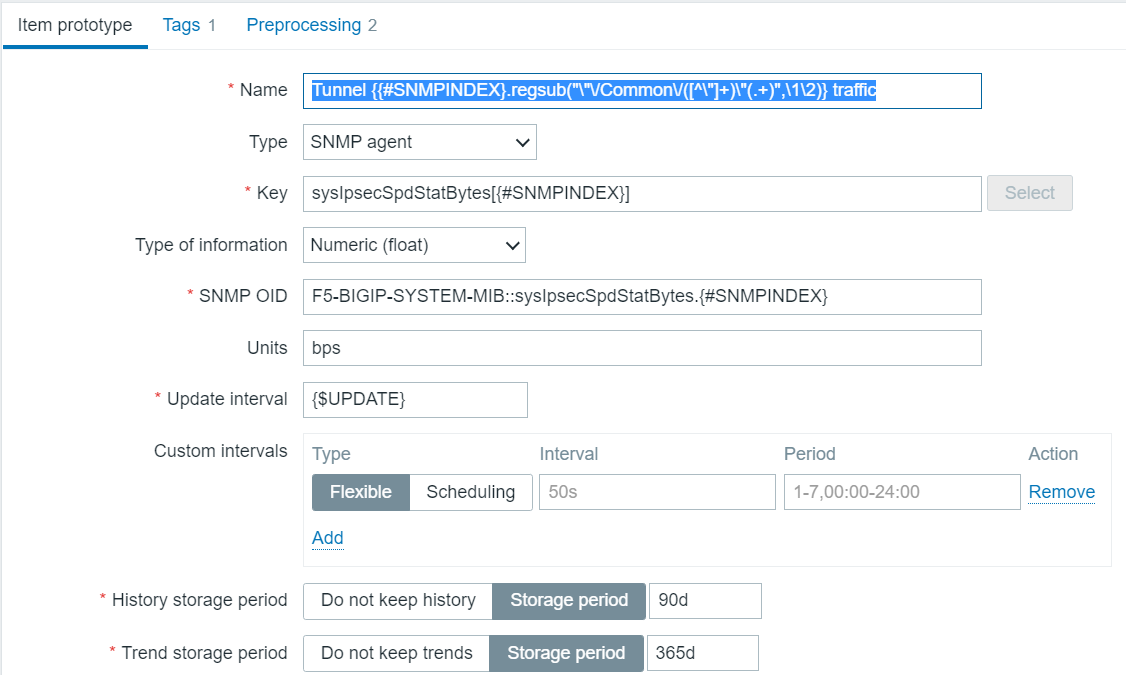
Now we want to know the tunnel status (up or down) and the amount of traffic over the tunnel. We create two item prototypes to get those.
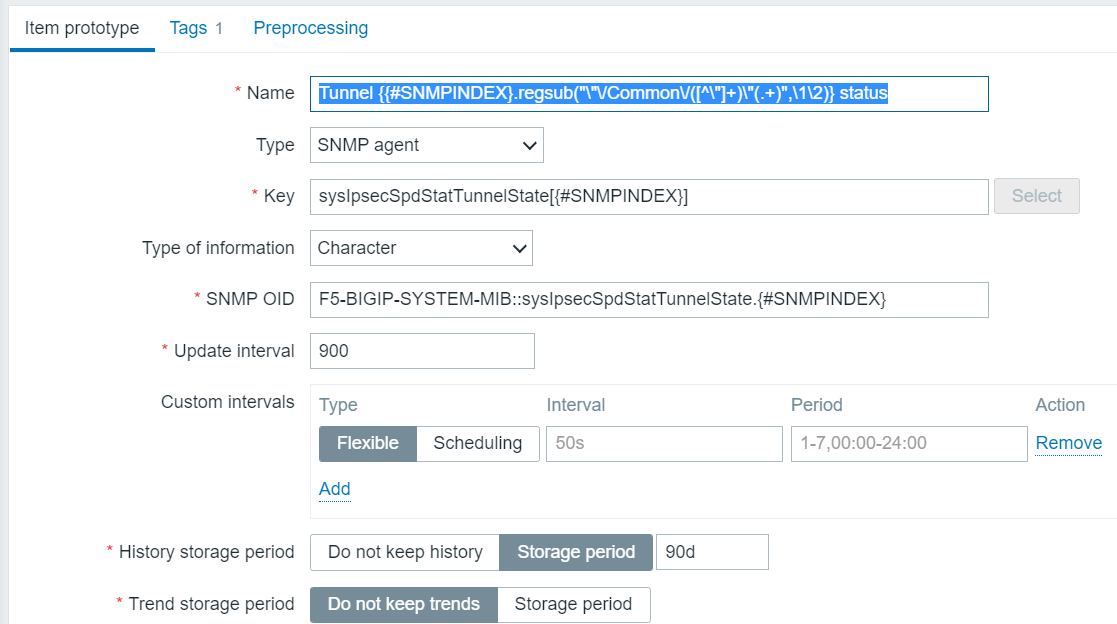
Tunnel Status Item prototype
So, yes, we’re doing some fancy regex to simplify the otherwise ungainly name which would be generated, stripping out the useless stuff with a regsub function, which, by the way, is poorly documented. So that’s how we’re going to discover the statuses of the tunnels. In text, the name is:
Tunnel {{#SNMPINDEX}.regsub(“\”\/Common\/([^\”]+)\”(.+)”,\1\2)} status
I learned how to choose the OID, which is the most critical part, I guess, from a combination of parsing the output of the snmpwalk plus imitation of those other LLD item prortypes, which were writtne by someone more competent than I.
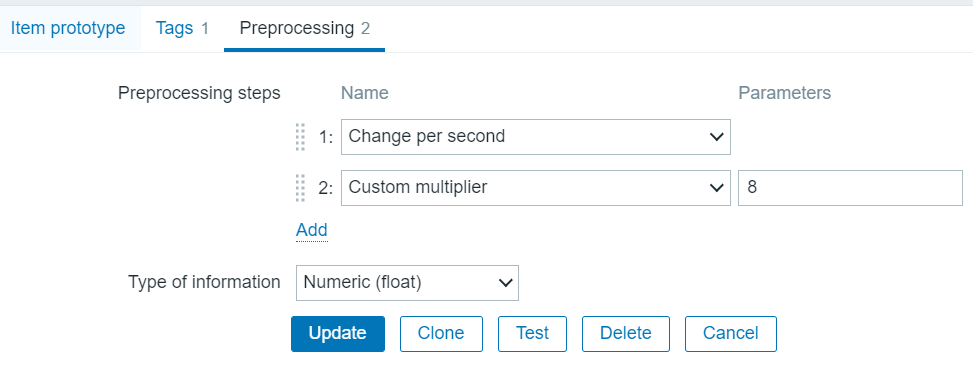
Now the SNMP value for traffic is bytes, but you see I set units of bps? I can do that because of the preprocessing steps which are
Bytes to traffic rate preprocessing steps
Final tip
For these discovery items what you want to do is to disable Create Enabled and disable Discover. I just run it on the F5s which actually have IPSEC tunnels. Execute now actually works and generates items pretty quickly.
Using the api with a token and security by obscurity
I am taking the approach of pulling the token out of a config file where it has been stored, base85 encoded, because, who uses base85, anyway? I call the following script encode.py:
import sys
from base64 import b85encode
s = sys.argv[1]
s_e = s.encode('utf-8')
s64 = b85encode(s_e)
print('s,s_e,s64',s,s_e,s64)
In my case I pull this encoded token from a config file, but to simplify, let’s say we got it from the command line. This is how that goes, and we use it to create the zapi object which can be used in any subsequent api calls. That is the key.
So it’s a few extra lines of code, but the cool thing is that it works. This should be good for version 5.4 and 6.0. Note that if you installed both py-zabbix and pyzabbix, your best bet may be to uninstall both and reinstall just pyzabbix. At least that was my experience going from user/pass to token-based authentication.
Convert DateAndTime SNMP output to human-readable format
Of course this is not very Zabbix-specific, as long as you realize that Zabbix produces the outer skin of the function:
function(value){
function (value) {
// DrJ 2020-05-04// see https://support.zabbix.com/browse/ZBXNEXT-3899 for SNMP DateAndTime format'use strict';//var str = "07 E4 05 04 0C 32 0F 00 2B 00 00";var str = value;// alert("str: " + str);// read values are hexvar y256 = str.slice(0,2);var y = str.slice(3,5);var m = str.slice(6,8);var d = str.slice(9,11);var h = str.slice(12,14);var min = str.slice(15,17);// convert to decimalvar y256Base10 =+("0x"+ y256);// convert to decimalvar yBase10 =+("0x"+ y);var Year =256*y256Base10 + yBase10;// alert("Year: " + Year);var mBase10 =+("0x"+ m);var dBase10 =+("0x"+ d);var hBase10 =+("0x"+ h);var minBase10 =+("0x"+ min);var YR =String(Year);var MM =String(mBase10);var DD =String(dBase10);var HH =String(hBase10);var MIN =String(minBase10);// paddingif(mBase10 <10) MM ="0"+ MM;if(dBase10 <10) DD ="0"+ DD;if(hBase10 <10) HH ="0"+ HH;if(minBase10 <10) MIN ="0"+ MIN;varDate= YR +"-"+ MM +"-"+ DD +" "+ HH +":"+ MIN;returnDate;
// DrJ 2020-05-04
// see https://support.zabbix.com/browse/ZBXNEXT-3899 for SNMP DateAndTime format
'use strict';
//var str = "07 E4 05 04 0C 32 0F 00 2B 00 00";
var str = value;
// alert("str: " + str);
// read values are hex
var y256 = str.slice(0,2); var y = str.slice(3,5); var m = str.slice(6,8);
var d = str.slice(9,11); var h = str.slice(12,14); var min = str.slice(15,17);
// convert to decimal
var y256Base10 = +("0x" + y256);
// convert to decimal
var yBase10 = +("0x" + y);
var Year = 256*y256Base10 + yBase10;
// alert("Year: " + Year);
var mBase10 = +("0x" + m);
var dBase10 = +("0x" + d);
var hBase10 = +("0x" + h);
var minBase10 = +("0x" + min);
var YR = String(Year); var MM = String(mBase10); var DD = String(dBase10);
var HH = String(hBase10);
var MIN = String(minBase10);
// padding
if (mBase10 < 10) MM = "0" + MM; if (dBase10 < 10) DD = "0" + DD;
if (hBase10 < 10) HH = "0" + HH; if (minBase10 < 10) MIN = "0" + MIN;
var Date = YR + "-" + MM + "-" + DD + " " + HH + ":" + MIN;
return Date;
I put that javascript into the preprocessing step of a dependent item, of course.
All my real-life examples do not fill in the last two fields: +/-, UTC offset. So in my case the times must be local times. But consequently I have no idea how a + or – would be represented in HEX! So I just ignored those last fields in the SNNMP DateAndTime which otherwise might have been useful.
Here’s an alternative version which calculates how long its been in hours since the last AV signature update.
// DrJ 2020-05-05// see https://support.zabbix.com/browse/ZBXNEXT-3899 for SNMP DateAndTime format'use strict';//var str = "07 E4 05 04 0C 32 0F 00 2B 00 00";var Start =newDate();var str = value;// alert("str: " + str);// read values are hexvar y256 = str.slice(0,2);var y = str.slice(3,5);var m = str.slice(6,8);var d = str.slice(9,11);var h = str.slice(12,14);var min = str.slice(15,17);// convert to decimalvar y256Base10 =+("0x"+ y256);// convert to decimalvar yBase10 =+("0x"+ y);var Year =256*y256Base10 + yBase10;// alert("Year: " + Year);var mBase10 =+("0x"+ m);var dBase10 =+("0x"+ d);var hBase10 =+("0x"+ h);var minBase10 =+("0x"+ min);var YR =String(Year);var MM =String(mBase10);var DD =String(dBase10);var HH =String(hBase10);var MIN =String(minBase10);var Sigdate =newDate(Year, mBase10 -1, dBase10,hBase10,minBase10);//difference in hoursvar difference =Math.trunc((Start - Sigdate)/1000/3600);return difference;
// DrJ 2020-05-05
// see https://support.zabbix.com/browse/ZBXNEXT-3899 for SNMP DateAndTime format
'use strict';
//var str = "07 E4 05 04 0C 32 0F 00 2B 00 00";
var Start = new Date();
var str = value;
// alert("str: " + str);
// read values are hex
var y256 = str.slice(0,2); var y = str.slice(3,5); var m = str.slice(6,8); var d = str.slice(9,11); var h = str.slice(12,14); var min = str.slice(15,17);
// convert to decimal
var y256Base10 = +("0x" + y256);
// convert to decimal
var yBase10 = +("0x" + y);
var Year = 256*y256Base10 + yBase10;
// alert("Year: " + Year);
var mBase10 = +("0x" + m);
var dBase10 = +("0x" + d);
var hBase10 = +("0x" + h);
var minBase10 = +("0x" + min);
var YR = String(Year); var MM = String(mBase10); var DD = String(dBase10);
var HH = String(hBase10);
var MIN = String(minBase10);
var Sigdate = new Date(Year, mBase10 - 1, dBase10,hBase10,minBase10);
//difference in hours
var difference = Math.trunc((Start - Sigdate)/1000/3600);
return difference;
function customSlice(array, start, end) {
var result = [];
var length = array.length;
// Handle negative start
start = start < 0 ? Math.max(length + start, 0) : start;
// Handle negative end
end = end === undefined ? length : (end < 0 ? length + end : end);
// Iterate over the array and push elements to result
for (var i = start; i < end && i < length; i++) {
result.push(array[i]);
}
return result;
}
function compareRangeWithExtractedIPs(ranges, result) {
// ranges is ["120.52.22.96/27","205.251.249.0/24"]
// I need to know if ips are in some of the ranges
var ipRegex = /\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b/g;
var ips = result.match(ipRegex) || [];
return ips.every(function(ip) {
return ranges.some(function(range) {
var rangeParts = range.split('/');
var rangeIp = rangeParts[0];
var rangeCidr = rangeParts[1];
var rangeIpParts = rangeIp.split('.').map(Number);
var ipParts = ip.split('.').map(Number);
var rangeBinary = rangeIpParts.map(toBinary).join('');
var ipBinary = ipParts.map(toBinary).join('');
return ipBinary.substring(0, rangeCidr) === rangeBinary.substring(0, rangeCidr);
});
});
}
function toBinary(num) {
var binary = num.toString(2);
return '00000000'.substring(binary.length) + binary;
}
function fetchData(url) {
try {
Zabbix.log(4, 'Starting GET request to the provided URL');
var result = {},
req = new HttpRequest(),
resp;
req.addHeader('Content-Type: application/json');
resp = req.get(url);
if (req.getStatus() != 200) {
throw 'Response code: ' + req.getStatus();
}
resp = JSON.parse(resp);
result.data = resp;
var ipPrefixes = resp.prefixes.map(function(prefix) {
return prefix.ip_prefix;
});
result.data = ipPrefixes;
} catch (error) {
Zabbix.log(4, 'GET request failed: ' + error);
result = {};
}
return JSON.stringify(result.data);
}
var result = fetchData('https://ip-ranges.amazonaws.com/ip-ranges.json');
var ranges = JSON.parse(result);
return compareRangeWithExtractedIPs(ranges, value);
This is the preprocessing step of a dependent item which ran a net.dns.record to do DNS outlook and get results as you see them from dig. I don’t fully understand how it works! My colleague wrote it and he used copilot mostly! He started making progress with Copilot once he constrained it to use “duct tape Javascript.” Apparently that’s a thing. This is defined within a template. It compares all of the returned IPs to a json list of expected possible ranges, which are pulled directly from an AWS endpoint. There are currently 7931 ranges, who knew?
Since this returns a true of false there are two subsequent preprocessing steps which Repalce true with 0 and false with 1 and we set the type to Numeric unsigned.
Calculated bandwidth from an interface that only provides byte count
Again in this example the assumption is you have an item, probably from SNMP, that lists the total inbound/outbound byte count of a network interface – hopefully stored as a 64-bit number to avoid frequent rollovers. But the quantity that really excites you is bandwidth, such as megabits per second.
Use a calculated item as in this example for Bluecoat ProxySG:
change(sgProxyInBytesCount)*8/1000000/300
change(sgProxyInBytesCount)*8/1000000/300
Give it type numeric, Units of mbps. sgProxyInBytesCount is the key for an SNMP monitor that uses OID
IF-MIB::ifHCInOctets.{$INTERFACE_TO_MEASURE}
IF-MIB::ifHCInOctets.{$INTERFACE_TO_MEASURE}
where {$INTERFACE_TO_MEASURE} is a macro set for each proxy with the SNMP-reported interface number that we want to pull the statistics for.
The 300 in the denominator of the calculated item is required for me because my item is run every five minutes.
Alternative
No one really cares about the actual total value of byte count, right? So just re-purpose the In Bytes Count item a bit as follows:
add preprocessing step: Change per second
add second preprocessing step, Custom multiplier 8e-6
The first step gives you units of bytes/second which is less interesting than mbps, which is given by the second step. So the final units are mbps.
Be sure to put the units as !mbps into the Zabbix item, or else you may wind up with funny things like Kmbps in your graphs!
Creating a baseline
Even as of Zabbix v 5, there is no built-in baseline item type, which kind of sucks. Baseline can mean many different things to many people – it really depends on the data. In the corporate world, where I’m looking at bandwidth, my data has these distinct characteristics:
varies by hour-of-day, e.g., mornings see heavier usage than afternoons
there is the “Friday effect” where somewhat less usage is seen on Fridays, and extremely less usage occurs on weekends, hence variability by day-of-week
probably varies by day of month, e.g., month-end closings
So for this type of data (except the last criterion) I have created an appropriate baseline. Note I would do something different if I were graphing something like the solar generation from my solar panels, where the day-of-week variability does not exist.
Getting to the point, I have created a rolling lookback item. This needs to be created as a Zabbix Item of type Calculated. The formula is as follows:
In this example sgProxyInBytesCount is my key from the reference item. Breaking it down, it does a rolling lookback of the last six measurements taken at this time of day on this day of the week over the last six weeks and averages them. Voila, baseline! The more weeks you include the more likely you are to include data you’d rather not like holidays, days when things were busted, etc. I’d like to have a baseline that is from a fixed time, like “all of last year.” I have no idea how. I actually don’t think it’s possible.
But, anyway, the baseline approach above should generally work for any numeric item.
Refinement
The above approach only gives you six measurements, hence 1/sqrt(6) ~ 40% standard deviation by the law of large numbers, which is still pretty jittery as it turns out. So I came up with this refined approach which includes 72 measurements, hence 1/sqrt(72) ~ 12% st dev. I find that to be closer to what you intuitively expect in a baseline – a smooth approximation of the past. Here is the refined function:
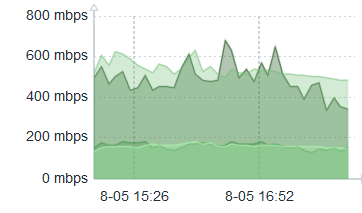
I would have preferred a one-hour interval centered around one week ago, etc., e.g., something like 1w+30m, but such date arithmetic does not seem possible in Zabbix functions. And, yeah, I could put 84600s (i.e., 86400 – 1800), but that is much less meaingful and so harder to maintain. Here is a three-hour graph whose first half still reflects the original (jittery) baseline, and last half the refined function.
Latter part has smoothed baseline in light green
What I do not have mastered is whether we can easily use a proper smoothing function. It does not seem to be a built-in offering of Zabbix. Perhaps it could be faked by a combination of pre-processing and Javascript? I simply don’t know, and it’s more than I wish to tackle for the moment.
Data gap between mulitple item measurements looks terrible in Dashboard graph – solution
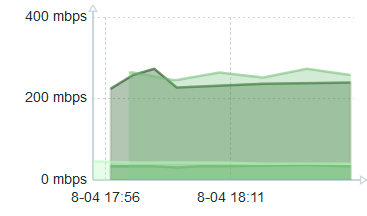
In a Dashboard if you are graphing items which were not all measured at the same time, the results can be frustrating. For instance, an item and its baseline as calculated above. The central part of the graph will look fine, but at either end giant sections will be missing when the timescale of display is 30 minutes or 60 minutes for items measured every five minutes or so. Here’s an example before I got it totally fixed.
Zabbix item timing mismatch
See the left side – how it’s broken up? I had beguin my fix so the right side is OK.
The data gap solution
Use Scheduling Intervals in defining the items. Say you want a measurement every five minutes. Then make your scheduling interval m/5 in all the items you are putting on the same graph. For good measure, make the regular interval value infrequent. I use a macro {$UPDATE_LONG}. What this does is force Zabbix to measure all the items at the same time, in this case every five minutes on minutes divisible by five. Once I did that my incoming bandwith item and its corresponding baseline item aligned nicely.
Low-level Discovery
I cottoned on to the utility of this part of Zabbix a little late. Hey, slow learner, but I eventually got there. What I found in my F5 devices is that using SNMP to monitor the /var filesystem was a snap: it was always device 32 (final OID digit). But /var/log monitoring? Not so much. Every device seemed different, with no obvious pattern. Active and standby units – identical hardware – and some would be 53, the partner 55. Then I rebooted a device and its number changed! So, clearly, dynamically assigned and no way was I going to keep up with it. I had learned the numbers by doing an snmpwalk. The solution to this dynamically changing OID number is to use low-level discovery.
Tip: using zabbix_sender in a more robust fashion
We run the Zabbix proxies as pairs. They are not run as a cluster. Instead one is active and the other is a warm standby. Then we can upgrade at our leisure the standby proxy, switch the hosts to it, then upgrade the other now-unused proxy.
But our scripts which send results using zabbix_sender run on other servers. Their data stops being recorded when the switch is made. What to do?
I learned you can send to both Zabbix proxies. It will fail on the standby one and succeed on the other. Since one proxy is always active, it will always succeed in sending its data!
A nice DNS synthetic monitor
It would have been so easy for Zabbix to have built in the capability of doing synthetic DNS checks against your DNS servers. But, alas, they left it out. Which leaves it to us to fill that gap. Here is a nice and simple but surprisingly effective script for doing synthetic DNS checks. You put it in the external script directory of whatever proxy is monitoring your DNS host. I called it dns.sh.
#!/bin/sh
# arg1 - hostname of nameserver
# arg2 - DNS server to test
# arg3 - FQDN
# arg4 - RR type
# arg5 - match arg
# [arg6] - tcpflag # this argument is optional
# if you set DEBUG=1, and debug through zabbix, set item type to text
DEBUG=0
timeout=2 # secs - seems a good value
name=$1
nameserver=$2
record=$3
type=$4
match=$5
tcpflag=$6
[[ "$DEBUG" -eq "1" ]] && echo "name: $name, nameserver: $nameserver , record: $record , type: $type , match pattern: $match, tcpflag: $tcpflag"
[[ "$tcpflag" = "y" ]] || [[ "$tcpflag" = "Y" ]] && PROTO="+tcp"
# unless you set tries to 1 it will try three times by default!
MATCH=$(dig +noedns +short $PROTO +timeout=$timeout +tries=1 $type $record @${nameserver} )
[[ "$DEBUG" -eq "1" ]] && echo MATCHed line is $MATCH
return=0
[[ "$MATCH" =~ $match ]] && return=1
[[ "$DEBUG" -eq "1" ]] && echo return $return
echo $return
It gives a value of 1 if it matched the match expression, 0 otherwise.
With Zabbix version 7 we finally replaced this nice external dns.sh script with built-in agent items. But it was a little tricky to throw that sort of item into a template – we had to define a host maro containing the IP of the host!
Convert a string to a number in item output
I’ve been bit by this a couple times. Create a dependent item. In the preprocessing steps first do a RegEx match and keep \0. Important to also check the Custom on Fail checkbox. Set value to 0 on fail. In the second step I used a replace and replaced the expected string with a 1.
I had a harder case where the RegEx had alternate strings. But that’s solvable as well! I created additional Replace steps with all possible alternate strings, setting each one to be replaced with 1. Kludge, yes, but it works. And that is how you turn a text item into a boolean style output of 0 or 1.
Conclusion
A couple of really useful but poorly documented items are shared. Perhaps more will be added in the future.
Intro
All of a sudden one day I could not access the GUI of one my security appliances. It had only worked yesterday. CLI access kind of worked – until it didn’t. It was the standby part of a cluster so I tried the active unit. Same issues. I have some ill-defined involvement with the firewall the traffic was traversing, so I tried to debug the problem without success. So I brought in a real firewall expert.
More details
Of course I knew to check the firewall logs. Well, they showed this traffic (https and ssh) to have been accepted, no problems. Hmm. I suspected some weird IPS thing. IPS is kind of a big black box to me as I don’t deal with it. But I have seen cases where it blocks traffic without logging the fact. But that concern led me to bring in the expert.
By myself I had gotten it to the point where I had done tcpdump (I had totally forgotten how to use fw monitor. Now I will know and refer to my own recent blog post) on the corporate network side as well as the protected subnet side. And I saw that packets were hitting the corporate network interface that weren’t crossing over to the protected subnet. Why? But first some more about the symptoms.
The strange behaviour of my ssh session
The web GUI just would not load the home page. But ssh was a little different. I could indeed log in. But my ssh froze every time I changed to the /var/log directory and did a detailed directory listing ls -l. The beginning of the file listing would come back, and then just hang there mid-stream, frozen. In my tcpdump I noticed that the packets that did not get through were larger than the ones sent in the beginning of the session – by a lot. 1494 data bytes or something like that. So I could kind of see that with ssh, you normally send smallish packets, until you need a bigger one for something like a detailed directory listing! And https sends a large server certificate at the beginning of the session so it makes sense that it would hang if those packets were being stopped. So the observed behaviour makes sense in light of the dropping of the large packets. But that doesn’t explain why.
I asked a colleague to try it and they got similar results.
The solution method
It had nothing to do with IPS. The firewall guy noticed and did several things.
He agreed the firewall logs showed my connection being accepted.
He saw that another firewall admin had installed policy around the time the problem began. We analyzed what was changed and concluded that was a false lead. No way those changes could have caused this problem.
He switched the active firewall to standby so that we used the standby unit. It worked just fine!
He observed that the current active unit became active around the time of the problem, due to a problem with an interface on the normally active unit.
I probably would have been fine to just work using the standby but I didn’t want to crimp his style, so he continued in investigating…and found the ultimate root cause.
And finally the solution
He noticed that on the bad firewall the one interface – I swear I am not making this up – had been configured with a non-standard MTU! 1420 instead of 1500.
Analysis
I did a head slap when he shared that finding. Of course I should have looked for that. It explains everything. The OS was dropping the packet, not the firewall blade per se. And I knew the history. Some years back these firewalls were used for testing OLTV, a tunneling technology to extend layer 2 across physically separated subnets. That never did work to my satisfaction. One of the issues we encountered was a problem with large packets. So the firewall guy at the time tried this out to help. Normally firewalls don’t fail so the one unit where this MTU setting was present just wasn’t really used, except for brief moments during OS upgrade. And, funny to say, this mis-configuration was even propagated from older hardware to newer! The firewall guys have a procedure where they suck up all the configuration from the old firewall and restore to the newer one, mapping updated interface names, etc, as needed.
Well, at least we found it before too many others complained. Though, as expected, complain they did, the next day.
Aside: where is curl?
I normally would have tested the web page from the firewall iself using curl. But curl has disappeared from Gaia v 80.20. And there’s no wget either. How can such a useful and universal utility be missing? The firewall guy looked it up and quickly found that instead of curl, they have curl_cli. Who knew?
Conclusion
The strange case of the large packets dropped by a firewall, but not by the firewall blade, was resolved the same day it occurred. It took a partner ship of two people bringing their domain-specific knowledge to bear on the problem to arrive at the solution.
Intro
Scripts are normally not worth sharing because they are so easy to construct. This one illustrates several different concepts so may be of interest to someone else besides myself:
packet trace utility in Checkpoint firewall Gaia
send Ctrl-C interrupt to a process which has been run in the background
giving unqieu filenames for each cut
general approach to tacklnig the challenge of breaking a potentially large output into manageable chunks
The script
I wanted to learn about unexpected VPN client disconnects that a user, Sandy, was experiencing. Her external IP is 99.221.205.103.
while /bin/true; do
# date +%H%M inserts the current Hour (HH) and minute (MM).
file=/tmp/sandy`date +%H%M`.cap
# fw monitor is better than tcpdump because it looks at all interfaces
fw monitor -o $file -l 60 -e "accept src=99.221.205.103 or dst=99.221.205.103;" &
# $! picks up the process number of the command we backgrounded just above
pid=$!
sleep 600
#sleep 90
kill $pid
sleep 3
gzip $file
done
while /bin/true; do
# date +%H%M inserts the current Hour (HH) and minute (MM).
file=/tmp/sandy`date +%H%M`.cap
# fw monitor is better than tcpdump because it looks at all interfaces
fw monitor -o $file -l 60 -e "accept src=99.221.205.103 or dst=99.221.205.103;" &
# $! picks up the process number of the command we backgrounded just above
pid=$!
sleep 600
#sleep 90
kill $pid
sleep 3
gzip $file
done
This type of tracing of this VPN session produces about 20 MB of data every 10 minutes. I want to be able to easily share the trace file afterwards in an email. And smaller files will be faster when analyzed in Wireshark.
The script itself I run in the background:
# ./sandy.sh &
And to make sure I don’t get logged out, I just run a slow PING afterwards:
# ping ‐i45 1.1.1.1
Alternate approaches
In retrospect I could have simply used the -ci argument and had the process terminate itself after a certain number of packets were recorded, and saved myself the effort of killing that process. But oh well, it is what it is.
Small tip to see all packets
Turn acceleration off:
fwaccel stat
fwaccel off
fwaccel on (when you’re done).
Conclusion
I share a script I wrote today that is simple, but illustrates several useful concepts.
Intro
I just learned of this really clear explanation of BGP hijacking, including interactive links, and what can be done to improve the current situation, namely, implement RPKI. I guess this weighs on me lately after I learned about another massive BGP hijacking out of Russia. See the references for these links.
References and related
This is the post I was referring to above, very interactive and not too technical. Is BGP Safe Yet?
Intro
Wordpress tells me to upgrade to version 5.4. But when I try it says nope, your version of php is too old. Now admittedly, I’m running on an ancient CentOS server, now at version 6.10, which I set up back in 2012 I believe.
I’m pretty comfortable with CentOS so I wanted to continue with it, but just on a newer version at Amazon. I don’t like being taken advantage of, so I also wanted to avoid those outfits which charge by the hour for providing CentOS, which should really be free. Those costs can really add up.
Lots of travails setting up my AWS image, and then…
I managed to find a CentOS amongst the community images. I chose centos-8-minimal-install-201909262151 (ami-01b3337aae1959300).
OK. Brand new CentOS 8 image, 8.1.1911 after patching it, which will be supported for 10 years. Surely it has the latest and greatest??
But I didn’t see it until after I had done all the work below the hard way. Oh well.
When I install php I get version 7.2.11. WordPress is telling me I need a minimum of php version 7.3. If i download the latest php, it tells me to download the latest apache. So I do. Version 2.4.43. I also install gcc, anticipating some compiling in my future…
But apache won’t even configure:
httpd-2.4.43]$ ./configure --enable-so
checking for chosen layout... Apache
checking for working mkdir -p... yes
checking for grep that handles long lines and -e... /usr/bin/grep
checking for egrep... /usr/bin/grep -E
checking build system type... x86_64-pc-linux-gnu
checking host system type... x86_64-pc-linux-gnu
checking target system type... x86_64-pc-linux-gnu
configure:
configure: Configuring Apache Portable Runtime library...
configure:
checking for APR... no
configure: error: APR not found. Please read the documentation.
httpd-2.4.43]$ ./configure --enable-so
checking for chosen layout... Apache
checking for working mkdir -p... yes
checking for grep that handles long lines and -e... /usr/bin/grep
checking for egrep... /usr/bin/grep -E
checking build system type... x86_64-pc-linux-gnu
checking host system type... x86_64-pc-linux-gnu
checking target system type... x86_64-pc-linux-gnu
configure:
configure: Configuring Apache Portable Runtime library...
configure:
checking for APR... no
configure: error: APR not found. Please read the documentation.
--with-apr=PATH prefix for installed APR or the full path to
apr-config
--with-apr-util=PATH prefix for installed APU or the full path to
apu-config
(apr-util configure)
checking for APR... no
configure: error: APR could not be located. Please use the --with-apr option.
try:
./configure --with-apr=/usr/local/apr
but
-D_GNU_SOURCE -I/usr/local/src/apr-util-1.6.1/include -I/usr/local/src/apr-util-1.6.1/include/private -I/usr/local/apr/include/apr-1 -o xml/apr_xml.lo -c xml/apr_xml.c && touch xml/apr_xml.lo
xml/apr_xml.c:35:10: fatal error: expat.h: No such file or directory
#include
^~~~~~~~~
compilation terminated.
make[1]: *** [/usr/local/src/apr-util-1.6.1/build/rules.mk:206: xml/apr_xml.lo] Error 1
--with-apr=PATH prefix for installed APR or the full path to
apr-config
--with-apr-util=PATH prefix for installed APU or the full path to
apu-config
(apr-util configure)
checking for APR... no
configure: error: APR could not be located. Please use the --with-apr option.
try:
./configure --with-apr=/usr/local/apr
but
-D_GNU_SOURCE -I/usr/local/src/apr-util-1.6.1/include -I/usr/local/src/apr-util-1.6.1/include/private -I/usr/local/apr/include/apr-1 -o xml/apr_xml.lo -c xml/apr_xml.c && touch xml/apr_xml.lo
xml/apr_xml.c:35:10: fatal error: expat.h: No such file or directory
#include
^~~~~~~~~
compilation terminated.
make[1]: *** [/usr/local/src/apr-util-1.6.1/build/rules.mk:206: xml/apr_xml.lo] Error 1
So I install expat header files:
$ yum install expat-devel
And then the make of apr-util goes through. Not sure this is the right approach or not yet, however.
So following php’s advice, I have:
$ ./configure –enable-so
checking for chosen layout... Apache
...
checking for pcre-config... false
configure: error: pcre-config for libpcre not found. PCRE is required and available from http://pcre.org/
checking for chosen layout... Apache
...
checking for pcre-config... false
configure: error: pcre-config for libpcre not found. PCRE is required and available from http://pcre.org/
So I install pcre-devel:
$ yum install pcre-devel
Now the apache configure goes through, but the make does not work:
/usr/local/apr/build-1/libtool --silent --mode=link gcc -g -O2 -pthread -o htpasswd htpasswd.lo passwd_common.lo /usr/local/apr/lib/libaprutil-1.la /usr/local/apr/lib/libapr-1.la -lrt -lcrypt -lpthread -ldl -lcrypt
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_GetErrorCode'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetEntityDeclHandler'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ParserCreate'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetCharacterDataHandler'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ParserFree'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetUserData'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_StopParser'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_Parse'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ErrorString'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetElementHandler'
collect2: error: ld returned 1 exit status
make[2]: *** [Makefile:48: htpasswd] Error 1
/usr/local/apr/build-1/libtool --silent --mode=link gcc -g -O2 -pthread -o htpasswd htpasswd.lo passwd_common.lo /usr/local/apr/lib/libaprutil-1.la /usr/local/apr/lib/libapr-1.la -lrt -lcrypt -lpthread -ldl -lcrypt
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_GetErrorCode'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetEntityDeclHandler'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ParserCreate'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetCharacterDataHandler'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ParserFree'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetUserData'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_StopParser'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_Parse'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_ErrorString'
/usr/local/apr/lib/libaprutil-1.so: undefined reference to `XML_SetElementHandler'
collect2: error: ld returned 1 exit status
make[2]: *** [Makefile:48: htpasswd] Error 1
So I try configure or apr-util with expat built-in.
But when I do the make of apr-util I now get this error:
/usr/local/apr/build-1/libtool: line 7475: cd: builtin/lib: No such file or directory
libtool: error: cannot determine absolute directory name of 'builtin/lib'
make[1]: *** [Makefile:93: libaprutil-1.la] Error 1
make[1]: Leaving directory '/usr/local/src/apr-util-1.6.1'
make: *** [/usr/local/src/apr-util-1.6.1/build/rules.mk:118: all-recursive] Error 1
From what I read this new error occurs due to having –expat-built-in! So now what? So I get rid of that in my configure statement for apr-util. For some reason, apr-util goes through and compiles. And so I try this for compiling apache24:
$ ./configure –enable-so –with-apr=/usr/local/apr
And then I make it. And for some reason, now it goes through. I doubt it will work, however… it kind of does work.
It threw the files into /usr/local/apache2, where there is a bin directory containing apachectl. I can launch apachectl start, and then access a default page on port 80. Not bad so far…
Hey, maybe for once their instructions will work. Nope.
configure: error: Package requirements (libxml-2.0 >= 2.7.6) were not met:
Package 'libxml-2.0', required by 'virtual:world', not found
Consider adjusting the PKG_CONFIG_PATH environment variable if you
installed software in a non-standard prefix.
So I guess I need to install libxml2-devel:
$ yum install libxm2-devel
Looks like I get past that error. Now it’s on to this one:
configure: error: Package requirements (sqlite3 > 3.7.4) were not met:
So I install sqlite-devel:
$ yum install sqlite-devel
Now my configure almost goes through, except, as I suspected, that was a nonsense argument:
It’s not there when you look for it! Why the heck did they – php.net – give an example with exactly that?? Annoying. So I leave it out. It goes through. Run make. It takes a long time to compile php! And this server is pretty fast. It’s slower than apache or anything else I’ve compiled.
But eventually the compile finished. It added a LoadModule statement to the apache httpd.conf file. And, after I associated files with php extension to the php handler, a test file seemed to work. So php is beginning to work. Not at all sure about the mysql tie-in, however. In fact see further down below where I confirm my fears that there is no MySQL support when PHP is compiled this way.
Is running SSL asking too much?
Apparently, yes. I don’t think my apache24 has SSL support built-in:
Invalid command 'SSLCipherSuite', perhaps misspelled or defined by a module not included in the server configuration
Invalid command 'SSLCipherSuite', perhaps misspelled or defined by a module not included in the server configuration
So I try
$ ./configure –enable-so –with-apr=/usr/local/apr –enable-ssl
Not good…
checking for OpenSSL... checking for user-provided OpenSSL base directory... none
checking for OpenSSL version >= 0.9.8a... FAILED
configure: WARNING: OpenSSL version is too old
no
checking whether to enable mod_ssl... configure: error: mod_ssl has been requested but can not be built due to prerequisite failures
checking for OpenSSL... checking for user-provided OpenSSL base directory... none
checking for OpenSSL version >= 0.9.8a... FAILED
configure: WARNING: OpenSSL version is too old
no
checking whether to enable mod_ssl... configure: error: mod_ssl has been requested but can not be built due to prerequisite failures
Where is it pulling that old version of openssl? Cause when I do this:
$ openssl version
OpenSSL 1.1.1c FIPS 28 May 2019
OpenSSL 1.1.1c FIPS 28 May 2019
That’s not that old…
I also noticed this error:
configure: WARNING: Your APR does not include SSL/EVP support. To enable it: configure --with-crypto
So maybe I will re-compile APR with that argument.
Nope. APR doesn’t even have that argument. But apr-uil does. I’ll try that.
Not so good:
configure: error: Crypto was requested but no crypto library could be enabled; specify the location of a crypto library using --with-openssl, --with-nss, and/or --with-commoncrypto.
I give up. maybe it was a false alarm. I’ll try to ignore it.
This time at least the configure goes through – no ssl-related errors.
I needed to add the Loadmodule statement by hand to httpd.conf since that file was already there from my previous build and so did not get that statement after my re-build with ssl support:
LoadModule ssl_module modules/mod_ssl.so
LoadModule ssl_module modules/mod_ssl.so
Next error please
Now I have this error:
AH00526: Syntax error on line 92 of /usr/local/apache2/conf/extra/drjohns.conf:
SSLSessionCache: 'shmcb' session cache not supported (known names: ). Maybe you need to load the appropriate socache module (mod_socache_shmcb?).
AH00526: Syntax error on line 92 of /usr/local/apache2/conf/extra/drjohns.conf:
SSLSessionCache: 'shmcb' session cache not supported (known names: ). Maybe you need to load the appropriate socache module (mod_socache_shmcb?).
I want results. So I just comment out the lines that talk about SSL Cache and anything to do with SSL cache.
And…it starts…and…it is listening on both ports 80 and 443 and…it is running SSL. So I think i cracked the SSL issue.
Switch focus to Mysql
I didn’t bother to find mysql. I believe people now use mariadb. So I installed the system one with a yum install mariadb. I became root and learned the version with a select version();
+-----------------+
| version() |
+-----------------+
| 10.3.17-MariaDB |
+-----------------+
1 row in set (0.000 sec)
+-----------------+
| version() |
+-----------------+
| 10.3.17-MariaDB |
+-----------------+
1 row in set (0.000 sec)
Is that recent enough? Yes! For once we skate by comfortably. The WordPress instructions say:
MySQL 5.6 or MariaDB 10.1 or greater
I setup apache. I try to access wordpress setup but instead get this message:
Forbidden
You don't have permission to access this resource.
Forbidden
You don't have permission to access this resource.
every page I try gives this error.
The apache error log says:
client denied by server configuration: /usr/local/apache2/htdocs/
client denied by server configuration: /usr/local/apache2/htdocs/
Not sure where that’s coming from. I thought I supplied my own documentroot statements, etc.
I threw in a Require all granted within the Directory statement and that seemed to help.
PHP/MySQL communication issue surfaces
Next problem is that PHP wasn’t compiled correctly it seems:
Your PHP installation appears to be missing the MySQL extension which is required by WordPress.
Your PHP installation appears to be missing the MySQL extension which is required by WordPress.
So I’ll try to re-do it. This time I am trying these arguments to configure:
$ ./configure ‐‐with-apxs2=/usr/local/apache2/bin/apxs ‐‐with-mysqli
Well, I’m not so sure this worked. Trying to setup WordPress, I access wp-config.php and only get:
Error establishing a database connection
Error establishing a database connection
This is roll up your sleeves time. It’s clear we are getting no breaks. I looked into installing PhpMyAdmin, but then I would neeed composer, which may depend on other things, so I lost interest in that rabbit hole. So I decide to simplify the problem. The suggested test is to write a php program like this, which I do, calling it tst2.php:
PHP Warning: mysqli_connect(): (HY000/2002): No such file or directory in /web/drjohns/blog/tst2.php on line 7
Warning: mysqli_connect(): (HY000/2002): No such file or directory in /web/drjohns/blog/tst2.php on line 7
PHP Warning: mysqli_connect(): (HY000/2002): No such file or directory in /web/drjohns/blog/tst2.php on line 7
Warning: mysqli_connect(): (HY000/2002): No such file or directory in /web/drjohns/blog/tst2.php on line 7
Some quick research tells me that php does not know where the file mysql.sock is to be found. I search for it:
$ sudo find / ‐name mysql.sock
and it comes back as
/var/lib/mysql/mysql.sock
/var/lib/mysql/mysql.sock
So…the prescription is to update a couple things in pph.ini, which has been put into /usr/local/lib in my case because I compiled php with mostly default values. I add the locatipon of the mysql.sock file in two places for good measure:
Install WordPress
I begin to install WordPress, creating an initial user and so on. When I go back in I get a directory listing in place of the index.php. So I call index.php by hand and get a worisome error:
Fatal error: Uncaught Error: Call to undefined function gzinflate() in /web/drjohns/blog/wp-includes/class-requests.php:947 Stack trace: #0 /web/drjohns/blog/wp-includes/class-requests.php(886): Requests::compatible_gzinflate('\xA5\x92\xCDn\x830\f\x80\xDF\xC5g\x08\xD5\xD6\xEE...'
Fatal error: Uncaught Error: Call to undefined function gzinflate() in /web/drjohns/blog/wp-includes/class-requests.php:947 Stack trace: #0 /web/drjohns/blog/wp-includes/class-requests.php(886): Requests::compatible_gzinflate('\xA5\x92\xCDn\x830\f\x80\xDF\xC5g\x08\xD5\xD6\xEE...'
I should have compiled php with zlib is what I determine it means… zlib and zlib-devel packages are on my system so this should be straightforward.
More arguments for php compiling
OK. Let’s be sensible and try to reproduce what I had done in 2017 to compile php instead of finding an resolving mistakes one at a time.
Package 'libcurl', required by 'virtual:world', not found
I will install libcurl-devel in hopes of making this one go away.
Past that error, and onto this one:
configure: error: DBA: Could not find necessary header file(s).
I’m trying to drop the –with-gdbm and skip that whole DBA thing since the database connection seemed to be working without it. Now I see an openssl problem:
make: *** No rule to make target '/tmp/php-7.4.4/ext/openssl/openssl.c', needed by 'ext/openssl/openssl.lo'. Stop.
make: *** No rule to make target '/tmp/php-7.4.4/ext/openssl/openssl.c', needed by 'ext/openssl/openssl.lo'. Stop.
Even if I get rid of openssl I still see a problem when running configure:
gawk: ./build/print_include.awk:1: fatal: cannot open file `ext/zlib/*.h*' for reading (No such file or directory)
gawk: ./build/print_include.awk:1: fatal: cannot open file `ext/zlib/*.h*' for reading (No such file or directory)
Now I can ignore that error because configure exits with 0 status and make, but the make then stops at zlib:
SIGNALS -c /tmp/php-7.4.4/ext/sqlite3/sqlite3.c -o ext/sqlite3/sqlite3.lo
make: *** No rule to make target '/tmp/php-7.4.4/ext/zlib/zlib.c', needed by 'ext/zlib/zlib.lo'. Stop.
SIGNALS -c /tmp/php-7.4.4/ext/sqlite3/sqlite3.c -o ext/sqlite3/sqlite3.lo
make: *** No rule to make target '/tmp/php-7.4.4/ext/zlib/zlib.c', needed by 'ext/zlib/zlib.lo'. Stop.
Reason for above php compilation errors
I figured it out. My bad. I had done a make distclean in addition to a make clean when i was re-starting with a new set of arguments to configure. i saw it somewhere advised on the Internet and didn’t pay much attention, but it seemed like a good idea. But I think what it was doing was wiping out the files in the ext directory, like ext/zlib.
So now I’m starting over, now with php 7.4.5 since they’ve upgraded in the meanwhile! With this configure command line (I figure I probably don’t need gdb):
./configure –with-apxs2=/usr/local/apache2/bin/apxs –with-mysqli –disable-cgi –with-zlib –with-gettext –with-gdbm –with-curl –with-openssl
Well, the php compile went through, however, I can’t seem to access any WordPress pages (all WordPress pages clock). Yet my simplistic database connection test does work. Hmmm. OK. If they come up at all, they come up exceedingly slowly and without correct formatting.
I think I see the reason for that as well. The source of the wp-login.php page (as viewed in a browser window) includes references to former hostnames my server used to have. Of course fetching all those objects times out. And they’re the ones that provide the formatting. At this point I’m not sure where those references came from. Not from the filesystem, so must be in the database as a result of an earlier WordPress install attempt. Amazon keeps changing my IP, you see. I see it is embedded into WordPress. In Settings | general Settings. I’m going to have this problem every time…
What I’m going to do is to create a temporary fictitious name, johnstechtalk, which I will enter in my hosts file on my Windows PC, in Windows\system32\drivers\etc\hosts, and also enter that name in WordPress’s settings. I will update the IP in my hosts file every time it changes while I am playing around. And now there’s even an issue doing this which has always worked so reliably in the past. Well, I found I actually needed to override the IP for drjohnstechtalk.com in my hosts file. But it seems Firefox has moved on to using DNS over https, so it ignores the hosts file now! i think. Edge still uses it however, thankfully.
WordPress
So WordPress is basically functioning. I managed to install a few of my fav plugins: Akismet anti-spam, Limit Login Attempts, WP-PostViews. Some of the plugins are so old they actually require ftp. Who runs ftp these days? That’s been considered insecure for many years. But to accommodate I installed vsftpd on my server and ran it, temporarily.
Then Mcafee on my PC decided that wordpress.org is an unsafe site, thank you very much, without any logs or pop-ups. I couldn’t reach that site until I disabled the Mcafee firewall. Makes it hard to learn how to do the next steps of the upgrade.
More WordPress difficulties
WordPress is never satisfied with whatever version you’ve installed. You take the latest and two weeks later it’s demanding you upgrade already. My first upgrade didn’t go so well. Then I installed vsftpd. The upgrade likes to use your local FTP server – at least in my case. so for ftp server I just put in 127.0.0.1. Kind of weird. Even still I get this error:
Downloading update from https://downloads.wordpress.org/release/wordpress-5.4.2-no-content.zip…
The authenticity of wordpress-5.4.2-no-content.zip could not be verified as no signature was found.
Unpacking the update…
Could not create directory.
Installation Failed
So I decided it was a permissions problem: my apache was running as user daemon (do a ps -ef to see running processes), while my wordpress blog directory was owned by centos. So I now run apache as user:group centos:centos. In case this helps anyone the apache configurtion commands to do this are:
User centos
Group centos
then I go to my blog directory and run something like:
chown -R centos:centos *
Wordpres Block editor non-functional after the upgrade
When I did the SQL import from my old site, I killed the block editor on my new site! This was disconcerting. That little plus sign just would not show up on new pages, no posts, whatever. So I basically killed wordpress 5.4. So I took a step backwards and started v 5.4 with a clean (empty) database like a fresh install to make sure the block editor works then. It did. Whew! Then I did an RTFM and deactivated my plugins on my old WordPress install before doing the mysql backup. I imported that SQL database, with a very minimal set of plugins activated, and, whew, this time I did not blow away the block editor.
CentOS bogs down
I like my snappy new Centos 8 AMI 80% of the time. But that remaining 20% is very annoying. It freezes. Really bad. I ran a top until the problem happened. Here I’ve caught the problem in action:
top - 16:26:11 up 1 day, 21 min, 2 users, load average: 3.96, 2.93, 5.30
Tasks: 95 total, 1 running, 94 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 2.6 sy, 0.0 ni, 0.0 id, 95.8 wa, 0.4 hi, 0.3 si, 0.7 st
MiB Mem : 1827.1 total, 63.4 free, 1709.8 used, 53.9 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 9.1 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
44 root 20 0 0 0 0 S 1.6 0.0 12:47.94 kswapd0
438 root 0 -20 0 0 0 I 0.5 0.0 1:38.84 kworker/0:1H-kblockd
890 mysql 20 0 1301064 92972 0 S 0.4 5.0 1:26.83 mysqld
5282 centos 20 0 1504524 341188 64 S 0.4 18.2 0:06.06 httpd
5344 root 20 0 345936 1008 0 S 0.4 0.1 0:00.09 sudo
560 root 20 0 93504 6436 3340 S 0.2 0.3 0:02.53 systemd-journal
712 polkitd 20 0 1626824 4996 0 S 0.2 0.3 0:00.15 polkitd
817 root 20 0 598816 4424 0 S 0.2 0.2 0:12.62 NetworkManager
821 root 20 0 634088 14772 0 S 0.2 0.8 0:18.67 tuned
1148 root 20 0 216948 7180 3456 S 0.2 0.4 0:16.74 rsyslogd
2346 john 20 0 273640 776 0 R 0.2 0.0 1:20.73 top
1 root 20 0 178656 4300 0 S 0.0 0.2 0:11.34 systemd
So what jumps out at me is the 95.8% wait time – that ain’t good – an that a process which includes the name swap is at the top of ths list, combined with the fact that exactly 0 swap space is allocated. My linux skills may be 15 years out-of-date, but I think I better allocate some swap space (but why does it need it so badly??). On my old system I think I had done it. I’m a little scared to proceed for fear of blowing up my system.
So if you use drjohnstechtalk.com and it freezes, just come back in 10 minutes and it’ll probably be running again – this situation tends to self-correct. No one’s perfect.
Some of the commands are dd to create an empty file, mkswap, swapon and swapon -s to see what it’s doing. And it really, really helped. I think sometimes mariadb needed to swap, and sometimes apache did. My system only has 1.8 GB of memory or so. And the drive is solid state, so it should be kind of fast. Because I used 1.2 GB for swap, I also extended my volume size when I happened upon Amazon’s clear instructions on how you can do that. Who knew? See below for more on that. If I got it right, Amazon also gives you more IO for each GB you add. I’m definitely getting good response after this swap space addition.
An aside about i/o
In the old days I perfected a way to study i/o using the iostat utility. You can get it by installing the sysstat package. A good command to run is iostat -t -c -m -x 5
Examing these three consecutive lines of output from running that command is very instructional:
I tooled around in the admin panel (which previously had brought my server to its knees), and you see the %util shot up to 90%, reads per sec over 2000 , writes per second 1400. So, really demanding. It’s clear my server would die if more than a few people were hitting it hard. And I may need some fine-tuning.
Success!
Given all the above problems, you probably never thought I’d pull this off. I worked in fits and starts – mostly when my significant other was away because this stuff is a time suck. But, believe it or not, I got the new apache/openssl/apr/php/mariadb/wordpress/centos/amazon EC2 VPC/drjohnstechtalk-with-new-2020-theme working to my satisfaction. I have to pat myself on the back for that. So I pulled the plug on the old site, which basically means moving the elastic IP over from old centos 6 site to new centos8 AWS instance. Since my site was so old, I had to first convert the elastic IP from type classic to VPC. It was not too obvious, but I got it eventually.
Damn hackers already at it
Look at the access log of your new apache server running your production WordPress. If you see like I did people already trying to log in (POST accesses for …/wp-login.php), which is really annoying because they’re all hackers, at least install the WPS Hide Login plugin and configure a secret login URL. Don’t use the default login.
Meanwhile I’ve decided to freeze out anyone who triess to access wp-login.php because they can only be up to no good. So I created this script which I call wp-login-freeze.sh:
#!/bin/sh
# freeze hackers who probe for wp-login
# DrJ 6/2020
DIR=/var/log/drjohns
cd $DIR
while /bin/true; do
tail -200 access_log|grep wp-login.php|awk '{print $1}'|sort -u|while read line; do
echo $line
route add -host $line reject
done
sleep 60
done
Works great! Just do a netstat -rn to watch your ever-growing list of systems you’ve frozen out.
But xmlrpc is the worst…
Bots which invoke xmlrpc.php are the worst for little servers like mine. They absolutely bring it to its knees. So I’ve just added something similar to the wp-login freeze above, except it catches xmlrpc bots:
#!/bin/sh
# freeze hackers who are doing God knows what to xmlrpc.php
# DrJ 8/2020
DIR=/var/log/drjohns
cd $DIR
while /bin/true; do
# example offending line:
# 181.214.107.40 - - [21/Aug/2020:08:17:01 -0400] "POST /blog//xmlrpc.php HTTP/1.1" 200 401
tail -100 access_log|grep xmlrpc.php|grep POST|awk '{print $1}'|sort -u|while read line; do
echo $line
route add -host $line reject
done
sleep 30
done
I was still dissatisfied with seeing bots hit me up for 30 seconds or so, so I decided heck with it, I’m going to waste their time first. So I added a few lines to xmlrpc.php (I know you shouldn’t do this, but hackers shouldn’t do what they do either):
// DrJ improvements
if ($_SERVER['REQUEST_METHOD'] === 'POST') {
// just make bot suffer a bit... the freeze out is done by an external script
sleep(25);
//
}
// end DrJ enhancements
This freeze out trick within xmlrpc.php was only going to work if the bots run single-threaded, that is, they run serially, waiting for one request to finish before sending the next. I’ve been running it for a couple days and have enthusiasitically frozen out a few IPs. I can attest that the bots do indeed run single-threaded. So I typically get two entries in my access file to xmlrpc from a given bot, and then the bot is completely frozen out by the loopback route which gets added.
Mid-term issues discovered months later
Well, I never needed to send emails form my server, until I did. And when I did I found I couldn’t. It used to work from my old server… From reading a bit I see WordPress uses PHP’s built-in mail() function, which has its limits. But my server did not have mailx or postfix packages. So I did a
$ yum install postfix mailx
$ systemctl enable postfix
$ systemctl start postfix
That still didn’t magically make WordPress mail work, although at that point I could send mail by hand frmo a spoofed address, which is pretty cool, like:
$ mailx -r “john@drjs.com” -s “testing email” drjohntech@gmail.com <<< “Test of a one-line email test. – drJ”
And I got it in my Gmail account from that sender. Cool.
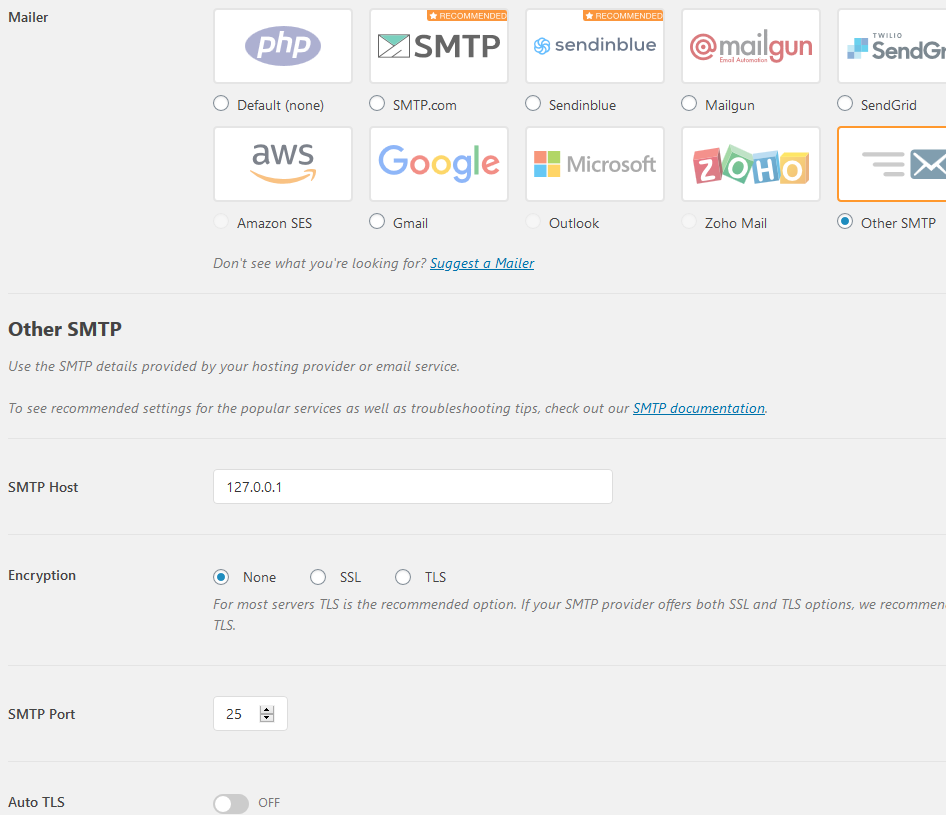
Rather than wasting time debuggin PHP, I saw a promising-looking plug-in, WP Mail SMTP, and installed it. Here is how I configured the important bits:
WP Mail SMTP settings
Another test from WordPress and this time it goes through. Yeah.
Hosting a second WordPress site and Ninja Forms brings it all down
Well, wouldn’t you know my friend’s WordPress site I was trying to host brought my server to its knees. Again. Seems to be a common theme. I was hoping it was merely hackers who’d discovered his new site and injected it with the xmlrpc DOS because that would have been easy to treat. But no, no xmlrpc issues so far according to the access_log file. He uses more of the popular plugins like Elementor and Ninja Forms. Well, that Ninja Forms Dashboard is a killer. Reliably brings my server to a crawl. I even caught it in action from a running top and saw swap was the leading cpu-consuming process. And my 1.2 GB swap file was nearly full. So I created a second, larger swap file of 2 GB and did a swapon for that. Then I decommissioned my older swap file. Did you know you can do a swapoff? Yup. I could see the old one descreasing in size and the new one building up. And now the new one is larger than the old ever could be – 1.4 GB. Now Ninja forms dashboard can be launched. Performance is once again OK.
So…hosting second WordPress site now resolved.
Updating failed. The response is not a valid JSON response.
So then he got that error after enabling permalinks. The causes for this are pretty well documented. We took the standard advice and disabled all plugins. Wihtout permalinks we were fine. With them JSON error. I put the .htaccess file in place. Still no go. So unlike most advice, in my case, where I run my own web server, I must have goofed up the config and not enabled reading of the .htaccess file. Fortunately I had a working example in the form of my own blog site. I put all those apache commands which normally go into .htaccess into the vhost config file. All good.
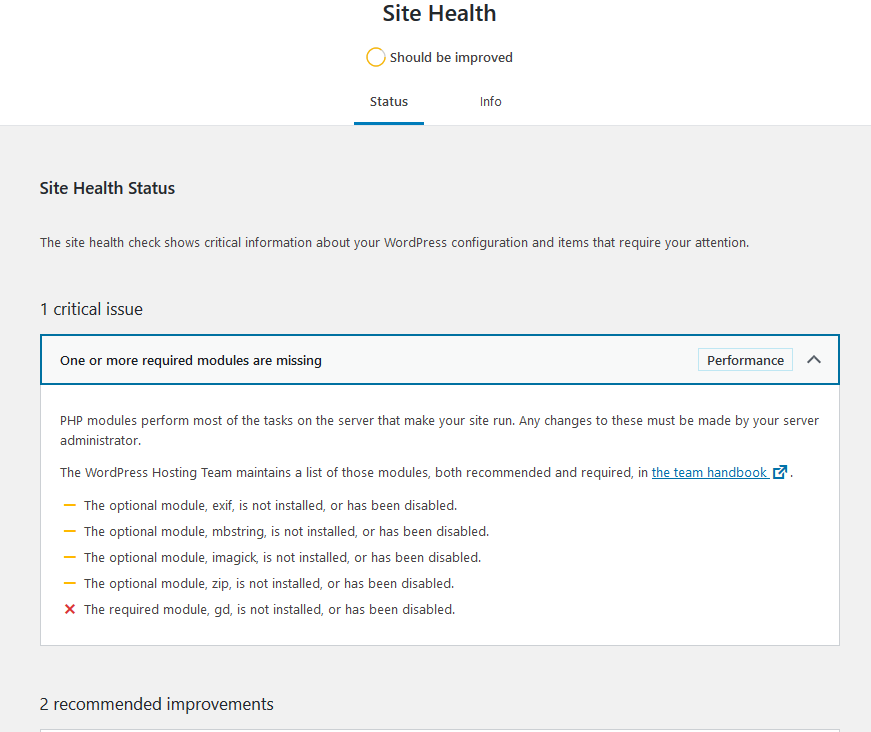
Although my site seems to be humming alnog, now I have to find the more obscure errors. WordPress mentioned my site health has problems.
WordPress site health
I think gd is used for graphics. I haven’t seen any negative results from this, yet. I may leave it be for the time being.
Lets Encrypt certificate renewal stops working
This one is at the bottom because it only manifests itself after a couple months – when the web site certificate either expires or is about to expire. Remember, this is a new server. I was lazy, of course, and just brought over the .acme.sh from the old server, hoping for the best. I didn’t notice any errors at first, but I eventually observed that my certificate was not getting renewed either even though it had only a few days of validity left.
To see what’s going on I ran this command by hand:
acme.sh new-authz error: {"type":"urn:acme:error:badNonce","detail":"JWS has no anti-replay nonce","status": 400}
seemed to be the most important error I noticed. The general suggestion for this is an acme.sh –upgrade, which I did run. But the nonce error persisted. It tries 20 times then gives up.
— warning: I know enough to get the job done, but not enough to write the code. Proceed at your own risk —
I read some of my old blogs and played with the command
My Webroot is /web/drjohns by the way. Now at least there was an error I could understand. I saw it trying to access something like http://drjohnstechtalk.com/.well-known/acme-challenge/askdjhaskjh
which produced a 404 Not Found error. Note the http and not https. Well, I hadn’t put much energy into setting up my http server. In fact it even has a different webroot. So what I did was to make a symbolic link
ln -s /web/drjohns/.well-known /web/insecure
I re-ran the acme.sh –issue command and…it worked. Maybe if I had issued a –renew it would not have bothered using the http server at all, but I didn’t see that switch at the time. So in my crontab instead of how you’re supposed to do it, I’m trying it with these two lines:
# Not how you're supposed to do it, but it worked once for me - DrJ 8/16/20
22 2 * * * "/root/.acme.sh"/acme.sh --issue -d drjohnstechtalk.com -w /web/drjohns > /dev/null 2>&1
22 3 16 * * "/root/.acme.sh"/acme.sh --update-account --issue -d drjohnstechtalk.com -w /web/drjohns > /dev/null 2>&1
The update-account is just for good measure so I don’t run into an account expiry problem which I’ve faced in the past. No idea if it’s really needed. Actually my whole approach is a kludge. But it worked. In two months’ time I’ll know if the cron automation also works.
Why kludge it? I could have spent hours and hours trying to get acme.sh to work as it was intended. I suppose with enough persistence I would have found the root problem.
2021 update. In retrospect
In retrospect, I think I’ll try Amazon Linux next time! I had the opportunity to use it for my job and I have to say it was pretty easy to set up a web server which included php and MariaDB. It feels like it’s based on Redhat, which I’m most familiar with. It doesn’t cost extra. It runs on the same small size on AWS. Oh well.
2022 update
I’m really sick of how far behind Redhat is with their provided software. And since they’ve been taken over by IBM, how they’ve killed CentOS is scandalous. So I’m inclined to go to a Debian-based system for my next go-around, which is much more imminent than I ever expected it to be thanks to the discontinuation of support for CentOS. I asked someone who hosts a lot of WP sites and he said he’d use Ubuntu server 22, PHP 8, MariaDB and NGinx. Boy. Guess I’m way behind. He says performance with PHP 8 is much better. I’ve always used apache but I guess I don’t really rely on it for too many fancy features.
Intro
This is pretty esoteric, but I’ve personally been waiting for this for a long time. It seems that beginning with openssl 1.1, the s_client sub-menu has had support for a proxy setting. Until then it was basically impossible to examine the certificates your proxy was sending back to users.
Why is it a great thing? If your proxy does SSL interception then it is interfering with with the site’s normal certificate. And worse, it can good. What if its own signing certificate has expired?? I’ve seen it happen, and it isn’t pretty…
To find the openssl version just run openssl version.
My SLES12 SP4 servers have a version which is too old. My Cygwin install is OK, actually. My Redhat 7.7 has a version which is too old. I do have a SLES 15 server which has a good version. But even the version on my F5 devices is too old, surprisingly.
Intro The end pieces of the pergola above my deck kept blowing off. I finally lost track of them and decided to 3D print a replacement to keep my skills fresh. I will use this as an opportunity to review my process for 3D printing.
The details For people like me who don’t really know what they are doing, the kinds of objects you can 3D print is pathetically small. Yes, there are sites like thingiverse.com. But there are so many physical constraints if striking out on your own. If the extruder is pulling the filament horizontally it can only be unsupported for, I forget, 1 cm or so. That may be called a bridge. If you’re going from smaller to wider, the angle of increase cannot be greater than 45 degrees though I think 30 degrees is a safer bet. If you can want to violate either of those contraints you’ll have to include supports which you later saw away (yuck).
So those two constraints, combined, kill just about anything you’d ever want to print.
But, amazingly, my endplates could meet the criteria, if I made a slight compromise, so I went for it.
Openscad I use openscad.org’s software to make a mathematical model of the object, built up from primitive geometric shapes (cubes and cylinders, mainly). When I learned you could write a simple program to generate your figure, and see the results rendered, I was like, sign me up.
Here is my openscad code, with some extra unused stuff left over from a previous design.
STL You always make mistakes. The question is if you have the trouble-shooting skills to catch them before committing to printing… Anyway, when satisfied, render your object (F6), only then can you export to STL (stereolithography), which I guess is a universal description language.
Cura Then you need a slicer! I think that translates your shape into movements that the 3D printer needs to make to lay down the filament, layer by layer. So import your STL file into Cura.
I think I set up Cura last year. I don’t want to mess with it. And don’t start playing with your model. It’ll do funny things to it. Just save as GCode. That’s it. Cura kindly estimates how long your print will take, and how much filament it will use up.
Cura will every time propose to upgrade itself. Don’t waste your time. Just say no. If all you’re doing is using it to turn STL into GCode you don’t need the latest. Anet a8 printer It can be a royal pain to adjust the Z axis. Usually you have to adjust all four corners so that pulling a paper through gives just a little friction. The screws and assembly is so bad that you are constantly shifting between over-correcting and under-correcting. In this case I divided the problem in two because the plate was so narrow I just adjusted for the two sides, not all four corners, which is a nightmare. And I’m a little ahead of myself, but I have to say that this approach worked brilliantly.
Transfer the file to the micro SD card. Print, and enjoy! More fun is printing something with a lot of holes. The printer makes the coolest electric sounds as it quickly shuttles back and forth and to and fro. This endplate is pretty boring by comparison and mostly consists of long stretches of material.
End result
side by side
With its long flat section, the thing really adheres to the plate, unfortunately. I slightly nicked a corner prying it off with a screwdriver. But I think that beats the alternative of it not adhering to your plate. I’ve seen that once – and the printed thing just gets dragged around, which is fatal.
My piece came out a couple millimeters short in both dimensions. Still functional because of what it is, but still something I need to understand better.
Industrial design I take it for granted that the PLA I’m printing is not as strong as the original plastic, so I should compensate by making edges thicker than needed. But I have to say the thing came out quite rigid and strong. This cheap 3D printer – if you treat it right – produces some high-quality output!
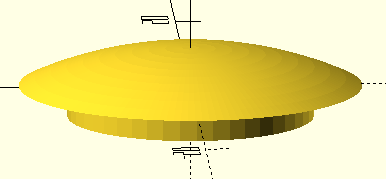
Bolt hole cover In June I decided to print a bolt hole cover, also for the pergola above my deck. Modelling was pretty easy. I used a sphere for the first time to create the curved shape of the cover. Then I had to “get rid” of the rest of the sphere so I swallowed the unwanted portion of it up with a giant cylinder.
Here’s the openscad code.
// DrJ 6/2020. Parameters in mm
innerR=8;outerR=11;plugHeight=2;
epsilon=0.4;upperHeight=2.5;
sphereR=26; big=50;
tinyR=1;
// min facet angle and facet size (mm)
$fa = 1.1; $fs = 1.1;
difference() {
translate([0,0,-(sphereR - upperHeight)]) color ([0.2, 0, 0]) sphere(r=sphereR);
translate([0,0,-big/2]) cylinder(r=big,h=big,center=true);
}
translate([0,0,-plugHeight/2]) cylinder(r=innerR,h=plugHeight, center=true);
Bolt hole cover
I installed Cura v. 3.2.1 to make sure I had a version with support for supports, ha, ha. Most views don’t even show the support. I made sure I had it generate supports. Then I found that the layers view, when you drag it through the layers, shows the supports it will make. Some support options definitely would not have worked, by the way, namely, lines.
But, basically, supports are basically impossible to remove. I pried at it and rubbed with sandpaper but my vague hope that the supports might pop off were badly misplaced. The thing looks like a button. But fortunately the plug part was shallow so I just super-glued the thing onto my pergola and it looks like the real deal at a glance. In fact it looks better.
Mailbox plate
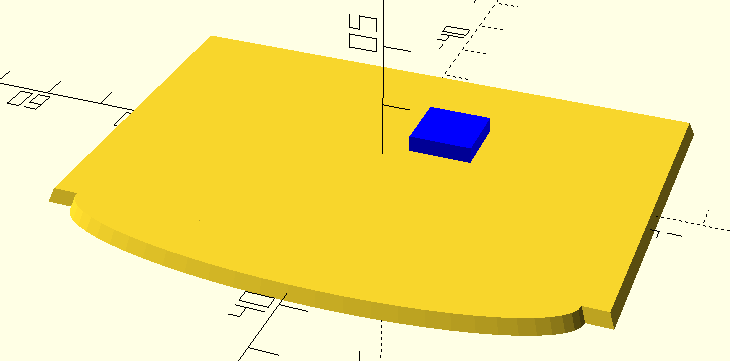
If I thought I was a whiz at this sort of thing, this mini-project proved me wrong. I was going to add a semi-circle at the bottom of a rectangle, and work through Pythagorean’s theorem to find the unknowns. I was just spending too much time and really, eye-balling it was more effective. And a more desirable shape was an ellipse. So the good ones make these parameterized models, but I find it’s not so easy and when you want to bang out some custom part quickly, it may not make sense.
There was a gaping hole in my mailbox post. This plate covers it up. Here’s the code.
What techniques I learned from this simple mailbox plate project
I used the linear extrude method for the first time. Very useful. So, shapes like squares and cirlces (or ellipses) extruded along the Z-asix. My first effort did not include the bump-out, which I needed as a spacer. So I learned that you don’t always have to re-level after every print and this was the first time the dang filament didn’t break on me between print jobs – because I acted within 24 hours. I even re-used the blue tape. All real time-savers. So I used the 3D printer the way you imagine it to be – just there to print stuff, not to worry about fixing all the time.
I also had a reject – a first attempt without the bumpout. I kept it to test the breaking strength. So the thickness is 2.3 mm, right (I have to get calipers!)? It’s pretty darn strong. I was probably applying 10 pounds of force and it was hardly budging. Each layer prints orthogonally and a piece this thin is solid material.
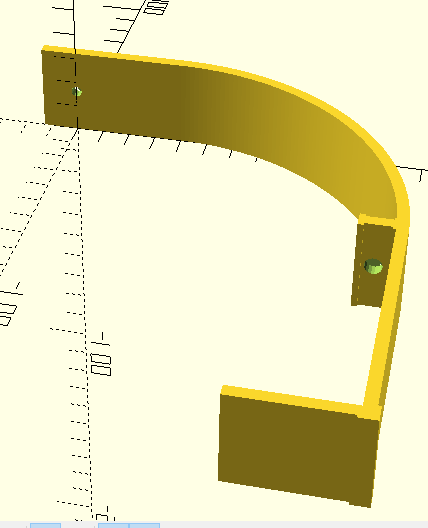
Bird feeder C ring
I have a backyard bird feeder which hangs too low – I fear a squirrel could jump to it. So I wanted a way to shorten the hang by winding the wire around something that will stay. So I designed a C-shaped ring thing. works great. This is a first time for me for using a rotate extrude. I had to chop off the bottom of the ring so that I would not need supports. This is my shortest code yet, and least paraemerized. It’s just easier when you want to knock something out quickly…
// DrJ 7/2020. Parameters in mm
// min facet angle and facet size (mm)
$fa = 1.1; $fs = 1.1; $fn=100;
difference(){
rotate_extrude(angle=348,convexity = 10)
translate([20, 0, 0])
circle(r = 6);
translate([0,0,-9]) cube([60,60,10],center=true);
}
Bird feeder C ring
This is my first piece with interior fill. The bird feeder is pretty heavy – 10 pounds. but this little C ring is plenty strong for entwining the hanging string.
Curved TV bracket
The code
// DrJ 12/2019. Parameters in mm
z=32;
thickness=4;
a=38; // 1 1/2" - the lip
S=174; //6 7/8" - how far to come out
m=127; // 5 3/32" - hole to TV edge
n=13; // 1/2" extra beyond screw hole
o=m-S/2;
r=S/2;
Rscrewhole=2;
t=85; //restraint y from inner claw
u=S-thickness-t;
Rthole=3;
xt=12;
reinforce=10;
bigthick=thickness+1;
// min facet angle and facet size (mm)
$fa = 1.1; $fs = 1.1;
difference() {
translate([-n,0,0])
cube([n+o,thickness,z]);
translate([0,thickness,z/2]) rotate([90,0,0]) cylinder(r=Rscrewhole,h=thickness*3);
}
// staircase
translate([m-a,-S,0])
cube([a+thickness,thickness,z]);
translate([m,-S,0])
cube([thickness,S/2,z]);
//reinforce the corner
shim=bigthick-thickness;
translate([m-shim,-S-shim,0]) cube([bigthick+shim,shim,z]);
translate([m,-S-shim,0]) cube([bigthick,bigthick+shim,z]);
// curved section
translate([o,-S/2,0]) {
rotate_extrude(angle=90,convexity=10){ translate([S/2,0,0]) square([thickness,z]);}
}
// restraint
translate([m-xt,-u,0]) {
difference() {
cube([xt,thickness,z]);
translate([2*Rthole,thickness,z/2]) rotate([90,0,0]) cylinder(r=Rthole,h=thickness*3);
}}
//thickeners
translate([m-1,-u-1,0]) cube([2,thickness+2,z]);
translate([m-xt,-u-1,0]) cube([2,thickness+2,z]);
Waffle tile
// DrJ 12/2019. Parameters in mm
barthick=6;
shaveamount=2;
shavedthick=barthick-shaveamount;
lip=7;
lipandextra=lip+3;
radius=1.5;
z=7;
ytot=190;
//y=ytot-2*lip;
y=ytot;
nbars=5;
xstep = (ytot-2*lipandextra-nbars*barthick)/(nbars-1) + barthick;
// min facet angle and facet size (mm)
$fa = 1.1; $fs = 1.1;
difference() {
wafer();
// half material for tesselation
halfbar=barthick/2;
translate([halfbar,-y+lip,-1]) wafer(z+2);
translate([-halfbar,y-lip,-1]) wafer(z+2);
translate([y-lip,halfbar,-1]) wafer(z+2);
translate([-y+lip,-halfbar,-1]) wafer(z+2);
// holes
ydis=lipandextra-lip/2;
echo (ydis);
translate([0,-ydis,z/2]) rotate([0,90,0]) cylinder(r=radius,h=y);
translate([0,y-2*lipandextra+ydis,z/2]) rotate([0,90,0]) cylinder(r=radius,h=y);
translate([lipandextra-ydis,0,z/2]) rotate([-90,0,0]) cylinder(r=radius,h=y);
translate([y-lipandextra+ydis,-1,z/2]) rotate([-90,0,0]) cylinder(r=radius,h=y);
// shave off material by sitting cube on top
cubelen=y-2*(lipandextra+shavedthick);
translate([lipandextra+shavedthick,shavedthick,z-shaveamount]) cube([cubelen,cubelen,z]);
}
//rotate([-90,0,0]) cylinder(r=radius,h=y);
module wafer(zwafer=z){
for(xs=[lipandextra:xstep:ytot]){
translate([xs,-lipandextra,0]) bar(zwafer);
}
translate([y,0,0]) rotate(90) {for(xs=[0:xstep:ytot]){
translate([xs,0,0]) bar(zwafer);
}
}
}
module bar(zheight=z) {
cube([barthick,y,zheight]);
}
Router platform
Router platform
This router platform consists of two separate printing jobs. Here are the bird legs. Note these openscad files contain a bunch of unneeded detritus.
A friend printed this for me using PETG material. It seems pretty nice. And my design works really well for my singular purpose (shown in picture below).
// DrJ 6/2021. Parameters in mm
barthick=6;
legthick=6;
height=94; // approximate – remeasure
apart=50;
innerringD=32; // 1.25″
boost=innerringD/2 + 4;
fromend=7; // for topbar screwholes
nexthole=26.2;
topbarlen=38 + nexthole/2 + fromend; // 1.5″ back from rod center
radius=1.8; // works with m3 screws
// min facet angle and facet size (mm)
$fa = 1.1; $fs = 1.1;
//lie the whole thing flat for printing with no supports
rotate([0,90,0]){
zigzag(); translate([0,apart,0]) zigzag();
crossbar();
gallows();
}
I need a thingy to loosen my birdfeed. I had been using an allen wrench, but I lost it and it wasn’t quite the right shape – nowhere to put it. So I designed this simple fit-for-purpose object. It features a hook for hanging, a rounded corner and a flat bottom for easy printing.
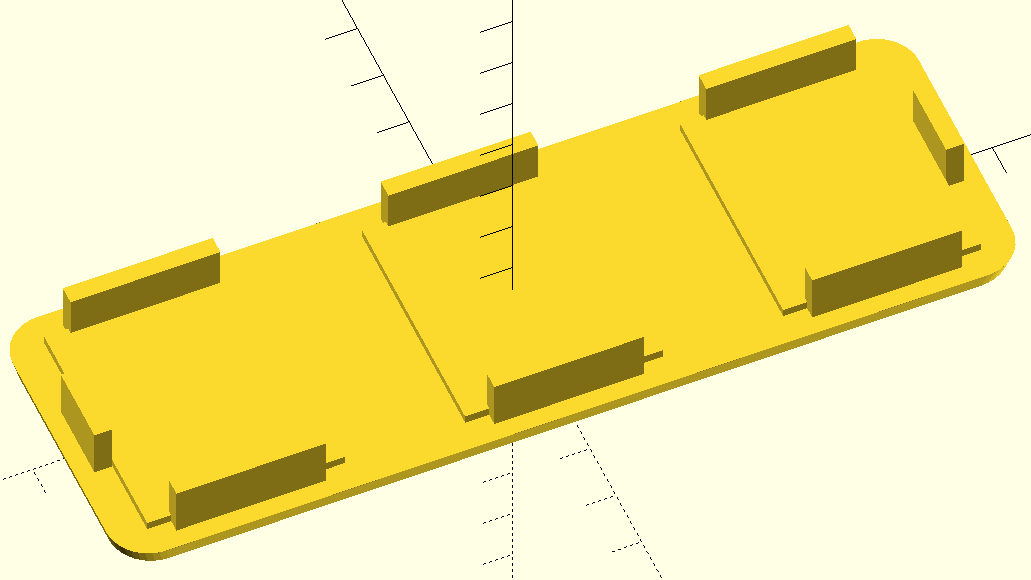
This thing keeps my utensil holder from sliding within the drawer. I began by using chatgpt, or I should say trying to use. It was helpful to get me started, but more complicated things seemed to totally elude it.
// DrJ 1/2025. Parameters in mm
// Dimensions of the box
width = 110;
length = 150;
thickness = 3;
epsilon = 1;
brace_angle = 30;
brace_z = 20;
spacing = 53; // Spacing between the lines in the criss-cross pattern
line_thickness = 4; // Thickness of the lines in the pattern
leg_height = 53; // Height of the legs
leg_width = 6; // Width of the legs
leg_length = 10; // Length of the legs
//width = width – line_thickness; // correction
side_height = thickness; // Height of the side leg
side_width = width; // Width of the side leg
side_length = 10; // Length of the side leg
module leg() {
// Create a leg
cube([leg_width, leg_length, leg_height]);
}
module shave_cube(){
translate([0,-epsilon,thickness]){cube([side_width,side_length+2*epsilon,leg_height]);};
}
module leg_brace() {
// Create a leg brace
difference(){
translate([0,0,-brace_z]){rotate(a=[0,brace_angle,0]){cube([leg_width, leg_length, leg_height]);}};
shave_cube();
}
}
module side_leg() {
// Create a leg
cube([side_width, side_length, side_height]);
}
module criss_cross_pattern() {
for (i = [0 : spacing : length]) {
// Horizontal lines
translate([0, i, 0]) {
cube([width, line_thickness, thickness]);
}
}
for (i = [0 : spacing : width]) {
// Vertical lines
translate([i, 0, 0]) {
cube([line_thickness, length, thickness]);
}
}
}
// Create the criss-cross box
criss_cross_pattern();
// Add legs at two corners
translate([0, 0, -(leg_height-thickness)]) {
leg(); // Leg at the bottom-left corner
}
translate([0, length – leg_length, -(leg_height-thickness)]) {
leg(); // Leg at the bottom-left corner
}
// add stronger sides
translate([0, 0, 0]) {
side_leg(); // Leg at the bottom-left corner
}
translate([0, length – side_length, 0]) {
side_leg(); // Leg at the bottom-left corner
}
leg_brace();
translate([0,length – side_length,0]){
leg_brace();}
//shave_cube();
I had a friend print it out who does 3d printing as a service.
Some learnings from my experience
If you have problems with your USB stick
I should be embarrassed to admit this, but I’m otherwise tech-savvy so I am not. I put my orange USB stick 9flash drive) into my computer in order to copy over my latest GCode, and the computer made that typical Windows double sound which shows you’ve plugged something into a USB port, but the F: drive would not show up no matter what I did.
Well, turns out I had left the micro SD card behind in the printer! It has to be inserted into the back of the USB stick. Duh, right? In my defense I hadn’t printer anything in months and I simply forgot the setup.
How frequently should the print bed be leveled?
I thought maybe you have to do it before every print job. But you see that TV bracket up above? I had to print out five of them as I continued to refine the design (and I was really trying to not be wasteful!). They take five – six hours to print. i would simply print one out after another without re-leveling the print bed. No issues. I did have to press down on my painters tape, which bubbled up where there was contact with the PLA.
Does printing thin, vertical pieces work OK?
Yes. I did a 3 mm thick piece about 1 1/2″ high – no issues. Then I switched to 4 mm and also no problems of course.
How large can holes be in the “wrong” (Z) dimension?
Again in that TV bracket I had holes of 4 mm and 6 mm in diameter in the z dimension. Do the rules about “bridges” apply? I have no idea, but they’re fine. Not smooth as glass, but sub-millimeter deviations from perfection. Definitely fine for passing screws through. maybe just a tad rougher in appearance than the surrounding surfaces. At some point as you scale up the radius, the top of a hole is a bridge, so failure has to occur, just thinking through this logically.
Do the belts and motors of the printer get loose after a few prints and after a year?
Not really. Mine still printed great after a year and light usage. I still can’t believe the quality that comes out in fact.
How uniformly does the print bed have to be leveled?
We all know you pull a paper through between nozzle and print bed and adjust until you meet resistance. What if one corner has more resistance than the rest? I would say it doesn’t matter. If you’ve ripping up the paper – that’s an issue, but the difference between a little resistance and more resistance should not be sweated. On my printer I assert it’s impossible to make the bed completely uniform. Also see the tip below about the print bed. I also recommend not to move the printer after leveling the print bed. I believe it will deform from even small movement. But I have printed six 50 gram jobs, one after the other, without re-leveling, which is great. The sixth job, however, totally failed. But see the next tip about watching the beginning of the print job.
Watch the beginning of the print job
I have lost prints twice. First time it was that the heated filament printed out a bit, but then the stuff on the print bed just started to be dragged around. Second time I printed a long, narrow piece. One end of it started to curl upwards like a water ski. I re-adjusted the print bed level no that side. Those things are going happen at the beginning of the print job if it happens at all. So watch the beginning of the printing for proper printing.
Are there differences in PLA?
Surprisingly, the answer seems to be definitely yes. The white PLA which came with printer seems to be much more fragile than the black stuff I bought (see link below). I’ve been told that the filament becomes brittle with exposure to air. With my white PLA it kept breaking off after a few days between print jobs, no matter what I did! The black stuff, by contrast, did not break off once! Not even when left in place for months!
Does PLA deform under tension or sheer forces?
See that C ring above? That was printed with the black stuff and used outside. It stretched noticeably over the course of the summer. perhaps a combination of the summer heat plus the tension. But whatever, the printed parts feel nice and rigid when first printed out, but they will permanently deform! Engineering plastics could probably address that, but I have no practical experience with them.
How to yank the finished print away off the print bed
You’ll break your fingernails trying to pry your printed masterpieces off the print bed. Of course I use blue painters tape over the print bed. I have settled on a technique where I use a needle nose pliers. Pull firmly while simultaneously pushing down with the other hand on the print bed. All my stuff, which is pretty dimensional, pops right off like that, and the tape is ready for another print – it is not ruined.
Thin strips are padded
With my setup, anyway, my thin vertical pieces are consistently coming out over the specified dimensions by about .5 mm. This overage can be important in a lot of projects. Similarly, holes are produced smaller than the specified dimensions, though I don’t know by how much, but seems to be in the range .5 – 1.0 mm. I know these things because I bought an inexpensive caliper!
How many parts of this type can you get from your spool of PLA?
Most (all?) of my projects involve fourth-grade level math, honestly. No algebra. Maybe a tiny hint of trigonometry. Anywya, Cura tells you how much PLA your printout will use. My TV bracket was around 50 grams. This is painfully obvious, but just to put it out there, do the math. If you have a 1 KG (= 1000 grams) spool of PLA and each thing you’re printing takes, e.g., 50 grams, you can print 1000 grams / (50 grams per piece) = 20 pieces.
Filament stops coming out in the middle of the printing – what to do?
I am currently suffering from this. I think my nozzle is too full of crud. I have no idea how to fix it (no time to research this).
I don’t enjoy tinkering with my finicky 3D printer. Is there a “3D printing as a Service” business?
I have been told there is not. People send ridiculously impossible things to print, expecting miracles. Perhaps someone will soon solve this issue (by qualifying all print jobs beforehand)? OK. There is a very commercial service. But it is way too expensive for hobbyist. Probably a minimum of $100. See the references for another suggestion.
Time-saving tip for leveling the print bed
My anet a8 prints great once I get it set up. But that setup – boy is it a pain. Leveling the print bed being the absolute worst. Because, if you follow their advice and adjust each corner, well, they don’t seem to stay and you end up reversing your direction on the screws of the print bed. Or you’ll get one corner and then the corner you had just done will be off.
But think about it. For these small jobs, it only has to be level at the center. So, the heck with it, just make sure when you drag a piece of paper with the nozzle at the center that it has a bit of resistance, and don’t stress about what happens at the four distant corners. You will maintain your sanity this way.
Conclusion I found the missing piece after printing this piece out, as luck would have it. BUT, then I found another place, right against the side of the house, that was never covered, but could have been. So I slapped my printed part there – it worked great!
A subsequent bolt hole cover project revealed that supports are nasty and basically impossible to remove. Yet the design was such that the thing worked anyways with a little superglue.
A plate to cover a hole in the mailbox post came next, and then a ring with a little slit for my bird feeder. Those two use an extrusion method.
You have to render your model or else export to STL does absolutely nothing, and also does not show an error, except in the console, which you may not be showing.
I learned quite a lot doing the curved TV bracket project. I shared my learnings.
References and related
3D-printing-as-a-service
I’ve recently met the guy behind this Etsy shop: GizmosWidgets – Etsy and I have used his service, which is great, very personable. And only $5 for basic stuff! And he used PETG which he explained would be stronger than alternatives such as PLA.
If you are lucky enough to live in Oak Creek, Wisconsin, or really anywhere in Milwaukee county, you have it! And it’s really cheap – $.05/gram. https://oakcreeklibrary.org/3d-printer/
As for the rest of us, we have to encourage our local libraries and community colleges to get with the program. I think it’s coming, so make sure your interest is known.
This 3D printing service may be the most suitable for engineerss: https://www.sculpteo.com/ . My modest wine bottle holder would cost $27 in their cheapest configuration (SLS plastic PA12). But at least their service looks really legit and gives you lots of options.
The program I use to generate my designs is Openscad. It’s free and still being actively developed. It’s great if you know a bit of scripting and a bit of geometry. https://openscad.org/
But there are a lot of other great 3D designs out there beyond just Thingiverse. This site introduces lots of these resources with example pictures from printed models.
Setup
I decided to run an X Server on my Windows 10 laptop. I only need it for Cognos gateway configuration, but when you need it, you need it. Of course an X Server listens on port 6000, so hosts outside of your PC have to be able to initiate a TCP connection to your PC with destination port 6000. So that port has to be open. The software I use for the X Server is Mobatek XTerm.
Here is the Powershell command to disable the block of TCP port 6000.
The Powershell window needs to be run as administrator. The change is permanent: it suffices to run it once.
Conclusion
And, because inquiring minds want to know, did it work? Yes, it worked and I could send my cogconfig X window to my Mobatek X Server. I had to look for a new Window. It was slow.
In a lot of ways, the last few years have seen 3D printing “going mainstream,” so to speak. People are no longer astonished by the sheer capabilities of the technology, and we’re getting more accustomed to seeing stories about one interesting product or another having been 3D printed. People are also gaining more access to 3D printing; in some cases the costs of the devices have fallen, though we have posted about building one’s own 3D printer as well, and this is another option some savvier consumers are embracing.
The process of getting to this point, at which 3D printing is at least somewhat familiar to a lot of people, has been complex, fascinating, and enjoyable. But now that 3D printing is mainstream, what’s next for the technology? It’s hard to say with certainty, but we can look to a few current trends and developments and predict some of the ways that the technology could become more popular still.
Further Understanding Of Capabilities
Even if people are no longer astonished by what 3D printing can do in general, further understanding of the full range of the technology’s capabilities is likely to come with time. In a sense, the initial learning curve concerned the basic concept – that a 3D object could be printed into empty space by a machine according to a digital design. Next, people will inevitably come to learn about all of the various twists that can exist within that broad concept. For instance, people will get more used to the idea that 3D printers can create metal objects, and not only work with plastics; people will come to be familiar with larger 3D printers on a scale that can create car parts, or potentially even small homes and urban planning features. Ideas like these don’t necessarily fall into the most basic understanding of 3D printing, but they’ll inevitably be more widely understood in short time.
Combination With Other Advanced Manufacturing
This is perhaps more of a concern for large companies and significant manufacturing operations. Nevertheless, it’s a good bet that the next few years will see more people come to understand 3D printing as one of a few advanced manufacturing methods that can contribute to the creation of modern products. The technology’s most noteworthy counterpart may be injection molding, which is not as new, but which has grown vastly more sophisticated and capable. This is basically a process by which a given material is heated and molded to fit a shape, such that it hardens in that shape and becomes a final product. Fictiv describes injection molding processes as being ideal for design validation or for higher volume production, which largely conveys the idea that they are similarly useful to 3D printing. The truth though is that people may come to realize that the combination of the two technologies can benefit entire industries. For instance, there are some cases in which prototypes and early models are created via 3D printing (a better process for trial-and-error), and then used as the basis for large-scale molding efforts to design product lines.
3D-Printed Food
The very notion of 3D-printed food can sound absurd on its face. It reads very much like something from a science fiction novel or a fantasy film in which food can simply be created, and there are no more resource shortages. Amazingly enough though, while it’s not all quite so glossy and miraculous as the sci-fi version, 3D-printed food has become a reality. Hackaday explains how 3D-printed food can work in a piece written just last year, and the concept is actually surprisingly straightforward. Basically, pastes made of organic materials and broken down ingredients (such as, in one example, peas and seaweed) can be printed into mock versions of regular food items (in the same example, a steak). The same article acknowledges that taste isn’t necessarily ideal just yet, but the very idea of creating food products from a mishmash of edible materials is exciting. It’s a starting point for what could be a massive step toward addressing food shortages, and it’s likely to become one of the main topics driving further interest in 3D printing.
Command-Based Projects
This is something we don’t hear all that much about yet, but which could make for a significant step particularly with regard to consumer 3D printing. Singularity Hub took a look at 3D printing innovations we might see in the next five years or so and introduced this idea in an interesting way, stating that “hey” will become the “most frequently used command in design engineering.” Specifically the suggestion is that we’ll be able to say, “Hey 3D printer, design me a new pair of shoes” in much the same way we ask Alexa or Siri to make shopping lists or tell us the weather. If this proves to be true, it’s likely we’ll see a significant spike in consumer 3D printer purchases. For that matter, it could significantly change much of the retail industry.
Ultimately one of the cool things about 3D printing is that we’re all still figuring it out. It likely has countless applications we have’t yet considered or imagined. The suggestions here are grounded in current trends and speculation though, and should play a significant role in keeping this technology fresh and interesting.
Intro
Today I came across a simple but useful tool which runs on Windows systems that will help determine if a remote host is listening on a particular port. I wanted to share that information.
The details PortQry is attractive because of its simplicity, plus, it is supported and distributed by Microsoft themselves. The help section reads like this:
PortQry version 2.0
Displays the state of TCP and UDP ports
Command line mode: portqry -n name_to_query [-options]
Interactive mode: portqry -i [-n name_to_query] [-options]
Local Mode: portqry -local | -wpid pid| -wport port [-options]
Command line mode:
portqry -n name_to_query [-p protocol] [-e || -r || -o endpoint(s)] [-q]
[-l logfile] [-sp source_port] [-sl] [-cn SNMP community name]
Command line mode options explained:
-n [name_to_query] IP address or name of system to query
-p [protocol] TCP or UDP or BOTH (default is TCP)
-e [endpoint] single port to query (valid range: 1-65535)
-r [end point range] range of ports to query (start:end)
-o [end point order] range of ports to query in an order (x,y,z)
-l [logfile] name of text log file to create
-y overwrites existing text log file without prompting
-sp [source port] initial source port to use for query
-sl 'slow link delay' waits longer for UDP replies from remote systems
-nr by-passes default IP address-to-name resolution
ignored unless an IP address is specified after -n
-cn specifies SNMP community name for query
ignored unless querying an SNMP port
must be delimited with !
-q 'quiet' operation runs with no output
returns 0 if port is listening
returns 1 if port is not listening
returns 2 if port is listening or filtered
Notes: PortQry runs on Windows 2000 and later systems
Defaults: TCP, port 80, no log file, slow link delay off
Hit Ctrl-c to terminate prematurely
examples:
portqry -n myserver.com -e 25
portqry -n 10.0.0.1 -e 53 -p UDP -i
portqry -n host1.dev.reskit.com -r 21:445
portqry -n 10.0.0.1 -o 25,445,1024 -p both -sp 53
portqry -n host2 -cn !my community name! -e 161 -p udp
...
PortQry version 2.0
Displays the state of TCP and UDP ports
Command line mode: portqry -n name_to_query [-options]
Interactive mode: portqry -i [-n name_to_query] [-options]
Local Mode: portqry -local | -wpid pid| -wport port [-options]
Command line mode:
portqry -n name_to_query [-p protocol] [-e || -r || -o endpoint(s)] [-q]
[-l logfile] [-sp source_port] [-sl] [-cn SNMP community name]
Command line mode options explained:
-n [name_to_query] IP address or name of system to query
-p [protocol] TCP or UDP or BOTH (default is TCP)
-e [endpoint] single port to query (valid range: 1-65535)
-r [end point range] range of ports to query (start:end)
-o [end point order] range of ports to query in an order (x,y,z)
-l [logfile] name of text log file to create
-y overwrites existing text log file without prompting
-sp [source port] initial source port to use for query
-sl 'slow link delay' waits longer for UDP replies from remote systems
-nr by-passes default IP address-to-name resolution
ignored unless an IP address is specified after -n
-cn specifies SNMP community name for query
ignored unless querying an SNMP port
must be delimited with !
-q 'quiet' operation runs with no output
returns 0 if port is listening
returns 1 if port is not listening
returns 2 if port is listening or filtered
Notes: PortQry runs on Windows 2000 and later systems
Defaults: TCP, port 80, no log file, slow link delay off
Hit Ctrl-c to terminate prematurely
examples:
portqry -n myserver.com -e 25
portqry -n 10.0.0.1 -e 53 -p UDP -i
portqry -n host1.dev.reskit.com -r 21:445
portqry -n 10.0.0.1 -o 25,445,1024 -p both -sp 53
portqry -n host2 -cn !my community name! -e 161 -p udp
...
The PortQry “install” consisted of unzipping a ZIP file, so, no install at all, and no special permissions needed, which is a plus in my book.
nmap
Of course there is always nmap. I never really got into it so much, but clearly you can go nuts with it. One advantage is that it is available on linux and MacOS as well. But in my opinion it is a heavy-handed install.